MySQL 源码分析 v2.0
第一节 mysql编译
(一).参考
https://blog.jcole.us/innodb/
https://www.cnblogs.com/zengkefu/p/5674503.html
https://dev.mysql.com/doc/internals/en/getting-source-tree.html
https://www.cnblogs.com/-xep/p/8045213.html
https://www.jianshu.com/p/1cc29d893cfc
https://www.aliyun.com/jiaocheng/357678.html
https://www.cnblogs.com/songxingzhu/p/5713553.html
https://blog.csdn.net/yi247630676/article/details/80352655
https://blog.csdn.net/vipshop_fin_dev/article/details/79688717
http://blog.51cto.com/wangwei007/2300217?source=dra
http://ourmysql.com/archives/1090
http://www.orczhou.com/index.php/2012/11/mysql-innodb-source-code-optimization-1/
http://ourmysql.com/archives/1282
http://ourmysql.com/archives/1277
http://ourmysql.com/archives/1305
<深入理解mysql>
https://dev.mysql.com/doc/internals/en/selects.html
https://www.cs.usfca.edu/~galles/visualization/BTree.html
https://blog.csdn.net/u012935160/column/info/innodb-zerok
http://hedengcheng.com/?p=293
https://www.cnblogs.com/f-ck-need-u/archive/2018/05/08/9010872.html#auto_id_12
https://www.cnblogs.com/xpchild/tag/MySQL/
https://blog.csdn.net/bohu83/column/info/25114
https://bbs.huaweicloud.com/blogs/4fddbe400f1c11e89fc57ca23e93a89f
https://www.cnblogs.com/shijingxiang/articles/4743324.html
http://mysqlserverteam.com/re-factoring-some-internals-of-prepared-statements-in-5-7/
cmake -DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DMYSQL_UNIX_ADDR=/tmp/mysql.sock -DDEFAULT_CHARSET=utf8 -DDEFAULT_COLLATION=utf8_general_ci -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_ARCHIVE_STORAGE_ENGINE=1 -DWITH_BLACKHOLE_STORAGE_ENGINE=1 -DWITH_PARTITION_STORAGE_ENGINE=1 -DENABLED_LOCAL_INFILE=1 -DMYSQL_USER=_mysql -DMYSQL_TCP_PORT=3306 -DMYSQL_DATADIR=/data/mysql -DDOWNLOAD_BOOST=1 -DWITH_BOOST=/Users/feivirus/Documents/software/boost
./mysqld --initialize-insecure --user=mysql --datadir=/data/mysql --explicit_defaults_for_timestamp=true
在/usr/local/mysql/bin/下面
sudo ./mysqladmin -uroot -pxxx shutdown
在/usr/local/mysql/support-files/mysql.server下
sudo ./mysql.server start
(二).带着问题看源码
1.为什么where column_name is null 不走索引,is not null走索引
2.一个页内四条记录,id为1,2,3,4,如果2和3删除了,各2k,现在有个3k的进来,是裂变,加新页吗?不整理内存碎片?
3.索引文件的格式,内存里面和文件里面是否一致,非叶节点的存储格式,blog,text字段长的存储格式也是存储在不同的页?
4.explain中的rows和filtered rows数字怎么来的
5.in和or性能上有区别吗?
6.页面内部插入记录,插入10,20,再插入15,页面内部顺序是如何处理的,20向后?链表处理?内存碎片如何处理
7.mysql对sql语句优化了哪些内容?
8.group by找到多条记录之后,是怎么选择一条记录出来的?随机还是有排序?
9.sql优化时的代价估算,具体怎么估算?
10.innodb的定时任务去刷新磁盘,怎么刷新的?
11.limit 1000,100为什么要查出1100条数据,再选出100条出来?不直接选择100条数据
12.select * from t where a=x and b=x order by c. 如果你的表有1000w行 你怎么建索引优化这个sql
13.如何判断sql单表查询用哪个索引,索引的界限,条件,索引下推的过程.区分unique key,主键,普通的key,无索引
14.单表查询在使用的索引上加什么锁,锁哪些记录,会不会死锁
15.多表join过程
16.limit 10000,10时,如果用索引,会不会先顺序查询10000条,再取10条.加上 order by呢.
17.mvcc下,执行update,delete的过程
18.单表下,执行计划代价cost是怎么估算的.
第二节.mysql源码模块
一.mysql源码结构
(一)mysql-server根目录下:
1.client mysql命令行客户端工具
2.dbug 调试工具
3.Docs 一些说明文档
4.include 基本的头文件
5.libmysql 创建嵌入式系统的mysql客户端程序API
6.libmysqld mysql服务器的核心级API文件(8.0没了?)
