大话数据结构读书笔记(七)-图
第七章、图
1、图:顶点的有穷非空集合和顶点之间边的集合组成:G(V,E)。V顶点集,E边集。无向图:图中每条边都没有方向。
有向图:图中每条边都有方向。无向边:边是没有方向的,写为(a,b)有向边:边是有方向的,写为有向边也成为弧;开始顶点称为弧尾,结束顶点称为弧头。
简单图:不存在指向自己的边、不存在两条重复的边的图。
无向完全图:每个顶点之间都有一条边的无向图。
有向完全图:每个顶点之间都有两条互为相反的边的无向图。
稀疏图:边相对于顶点来说很少的图。 稠密图:边很多的图。
权重:图中的边可能会带有一个权重,为了区分边的长短。 网:带有权重的图。
度:与特定顶点相连接的边数。
出度、入度:对于有向图的概念,出度表示此顶点为起点的边的数目,入度表示此顶点为终点的边的数目。
环:第一个顶点和最后一个顶点相同的路径。
简单环:除去第一个顶点和最后一个顶点后没有重复顶点的环。
连通图:任意两个顶点都相互连通的图。
极大连通子图:包含竟可能多的顶点(必须是连通的),即找不到另外一个顶点,使得此顶点能够连接到此极大连通子图的任意一个顶点。
连通分量:极大连通子图的数量。
强连通图:此为有向图的概念,表示任意两个顶点a,b,使得a能够连接到b,b也能连接到a 的图。
生成树:n个顶点,n-1条边,并且保证n个顶点相互连通(不存在环)。
最小生成树:此生成树的边的权重之和是所有生成树中最小的。
AOV网:结点表示活动的网。
AOE网:边表示活动的持续时间的网。
2、图的存储结构
1)邻接矩阵:图的邻接矩阵存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中的边或弧的信息。
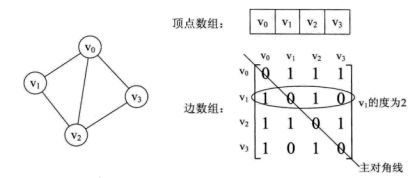

由邻接矩阵可以容易的判断两定点有误边,及边的度及有向图的出度和入度。n个顶点和e条边的无向网图的创建,时间复杂度为O(n + n2 + e),其中对邻接矩阵Grc的初始化耗费了O(n2)的时间。
2)邻接表:图中顶点用一个一维数组存储,当然,顶点也可以用单链表来存储,不过,数组可以较容易的读取顶点的信息,更加方便。图中每个顶点vi的所有邻接点构成一个线性表,由于邻接点的个数不定,所以,用单链表存储,无向图称为顶点vi的边表,有向图则称为顶点vi作为弧尾的出边表。
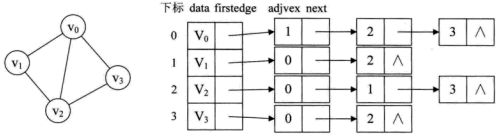
顶点表的各个结点由data和firstedge两个域表示,data是数据域,存储顶点的信息,firstedge是指针域,指向边表的第一个结点,即此顶点的第一个邻接点。边表结点由adjvex和next两个域组成。adjvex是邻接点域,存储某顶点的邻接点在顶点表中的下标,next则存储指向边表中下一个结点的指针。对于带权值的网图,可以在边表结点定义中再增加一个weight的数据域。对于n个顶点e条边来说,很容易得出是O(n+e)。
3)、十字链表:重新定义顶点表结点结构
| data | firstin | firsout |
其中firstin表示入边表头指针,指向该顶点的入边表中第一个结点,firstout表示出边表头指针,指向该顶点的出边表中的第一个结点。
重新定义边表结构
| tailvex | headvex | headlink | taillink |
其中,tailvex是指弧起点在顶点表的下表,headvex是指弧终点在顶点表的下标,headlink是指入边表指针域,指向终点相同的下一条边,taillink是指边表指针域,指向起点相同的下一条边。如果是网,还可以增加一个weight域来存储权值。

十字链表的好处就是因为把邻接表和逆邻接表整合在一起,这样既容易找到以v为尾的弧,也容易找到以v为头的弧,因而比较容易求得顶点的出度和入度。
4)邻接多重表: 重新定义边表节点
| ivex | ilink | jvex | jlink |
则邻接表是一个很好的选择,但是如果我们要在邻接表中删除一条边,则需要删除四个顶点(因为无向图)。在邻接多重表中,只需要删除一个节点,即可完成边的删除,因此比较方便。多应用于对边的操作

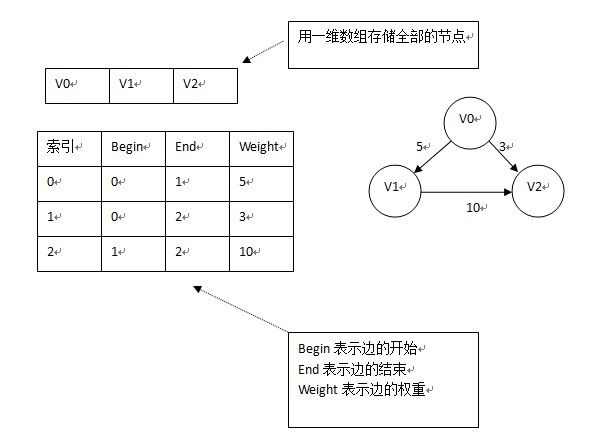
5)边集数组:两个一位数组组成,一个存储顶点信息,另个存储边信息。每个边组数据元素有一个边的起点下标begin、终点下标end和权值weight。
3、图的遍历:图的遍历和树的遍历类似,希望从图中某一顶点出发访遍图中其余顶点,且使每一个顶点仅被访问一次,这一过程就叫图的遍历。对于图的遍历来说,如何避免因回路陷入死循环,就需要科学地设计遍历方案,通过有两种遍历次序方案:深度优先遍历和广度优先遍历。
深度优先遍历:也有称为深度优先搜索,简称DFS。其实,就像是一棵树的前序遍历。它从图中某个结点v出发,访问此顶点,然后从v的未被访问的邻接点出发深度优先遍历图,直至图中所有和v有路径相通的顶点都被访问到。若图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中的所有顶点都被访问到为止。
public class DFSearch {
public void searchTraversing(GraphNode node, List visited) {
// 判断是否遍历过
if (visited.contains(node)) {
return;
}
visited.add(node);
System.out.println("节点:" + node.getLabel());
