DataHub基本介绍
阿里云实时数据分发平台DataHub是流式数据(Streaming Data)的处理平台,提供对流式数据的发布(Publish),订阅(Subscribe)和分发功能,让您可以轻松构建基于流式数据的分析和应用。DataHub服务可以对各种移动设备,应用软件,网站服务,传感器等产生的大量流式数据进行持续不断的采集,存储和处理。您可以编写应用程序或者使用流计算引擎来处理写入到DataHub的流式数据,比如:实时web访问日志、应用日志、各种事件等,并产出各种实时的数据处理结果,比如:实时图表、报警信息、实时统计等。
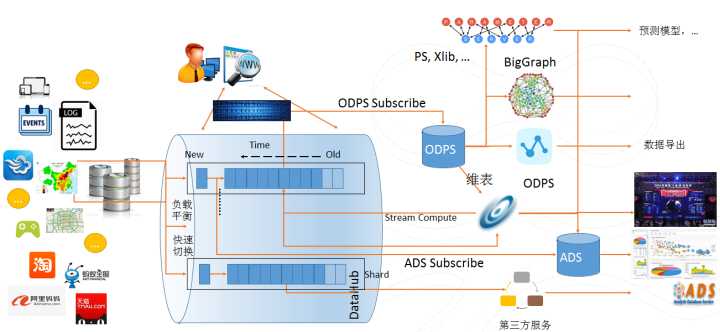
DataHub服务基于阿里云自研的飞天平台,具有高可用,低延迟,高可扩展,高吞吐的特点。DataHub与阿里云流计算引擎StreamCompute无缝连接,您可以轻松使用SQL进行流数据分析。
DataHub服务也提供分发流式数据到各种云产品的功能,目前支持分发到MaxCompute(原ODPS),OSS等。
系统整体功能图,如下所示:

产品优势
- 高吞吐
最高支持单主题(Topic)每日T级别的数据量写入,每个分片(Shard)支持最高每日8000万Record级别的写入量。
- 实时性
通过DataHub ,您可以实时的收集各种方式生成的数据并进行实时的处理,对您的业务产生快速的响应。
- 易用性
- DataHub提供丰富的SDK包,包括C++, JAVA, Pyhon, Ruby, Go等语言;
- DataHub服务也提供Restful API规范,您可以用自己的方式实现访问接口。
- 除了SDK以外,DataHub还提供一些常用的客户端插件,包括:Fluentd,LogStash,Flume等,您可以使用这些客户端工具往DataHub中写入流式数据。
- DataHub同时支持强Schema的结构化数据和无类型的非结构化数据,您可以自由选择。
- 高可用
- 服务可用性不低于99.999%。
- 规模自动扩展,不影响对外服务。
- 数据持久性不低于99.999%。
- 数据自动多重冗余备份。
- 动态伸缩
每个主题(Topic)的数据流吞吐能力可以动态扩展和减少,最高可达到每主题256000 Records/s的吞吐量。
- 高安全性
- 提供企业级多层次安全防护,多用户资源隔离机制。
- 提供多种鉴权和授权机制及白名单、主子账号功能。
应用场景
DataHubR作为一个流式数据处理服务,结合阿里云众多云产品,可以构建一站式的数据处理服务。
流计算StreamCompute
StreamCompute是阿里云提供的流计算引擎,提供使用类SQL的语言来进行流式计算。DataHub 和StreamCompute无缝结合,可以作为StreamCompute的数据源和输出源。
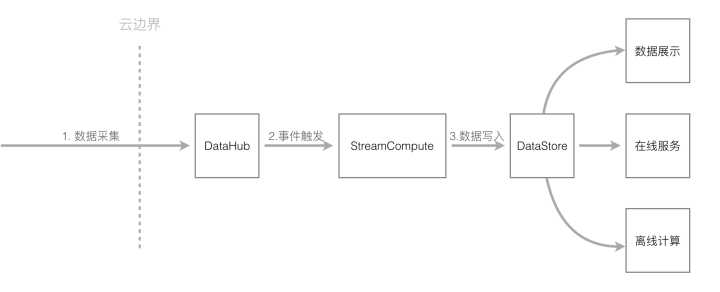
流处理应用
您可以编写应用订阅DataHub中的数据,并进行实时的加工,把加工后的结果输出。
您可以把应用计算产生的结果输出到DataHub中,并使用另外一个应用来处理上一个应用生成的流式数据,来构建数据处理流程的DAG。
流式数据归档
您的流式数据可以归档到MaxCompute(原ODPS)中,通过创建DataHub Connector,指定相关配置,即可创建将Datahub中流式数据定期归档的同步任务。
提示(新用户无需关注):
- 目前 老版本MaxCompute DataHub已处于待下线状态,不再接入新用户。使用MaxCompute DataHub的用户可以参考之前的使用文档。
- 自2016年11月21日起,新版本DataHub正式公测上线。
- 新老DataHub服务迁移手册。
公测约束与说明
DataHub免费公测期间,资源有限,将会不定时执行下述回收策略
- 凡15天无数据写入的Topic将有可能被系统临时关闭通道,再次使用需要重新申请资源。
- 凡15天未无数据同步的DataConnector将有可能会被系统临时暂停任务,再次使用需要重启任务。
关于阿里云DataHub详细内容:
阿里云DataHub使用教程
(DataHub服务是阿里云提供的流式数据(Streaming Data)服务,它提供流式数据的发布 (Publish)和订阅 (Subscribe)的功能,让您可以轻松构建基于流式数据的分析和应用。)
阿里云大学官网(阿里云大学 - 官方网站,云生态下的创新人才工场)