7.mysql-test mysql的测试工具箱
8.mysys 操作系统API的大部分封装函数和各种辅助函数
9.regex 处理正则表达式的库
10.scripts 一些基于shell脚本的工具
11.sql 主要源代码
12.sql-bench 一些性能测试工具(8.0没了)
13.ssl一些ssl的工具和定义(8.0改为mysys_ssl)
14.storage 插件式存储引起的代码
15.strings 各种字符串处理函数
16.support-files 各种辅助文件
17.vio 网络层和套接层的代码
18.zlib 数据压缩工具(8.0移到了utilities)
二.mysql启动
(一)mysql main()启动过程
(二)mysql select查询过程
如下图断点:
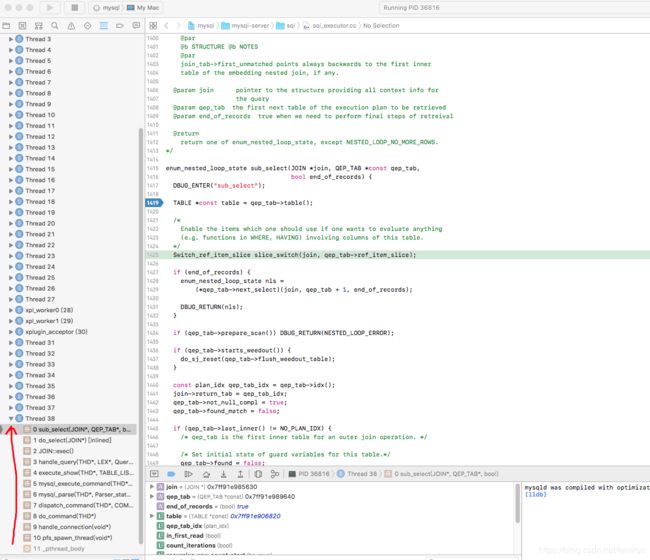
依次需要经过连接处理,sql语法解析,sql优化,sql执行(存储引擎)四层处理.需要经过选取(限制),投影,连接处理.
依次经过的Sql接口(handle_connection()->do_command()->dispatch_command()),查询解析器(mysql_parse()->parse_sql()->yyparse()->mysql_execute_command()(为优化做准备)->handle_select()),查询优化器(join.prepare()->join.optimize()->join.exec()),查询执行器(do_select()->sub_select()->join.result.send_eof())
从栈底到栈底的每个方法阶段的功能简要描述:
sql连接接口阶段:
1.在mysqld.cc文件中,mysql启动后,进入mysqld_main().在该main()方法中进入setup_conn_event_handler_threads().通过socket_conn_event_handler()进入socket_conn_event_handler(),在该方法中死循环调用connection_event_loop(),进入Connection_handler_manager::process_new_connection(),进入add_connection(). 在文件connection_hanlder_per_thread.cc中通过Per_thread_connection_handler::add_connection()方法,调用mysql_thread_create创建线程,线程的运行函数为connection_handler_per_thread.cc文件中的handle_connection().
2.在handle_connection中,通过while循环调用sql_parse.cc中的do_command(),循环的作用是从用户输入的多个命令中依次选择一个命令去执行.在do_command()中,调用Protocol_classic::get_command(),进入Protocol_classic::parse_packet()读取一个数据包,解析为command命令,command命令有COM_QUERY、COM_FIELD_LIST、COM_STMT_EXECUTE等。在在do_command()中继续调用sql_parse()文件中的dispatch_command().在dispatch_command()中包含了各种类型的command怎么处理的switch case。比如select的进入case COM_QUERY.先alloc_query()复制线程线程过来的查询命令。再进入sql_parse.cc文件中的mysql_parse()方法,开始sql语法解析.
sql语法解析阶段:
3.在mysql_parse()中,主要完成三个工作。检查查询缓存里是否有以前执行过的某个查询。调用词法解析器(通过parse_sql()方法),调用查询优化器(通过mysql_execute_command()方法).
4.依次进入sql_parse.cc中的parse_sql(),进入sql_class.cc中的THD::sql_parser(),进入MYSQLparse().MYSQLparse是个宏定义,为#define yyparse MYSQLparse.这时进入yacc的sql_yacc.cc文件中的语法解析器函数yyparse()开始语法解析.解析器基于sql_yacc.yy文件通过yacc生成.Mysql的词法解析器没有用flex,自己编写的。语法解析器用的Bison.
5.在mysql_parse()中继续调用sql_parse()文件中的mysql_execute_command()方法,为sql优化做准备.在该方法中,通过switch case为各种sql命令优化做准备.如果是select查询,进入case SQLCOM_SELECT,进入Sql_cmd_dml::execute()方法.在execute()方法中,先调用precheck()查询是否有权限,然后调用open_tables_for_query()打开要查询的表,然后调用lock_tables()锁定相关的表,然后调用Sql_cmd_dml::execute_inner(),进入真正的查询优化.
sql查询优化阶段:
在Sql_cmd_dml::execute_inner()方法中,先进入sql_optimizer.cc文件中的JOIN::optimize(),再进入sql_executor.cc文件中的JOIN::exec()开始查询执行器。
sql查询执行器:
在sql_executor.cc文件中的JOIN::exec()中.先调用send_result_set_metadata()生成查询标题,再进入sql_executor.cc中的do_select()生成查询结果.在do_select()中调用sub_select().在sub_select()中,先判断是否是最后一条记录.然后while循环每次读取一条记录。后面详情见后面的"查询执行处理器"一节.