for (int i = 0; i < node.edgeList.size(); i++) {
searchTraversing(node.edgeList.get(i).getNodeRight(), visited);
}
}
} 广度优先遍历:
public class BFSearch {
/**
* 广度优先搜索
*/
public void searchTraversing(GraphNode node) {
List visited = new ArrayList(); // 已经被访问过的元素
Queue q = new LinkedList(); // 用队列存放依次要遍历的元素
q.offer(node);
while (!q.isEmpty()) {
GraphNode currNode = q.poll();
if (!visited.contains(currNode)) {
visited.add(currNode);
System.out.println("节点:" + currNode.getLabel());
for (int i = 0; i < currNode.edgeList.size(); i++) {
q.offer(currNode.edgeList.get(i).getNodeRight());
}
}
}
}
}
4、最小生成树:
prim算法:基本思想:假设N=(V,{E})是联通网,TE是N上的最想生成树中的变得集合。算法从U={u0}(u0属于V),TE={}开始,重复执行下述操作:在所有的u属于U,v属于V-U的边(u,v)属于E中找到一条代价最小的边(u0,v0)并入集合TE,同事v0并入U,直至U=V为止。此时TE中必有n-1条边,则T=(V,{TE}) 为N的最小生成树。下面是以邻接矩阵存储形式的算法。
public void prim(){
int cost[] = new int[9];
int pre[] = new int[9];
for(int i=0;iKruskal算法:克鲁斯卡尔算法从另一个途径求网中的最小生成树。假设联通网N=(V,{E}),则令最小生成树的厨师状态为只有n个顶点而无边的非连通图T=(V,{}),途中每个顶点自称一个连通分量。在E中选择代价最小的边,若该边衣服的顶点落在T中不同的连通分量上,则将此边加入到T中,否则舍去此边而选择下一条最小的边。以此类推,直至T中所有的顶点都在同一连通分量上为止。
public class Kruskal {
private Set points=new HashSet();
private List treeEdges=new ArrayList();
public void buildTree(){
MapBuilder builder=new MapBuilder();
TreeSet edges=builder.build();
int pointNum=builder.getPointNum();
for(Edge edge:edges){
if(isCircle(edge)){
continue;
}else{//没有出现回路,将这条边加入treeEdges集合
treeEdges.add(edge);
//如果边数等于定点数-1,则遍历结束
if(treeEdges.size()==pointNum-1){
return;
}
}
}
}
public void printTreeInfo(){
int totalDistance=0;
for(Edge edge:treeEdges){
totalDistance+=edge.getDistance();
System.out.println(edge.toString());
}
System.out.println("总路径长度:"+totalDistance);
}
private boolean isCircle(Edge edge){
int size=points.size();
if(!points.contains(edge.getStart())){
size++;
}
if(!points.contains(edge.getEnd())){
size++;
}
if(size==treeEdges.size()+1){
return true;
}else{
points.add(edge.getStart());
points.add(edge.getEnd());
return false;
}
}
} 5、最短路径:用于计算一个节点到其他所有节点的最短路径。是典型的最短路径路由算法,用于计算一个节点到其他所有节点的最短路径。主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止。Dijkstra算法能得出最短路径的最优解,但由于它遍历计算的节点很多,所以效率低。时间复杂度O(n^2)。
邻接矩阵存储:
public void Dijkstra(){
int distance[] = new int[9];
int pre[] = new int[9];
boolean finished[] = new boolean[9];
finished[0] = true;
for(int i=0;i<9;i++){
distance[i] = g1.adjMatrix[0][i];
}
int k = 0;
for(int i=1;i<9;i++){
int min = 65536;
for(int j=0;j<9;j++){
if(!finished[j]&&distance[j]Fload算法:多源最短路径,是一种动态规划算法。时间复杂度:O(n^3),空间复杂度:O(n^2)。