第三节 存储引擎,函数,命令
一.关键类
sql/handler.h下的struct handlerton,class handler,比如选择inno引擎,create table时进入storage/innobase/handler/ha_innobase::create()方法.insert into语句时进入ha_innobase::write_row().
二.用户自定义函数
调用命令create function,实现函数的so库。参考例子在sql/udf_example.cc中。
三.本机函数
修改代码在lex.h,item_create.cc,item_str_func.cc中。常用函数都在lex.h中。
四.新的sql命令
修改sql_yacc.yy,sql_parse.cc.所有系统支持的命令在enum_sql_command枚举类中。命令处理在sql_parse.cc的mysql_execute_command()中。
第四节.SQL接口
第五节.查询解析器(Lex-YACC/Bison)
一.词法分析
在sql_yacc.cc文件中定义
#define yyparse MYSQLparse
#define yylex MYSQLlex
#define yyerror MYSQLerror
#define yylval MYSQLlval
所以词法分析在sql_lex.cc的MYSQLlex()方法中.调用堆栈如图
进入lex_one_token(),在find_keyword()中调用Lex_hash::get_hash_symbol()查找关键字.关键字是根据lex.h中的symbols[]数组调用gen_lex_hash.cc生成lex_hash.h中的符号数组sql_keywords_and_funcs_map[].词法分析解析到SELECT后,执行find_keyword去找是否是关键字,发现SELECT是关键字,于是给yacc返回SELECT_SYM用于语法分析。note:如果我们想要加关键字,只需在sql_yacc.yy上面添加一个%token xxx,
然后在lex.h里面加入相应的字符串和SYM的对应即可。依次取出token,比如sql语句为"select * from user",token依次为select,*,from,user,返回的为token的id号.*的id号
为42.这个id号在sql_yacc.h中定义,比如#define SELECT_SYM 748.已经分析和没有分析过的语句都放在Lex_input_stream结构的lip变量中.在lex_one_token()依次判断读入的符号,解析状态,比如"select @@version_comment limit 1;"语句,进入case MY_LEX_SYSTEM_VAR状态,解析MY_LEX_IDENT_OR_KEYWORD,就是"version_comment".
二.语法分析
入口为sql_yacc.cc文件中的yyparse()方法.
语法分析文件在sql_yacc.yy中.以"select @@version_comment"为例。进入lex_one_token()方法中的case MY_LEX_SYSTEM_VAR后.
(一).Item对象
可以是一个文本字符串/数值对象,表的某一列(例如,select c1,c2 from dual…中的c1,c2),一个比较动作,例如c1>10,一个WHERE子句的所有信息.
(二).mysql语法树处理过程
在sql_yacc.yy中,如果是select查询语句,进入query处理逻辑。具体格式如下
query:
| verb_clause END_OF_INPUT
{
/* Single query, not terminated. */
YYLIP->found_semicolon= NULL;
}
;
select:
select_init
{
LEX *lex= Lex;
lex->sql_command= SQLCOM_SELECT;
}
;
如果是where语句的,处理如下
where_clause:
/* empty */ { Select->where= 0; }
| WHERE
{
Select->parsing_place= IN_WHERE;
}
expr
{
SELECT_LEX *select= Select;
select->where= $3;
select->parsing_place= NO_MATTER;
if ($3)
$3->top_level_item();
}
;
以select * from users where id = 1 语句为例,
生成的语法树大致如下左图,右图为mysql内部的存储结构.
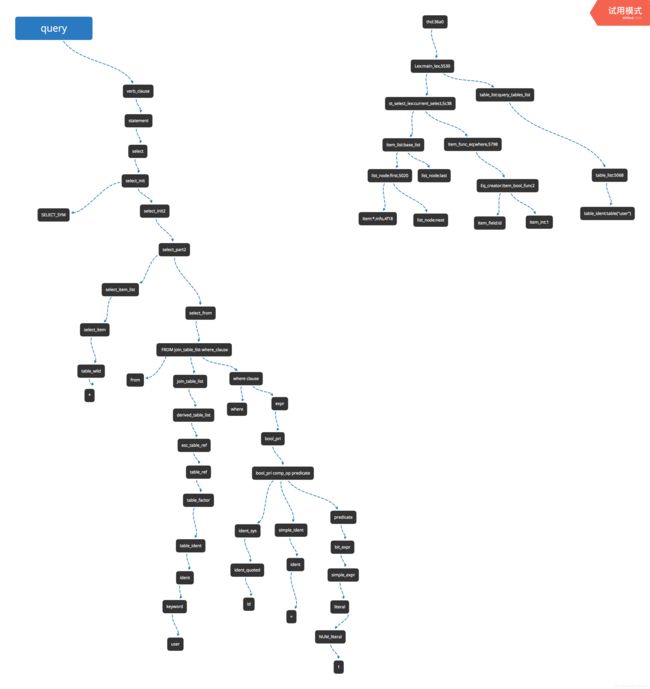
以select * from user where id = 1为例,每次读入一个token,要考虑移进还是规约.通过yylex()方法得到的yychar是id号,该id号数字在sql_yacc.h中定义.
1.lex_one_token,读入"select"->select_sym token->规约到sql_yacc.yy 的select_part2:
2.读入*号,依次规约到sql_parse.yy中的select_item_list:
3.读入from,依次规约到sql_parse.yy中的select_part2:
4.读入"user",依次规约到table_factor:->keyword_sp:->keyword:->ident:
5.读入"where",依次规约到simple_ident_q:->opt_use_partition:->opt_table_alias:->opt_key_definition:->table_factor:->
join_table:->esc_table_ref:->derived_table_list:->join_table_list:->where_clause:->IDENT_sys
6.读入"="
。。。
sql语法树的状态切换过程如下,数字为状态转换表的编号,编号顺序为上面左图从树叶到树根的语法解析过程,括号内为bison规约的mysql中的非终结符:
1127(select_part2),1137,读入*,1149(select_item_list),读入from,1128(select_part2),读入user,1444(table_factor),2326(keyword_sp),1988(keyword,只是匹配到,没有动作),1979(ident),读入where,1966(simple_ident_q),1441(opt_use_partition),1518(opt_table_alias),1480(opt_key_definition),1477,1481,1445(table_factor),1421(join_table),1412,1415(esc_table_ref),1417(derived_table_list),1414(join_table_list),
1523(where_clause),1973(IDENT_sys),读入=号,1978(ident),1955(simple_ident),1223,1206,1191,1177,1215(comp_op),读入数字1,1942(NUM_literal),1933(literal),1229,读入end_of_input,1206,1191,1175(,创建eq_creator),1171,1524(where_clause),1530,1525,1541,1552(opt_limit_clause),1588,1135(select_from),1132,1144,1129,1125(select_init2),2548(union_clause),1126,1119,1118(select),50,8,5(query).
(三).Mysql语法树存储结构
以select * from user where id = 1为例,如上图右侧图所示.Mysql语句中的*为投影的列,存储在thd->main_lex.current_select->item_list中,列表中的每一项为一个list_node. where条件存储在thd->main_lex.current_select->where对象中。where为级联结构.
处理过程如下,比如处理到"="时的,堆栈如下:
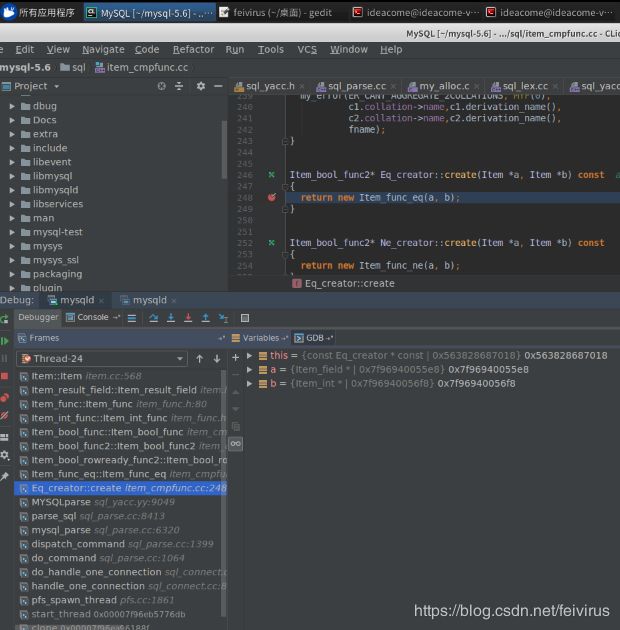
mysql为"="创建一个Eq_creator类标识,如前面图所示,它存储在thd->main_lex.current_select->where对象中.where类型为
item_func_eq类.它依次继承Item_bool_rowready_func2,Item_bool_fun2,如下图所示
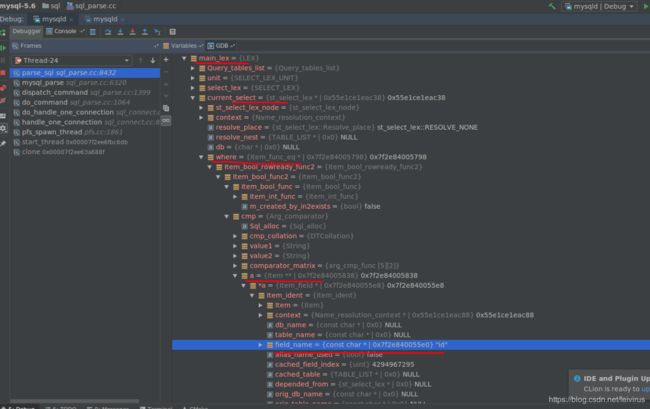
在Item_bool_fun2类中有cmp成员,类型为Arg_comparator,如下图
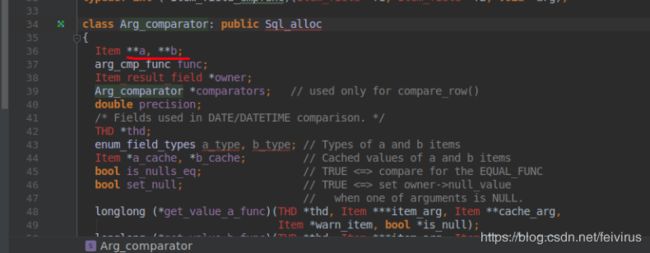
存储了=运算符的两边的表达式.