public void floyd(Graph1 g) {
int i, j, k;
int length = g.vertex.length;
int dist[][] = new int[length][length];
int pre[][] = new int[length][length];
for (i = 0; i < g.vertex.length; i++) {
for (j = 0; j < g.vertex.length; j++) {
pre[i][j] = j;
dist[i][j] = g.adjMatrix[i][j];
}
}
for (i = 0; i < length; i++) {
for (j = 0; j < g.vertex.length; j++) {
for (k = 0; k < g.vertex.length; k++) {
if (dist[i][j] > dist[i][k] + dist[k][j]) {
dist[i][j] = dist[i][k] + dist[k][j];
pre[i][j] = pre[i][k];
}
}
}
}
System.out.println();
} 6、拓扑排序:有向图中,图中的顶点代表活动(子工程),图中的有向边代表活动的先后关系,即有向边的起点的活动是终点活动的前序活动,只有当起点活动完成之后,其终点活动才能进行。通常,我们把这种顶点表示活动、边表示活动间先后关系的有向图称做顶点活动网,简称AOV网。对一个有向无环图G进行拓扑排序,是将G中所有顶点排成一个线性序列,使得图中任意一对顶点u和v,若边(u,v)∈E(G),则u在线性序列中出现在v之前。
7、关键路径:用顶点表示事件,弧表示活动,弧上的权值表示活动持续的时间的有向图叫AOE网。他的性质有只有在某顶点所代表的事件发生后,从该顶点出发的各有向边所代表的活动才能开始。只有在进入某一顶点的各有向边所代表的活动都已经结束,该顶点所代表的事件才能发生。表示实际工程计划的AOE网应该是无环的,并且存在唯一的入度过为0的开始顶点和唯一的出度为0的完成顶点。关键路径:从源点到汇点的路径长度最长的路径叫关键路径。事件发生的最早时间etv即顶点vk的最早发生时间,对应是事件最晚发生时间ltv。活动最早开工时间ete即弧ak最早发生时间。算法:输入e条弧,建立AOE-网的存储结构。
2、拓扑排序,并求得ve[]。从源点V0出发,令ve[0]=0,按拓扑有序求其余各顶点的最早发生时间ve[i]。如果得到的拓扑有序序列中顶点个数小于网中顶点数n,则说明网中存在环,不能求关键路径,算法终止。否则执行步骤3。3、拓扑逆序,求得vl[]。从汇点Vn出发,令vl[n-1] = ve[n-1],按逆拓扑有序求其余各顶点的最迟发生时间vl[i]。
4、求得关键路径。根据各顶点的ve和vl值,求每条弧s的最早开始时间e(s)和最迟开始时间l(s)。若某条弧满足条件e(s) = l(s),则为关键活动。为了能按逆序拓扑有序序列的顺序计算各个顶点的vl值,需记下在拓扑排序的过程中求得的拓扑有序序列,这就需要在拓扑排序算法中,增设一个栈,以记录拓扑有序序列,则在计算求得各顶点的ve值之后,从栈顶到栈底便为逆拓扑有序序列。
2、拓扑排序,并求得ve[]。从源点V0出发,令ve[0]=0,按拓扑有序求其余各顶点的最早发生时间ve[i]。如果得到的拓扑有序序列中顶点个数小于网中顶点数n,则说明网中存在环,不能求关键路径,算法终止。否则执行步骤3。3、拓扑逆序,求得vl[]。从汇点Vn出发,令vl[n-1] = ve[n-1],按逆拓扑有序求其余各顶点的最迟发生时间vl[i]。
4、求得关键路径。根据各顶点的ve和vl值,求每条弧s的最早开始时间e(s)和最迟开始时间l(s)。若某条弧满足条件e(s) = l(s),则为关键活动。为了能按逆序拓扑有序序列的顺序计算各个顶点的vl值,需记下在拓扑排序的过程中求得的拓扑有序序列,这就需要在拓扑排序算法中,增设一个栈,以记录拓扑有序序列,则在计算求得各顶点的ve值之后,从栈顶到栈底便为逆拓扑有序序列。
public class Grph_CriticalPath
{
Graph_AdjList adjList;
Stack T = new Stack();
int ve[];
int vl[];
final int max = 10000;
public Grph_CriticalPath(Graph_AdjList adjList) //图的存储结构是用的邻接表
{
this.adjList = adjList;
int length = adjList.vetexValue.length;
ve = new int[length];
vl = new int[length];
for(int i=0;i S = new Stack();
S.push(0);
int count = 0;
while(!S.isEmpty())
{
int j = S.pop();
T.push(j);
count++;
Graph_AdjList.ArcNode p = null;
for(p = adjList.vetex[j].firstArc; p!=null ;p = p.next)
{
int k = p.adjvex;
if(--adjList.degree[k]==0)
{
S.push(k);
}
if(ve[j]+p.weight>ve[k])
{
ve[k] = ve[j]+p.weight;
}
}
}
if(count