第六节 查询优化器
一.优化器架构
分为子查询优化,视图重写,谓词重写,条件化简,外连接消除,嵌套连接消除,语义优化,多表连接优化等。
(一).优化准备阶段JOIN::prepare()
主要处理子查询的冗余子句,优化IN,ANY,ALL,EXISTS命令.
(二).优化入口JOIN::optimize().
依次调用1.simplify_joins(),做连接消除,把外连接转换为内连接,比如两个表通过外键关联,没有null行,一一对应.
2.然后调用optimize_cond()做条件优化,优化where字句,比如常量传播,比如where a=b and b =40,如果a上有索引,优化成 a= 40 and b =40,可以走索引.
3.调用optimize_cond()做having中的条件优化.
4.调用optimize_fts_limit_query做单表查询中,没有where子句,有一个order by子句,有一个limit 子句,
5.调用opt_sum_query做count(*),min(),max()优化.替换其中的常量.
6.调用make_cond_for_table()
7.调用make_join_statistics()确定多表连接的顺序,策略.
8.调用make_outerjoin_info()填充连接外键信息
9.调用substitue_for_best_equal_field()优化等值表达式,去掉重复的等式.
10.调用make_join_select()确定join的连接方式,使用哪些索引.具体见下面的"三.多表连接优化".
11.调用order_with_src()优化distinct语句
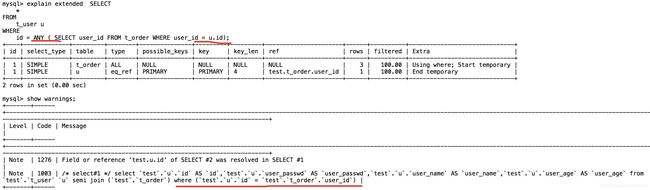
二.子查询优化
(一).exits优化
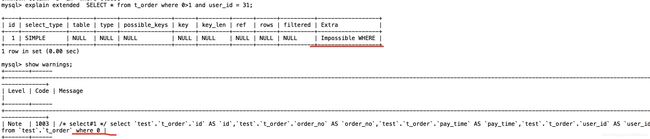
测试语句 select * from user u1 where exists(select * from user u2 where u2.id=1);
会优化成 select * from user u1 where 1;
入口optimze_cond(),进入internal_remove_eq_conds.进入eval_const_cond先执行u2.id=1的子查询.进入Item_exists_subselect::val_init()进入subselect_single_select_engine::exec()执行子查询.又进入JOIN::optimize().执行完子查询后exists返回true,
三.多表连接优化
入口是make_join_statistics().主要逻辑在方法上有清晰的注释.
(一).for循环初始化每个表连接用的数据结构
(二).如果是外连接,分析表之间的依赖关系
(三).根据依赖关系做半连接上拉(pull out semi-join tables)操作.
(四).确定连接的外表和内表之间有没有相关关系
(五).如果是标量子查询,做查询,得到标量子查询的数据.
(六).计算每个表需要匹配的行数
(七).如果可以使用索引,计算where 条件的区间内返回的条数.
(八).判断是否有impossibel where 或者on
(九).调用Optimize_table_order().choose_table_order()确定连接策略.
1.判读是否是straight_join().
2.调用greedy_search()做贪婪算法判断.
3.调用fix_semijon_strategies()确定半连接策略
(十).调用get_best_combination()从确定好的连接策略中创建执行计划.
四.谓词优化
(一).not优化

(二).or 优化
(三). any 优化
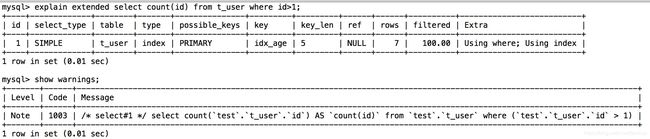
(四).count() 聚集函数优化
第七节 查询执行处理器
一.执行处理器架构
入口在sql_executor.cc文件中的JOIN::exec()中.先调用send_result_set_metadata()生成查询标题,再进入sql_executor.cc中的do_select()生成查询结果.在do_select()中调用first_select(),进入sub_select().在sub_select()中
1.先判断是否是最后一条记录,主要用于嵌套查询或者join时的子查询中递归返回.在这个判断进入next_select()时是嵌套或者join的最后一层.
2.调用read_first_record时,如果是第一次查询该表,进入records.cc文件中的init_read_record()创建读表的READ_RECORD结构,初始化要读取的表的信息,判断是走索引还是普通全部扫描. 调用handler::ha_rnd_init为扫描做innodb的初始化准备.进入ha_innobase::rnd_init(),后续详情见后面"innodb引擎的初始化".在init_read_record中继续调用handler::extra_opt做一些额外处理.比如检查事务是否存在.然后调用handler::ha_rnd_next扫描记录.进入rr_sequential,开始innodb扫描记录.
3.在sub_select()中继续通过while循环遍历一条条记录,调用read_record()读取记录.每次读取一条记录后,在sub_select的while循环内进入evaluate_join_record()做where 后面的条件判断,如下图
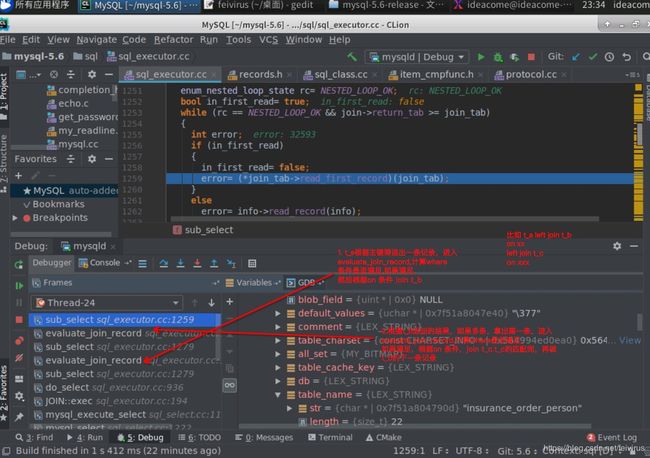
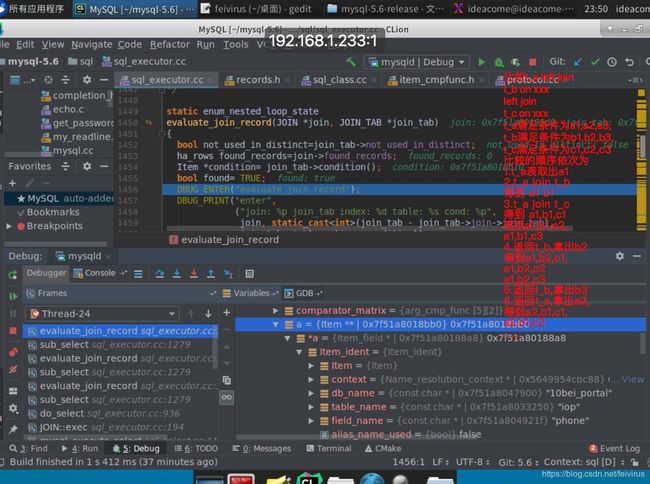
4.在evaluate_join_record中先取出当前表相关的where的条件,判断取出的记录是否满足where条件.判断是否满足是进入每种判断条件的Item::val_int()方法.每一种判断条件都继承Item类.如果当前记录满足where条件,进入JOIN_TAB::next_select()方法.在这里进入下一层left join 的sub_select(),开始下一层join的判断。如果当前是最后一层join,就发送满足条件的结果给客户端.
基本的join过程总结如下:
比如 SELECT * from a
left join b
on a.id = b.a_id
left join c
on c.a_id = a.id
where c.phone like '13%' and b.money>20 and a.total > 20;
sql优化后,执行如下:
for(id in b) {
取出第一条记录为id=14215,对应的a_id为74417
判断是否满足b.money>20 .满足则进入下面for
for(a_id in a) {
取出a_id为74417的记录,假设只有一条
判断是否满足a.total > 20, 满足则进入下面for
for(a_id in c) {
取出a_in为74417的记录,有三条,for 循环执行三次
判断是否满足 c.phone like '13%'
输出记录
}
}
}
第八节 innodb引擎
一.innodb的存储结构
(一).表空间
innodb的的表空间(tablespace)分为段(segment),区(extent),页(page),页目录内的槽(slot),行组成.InnoDB有一个共享表空间ibdata1,如果启用innodb_file_per_table,则每张表数据单独放一个表空间内,undo信息,系统事务信息,二次写缓冲还是放在共享表空间内.一个表空间即一个B+树,分为两个段,数据段(叶节点),索引段(内节点).区由64个连续的页组成,每个页大小为16KB,每个区就是1MB.每个段开始时,先有32个碎片页,碎片页用完后再每次以区为单位申请,即64个连续页。初始化表空间内有4个页,按照页号从0到3分别是File Space Header页,Insert Buffer Bitmap页,File Segment inode页,page level为0(代表叶节点,只有一页,叶节点就是根节点).外带两个空闲页.如图

(二).段
(三).区
(四).页
页类型有数据页(B-tree Node),Undo页,系统页,事务数据页,插入缓冲位图页,插入缓冲空闲列表页,Uncompressed BLOG Page,Compressed BLOG Page等.
页由File Header,Page Header, Infimun + Supremum Records,User Records(用户数据),Free Space,Page Directory,File Trailer组成.如下图


1.File Header.
占用38个字节.存放比如checksum,表空间的页偏移,上一页的偏移,最后被修改的日志的LSN,页类型.
2.Page Header.
记录页的状态信息,共56个字节,存放页目录槽数,堆中第一个可用空间的指针(page_heap_top,对于没有插入数据记录的页面来说,38+56+13+13=120字节处,长度为2,偏移为4,可用空间的最小位置),堆中记录数等,空闲链表的指针,已删除记录的字节数,最后插入方向,page_level(0代表叶节点),文件段的首指针.
3.Infimun + Supremum记录.
Infimun存储记录比页内键值都小的值,Supremum是存储大的值,用于限定记录边界.各占13个字节.
4.Page Directory
5.File Trailer 8个字节的FIL_PAGE_END_LSN,前四个字节是校验和,后四个字节和File_Header中的checksum相同,保证页的完整性.
(五).行
行分为Compact和Redundant两种存储格式.Compact格式如下图:

变长字段长度列表 | NULL标志位 | 记录头信息 | 列1数据 | 列N数据...
列长小于255字节,用1个字节表示。大于255个字节,用两个字节表示,两个字节16位,2的16次方为65535,即varchar的最大长度.NULL标志位表示行中是否有NULL值,占1个字节.记录头信息占用5个字节,表示是否删除,记录数,记录类型,16位的下一记录的相对偏移.6个字节的事务id列,7个字节的回滚指针列,如果没有主键,还有6个字节的RowID列.后面跟着行的具体数据.如果该行数据溢出,则新创建BLOB页存储,本行只记录前768字节,后面跟着行溢出页的偏移.
二.引擎初始化
入口为ha_innodb.cc文件中的ha_innobase::rnd_init().进入change_active_index()修改扫描主键.
三.扫描记录
入口handler::ha_rnd_next().进入pfs.cc文件中的start_table_io_wait_v1()方法.进入ha_innod.cc文件中的rnd_next()方法读取记录.
1.先调用ha_statistic_increment做统计分析.
2.判断是否是读取第一条记录,如果是第一条进入index_first()。不是第一条记录进入general_fetch()方法.在general_fetch()方法中先进入srv0conc.cc文件中的srv_conc_enter_innodb()方法中创建io线程,处理事务.然后调用row_search_for_mysql()读取记录.入参是个buf指针.
3.在row_search_for_mysql()方法中,读索引,判断是否是compact压缩格式,读取事务id,确定页面offset.判断索引是否损坏等.获取一个s-latch锁.判断读取inc还是desc方向.判断是否是聚集索引,匹配模式是否是ROW_SEL_EXACT.调用mtr_start开始事务.判断是否要恢复索引位置.跳到next_rec标记处,进入btr_pcur_move_to_next()方法,在该方法中判断是不是页面中用户记录的最后一条,如果是则返回。不是最后一条,进入btr_pcur_move_to_next_on_page()->page_cur_move_to_next移动游标到页面的下一条记录.进入page0page.ic文件中的page_rec_get_next()获取页内下一条记录的offset,在row_search_for_mysql()中调用btr_pcur_get_rec()根据游标获取记录.在row_search_for_mysql继续调用rec_get_next_offs获取下一条记录的偏移.在row_search_for_mysql中经过一系列调用,然后调用row_sel_store_mysql_rec把innodb的row格式转换成mysql得到record格式.进入row0sel.cc文件中的row_sel_store_mysql_field_func()方法.进入row_sel_field_store_in_mysql_format_func()方法.for循环遍历所有列字段,根据字段是int,varchar等转换字段格式.在row_search_for_mysql()中继续调用mtr_commit()提交事务.
4.页内通过槽搜索记录代码在page_cur_search_with_match()中.
四.读取表
在使用命令"use test"切换数据库时,进入sql_base.cc文件中的open_normal_and_derived_tables()方法.如下图
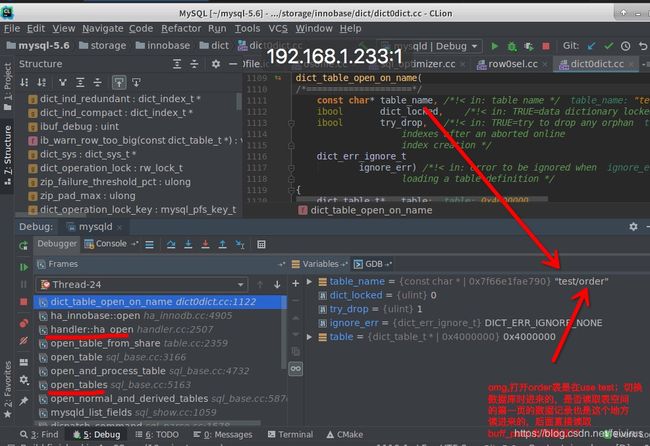
依次进入open_tables()->open_table_from_share(),进入handler.cc文件中的handler::ha_open()方法,依次进入ha_innobase::open()->dict0dict.cc文件中的dict_table_open_on_name()->dict_load_table()处理如下:
1.获取"sys_tables"系统表,获取系统表的索引,获取系统表的ID,N_COLS,TYPE,MIX_LEN,SPACE列.调用btr_open_on_user_rec()读取表的游标。进入btr_pcur_init()初始化游标.
2.进入dict_load_table_low载入表.从sys_tables中获取user表的信息.调用dict_mem_table_create()创建user表的表空间.
3.在dict_load_table中,继续调用innobase_format_name转换表名为mysql的格式.调用fil_space_for_table_exists_in_mem()填充table space.
五.内存管理
(一).页内插入记录,申请空间调用方法page0page.cc文件中的page_mem_allc_heap()方法.具体原理参考上面innodb引擎介绍的页一节.
(二).页面碎片管理
新建buffer pool页面,将碎片页面的数据插入新页面,记录从小到大复制过去.原来的buffer pool页面释放掉.
(三).索引页面的回收
(四).页面内记录删除.检查当前页面剩余记录数,如果只剩下一条,就从B+树中释放,回收页面.
六.插入记录
入口是ha_innobase::write_row().首先把接收到的record记录转为内部的tuple,索引元组格式,最后转成row格式.
1.进入innobase_srv_conc_enter_innodb()开始事务.进入row_insert_for_mysql()->row_ins_step()->row_ins()->row_ins_index_entry_step()->row_ins_index_entry()->row_ins_clust_index_entry()->row_ins_clust_index_entry_low->btr_cur_optimistic_insert->进入page_cur_tuple_insert()方法.如下图:
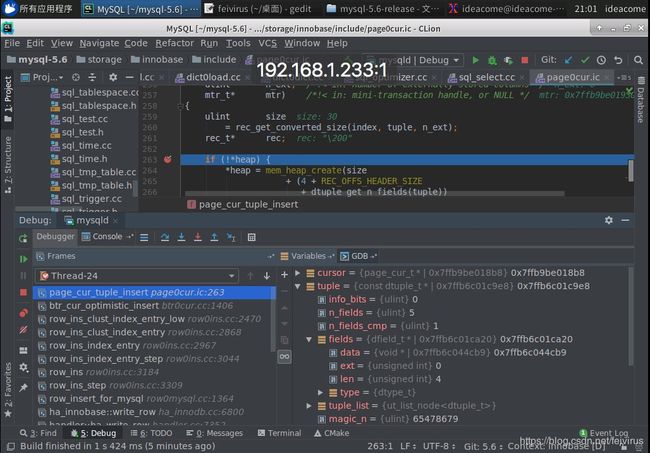
page_cur_tuple_insert()入参是tuple类型.首先计算记录空间大小(包括两部分,extra_size,数据内容),统计每一个列中数据的长度.进入rec_convert_dtuple_to_rec_new()方法转换记录.在这个方法中,记录头大小,调用rec_convert_dtuple_to_rec_comp转为compact格式记录.在这个方法中填充row中的长度,数据信息.
2.在page_cur_tuple_insert()方法中调用page0cur.cc文件中的page_cur_insert_rec_low()在页面中插入记录.在该方法中,首先获取页面中记录大小,然后调用page_header_get_ptr()找到页面可用空间中合适的位置,然后调用上面"五内存管理之页面插入记录"中提及的page_mem_allc_heap()方法找到页内可以用的heap空间.调用rec_copy()方法把记录拷贝到heap中.然后修改页面记录链表的指针.然后修改page header中的最后插入位置.最后调用page_cur_insert_rec_write_log()写插入日志.
3.依靠Buffer Pool的刷新磁盘机制刷新到磁盘.
第九节 Buffer Pool
第十节 主从复制
第十一节. redolog与undolog