通用Mapper学习笔记
简介
什么是通用Mapper
通用Mapper都可以极大的方便开发人员。可以随意的按照自己的需要选择通用方法,还可以很方便的开发自己的通用方法。极其方便的使用MyBatis单表的增删改查。支持单表操作,不支持通用的多表联合查询。
快速开始
添加POM文件
<dependency>
<groupId>tk.mybatisgroupId>
<artifactId>mapperartifactId>
<version>4.0.0-beta3version>
dependency>
创建测试数据
CREATE TABLE `tabple_emp` (
`emp_id` int NOT NULL AUTO_INCREMENT ,
`emp_name` varchar(500) NULL ,
`emp_salary` double(15,5) NULL ,
`emp_age` int NULL ,
PRIMARY KEY (`emp_id`)
);
INSERT INTO `tabple_emp` (`emp_name`, `emp_salary`, `emp_age`) VALUES ('tom', '1254.37', '27');
INSERT INTO `tabple_emp` (`emp_name`, `emp_salary`, `emp_age`) VALUES ('jerry', '6635.42', '38');
INSERT INTO `tabple_emp` (`emp_name`, `emp_salary`, `emp_age`) VALUES ('bob', '5560.11', '40');
INSERT INTO `tabple_emp` (`emp_name`, `emp_salary`, `emp_age`) VALUES ('kate', '2209.11', '22');
INSERT INTO `tabple_emp` (`emp_name`, `emp_salary`, `emp_age`) VALUES ('justin', '4203.15', '30');
Java实体类
public class Employee {
private Integer empId;
private String empName;
private Double empSalary;
private Integer empAge;
注意:考虑到基本数据类型在Java中都有默认值,会导致Mybatis在执行相关操作的时候很难判断当前字段是否为null,所以在Mybatis环境下Java实体类尽量不要使用基本数据类型,都使用对应的包装类型。
修改Sping的配置文件
<bean id="mapperScanner" class="tk.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.example.mapper"/>
bean>
具体操作数据库的接口需要继承通用Mapper的核心接口
public interface EmployeeMapper extends Mapper<Employee> {
}
常用注解
- @Table注解
- 作用:建立实体类和数据表之间的对应关系 。
- 默认规则:实体类的类名首字母小写作为表名。Employee—>employee
- 用法:在@Table注解的name属性中指定目标数据库的表名

2. @Column注解
- 作用:建立实体类字段和数据库表字段之间的对应关系。
- 默认规则:实体类字段驼峰命名法;数据库字段以“_”区分各个单词
- 用法:在@Column 注解的 name 属性中指定目标字段的字段名

- @Id注解
- 通用 Mapper 在执行 xxxByPrimaryKey(key)方法时,有两种情况。
情况 1:没有使用@Id 注解明确指定主键字段
SELECT emp_id,emp_name,emp_salary_apple,emp_age FROM tabple_emp WHERE emp_id = ?
AND emp_name = ? AND emp_salary_apple = ? AND emp_age = ?
之所以会生成上面这样的 WHERE 子句是因为通用 Mapper 将实体类中的所有
字段都拿来放在一起作为联合主键,这样就会导致查询失败。
情况 2:使用@Id 主键明确标记和数据库表中主键字段对应的实体类字段。

4. @GeneratedValue注解
- 作用:让通用 Mapper 在执行 insert 操作之后将数据库自动生成的主键值回写到实
体类对象中
[外链图片转存失败(img-CKF2FOjO-1569398326056)(https://user-gold-cdn.xitu.io/2019/9/25/16d65e491d16e639?w=789&h=91&f=png&s=22948)]
- 应用场景举例:
增加商品销量…
减少商品库存…
生成订单数据→封装到 Order 对象中→保存 Order 对象→数据库自动生成主键
值→回写到实体类对象 Order 中
生成一系列订单详情数据→List→在每一个 OrderItem 中设置
Order 对象的主键值作为外键→批量保存 List
……
当然@GeneratedValue这个注解还可以指定自动生成主键的方式:
//可以用于任意字符串类型长度超过32位的字段
@GeneratedValue(generator = "UUID")
private String username;
- @Transient注解
- 作用:用于标记不与数据库字段对应的实体类字段(不是表中字段的属性必须加@Transient注解)
常用方法演示
- selectOne方法
可以根据任意字段作为查询条件 查询出一条语句:Employee employee = new Employee(null, "bob", null, null); Employee employee1 = employeeService.getOne(employee); - selectByPrimaryKey方法
根据主键查询 但凡遇到xxxByPrimaryKey都要在实体类中标识主键@Id,否则通用mapper会将所有字段作为联合主键使用Employee employee = employeeService.getEmployeeMapper(3); System.out.println(employee); - insert方法
insert方法还有一个功能就是可以返回插入的那条数据自增的主键,不过需要返回的字段需要在实体类中加上@GeneratedValue(strategy = GenerationType.IDENTITY),我们常用的Mysql支持,但是Oracle就不支持了。Employee employee = new Employee(); employee.setEmpAge(11); employee.setEmpName("张三"); employee.setEmpSalary(100.00); employeeService.insertEmployee(employee); Integer empId = employee.getEmpId(); //这里可以返回插入这条数据的ID System.out.println(empId); - insertSelective方法
使用这个方法插入数据,当非主键字段为null时就不加入到sql语句中Employee employee = new Employee(null, "张三", null, null); employeeService.saveEmployeeSelective(employee); - updateByPrimaryKeySelective方法
需要修改字段数据时使用 (可以修改一个或多个字段)Employee employee = new Employee(7, "dog", null, null); employeeService.updateEmployeeSelective(employee); - delete方法
可以同时删除整张表中的数据 (使用此方法不是很安全)Employee employee = null; employeeService.removeEmployee(employee); - deleteByPrimaryKey方法
根据主键删除数据Integer empId = 7; employeeService.deleteEmployeeByPrimaryKey(empId);
QBC查询
Query By Criteria。Criteria 是 Criterion 的复数形式。意思是:规则、标准、准则。在 SQL 语句中相当于查询条件。QBC 查询是将查询条件通过 Java 对象进行模块化封装。
示例
server
public List<Employee> getEmpListByExample(Example example) {
//QBC查询
return employeeMapper.selectByExample(example);
}
测试
@Test
public void testSelectByExample() {
Example example = new Example(Employee.class);
//i.设置排序信息 根据实体类中的字段
example.orderBy("empSalary").asc().orderBy("empAge").desc();//根据empSalary升序,根据empAge降序
//ii.设置“去重”
example.setDistinct(true);
//iii.设置select字段 表示查询出来的数据只列出指定的字段,其他的字段的数据不展示
example.selectProperties("empName","empSalary");
Example.Criteria criteria1 = example.createCriteria();
Example.Criteria criteria2 = example.createCriteria();
//它们之间是 或 的关系 or
criteria1.andGreaterThan("empSalary", 2000).//表示年龄小于25,工资高于2000
andLessThan("empAge", 25);
criteria2.andLessThan("empSalary", 5000).andGreaterThan("empAge", 30);
example.or(criteria2);
//传入example实例
List<Employee> employeeList = employeeService.getEmpListByExample(example);
for (Employee employee : employeeList) {
System.out.println(employee);
}
}
分页查询
//service
public List<Employee> getEmpListByRowBounds(RowBounds rowBounds) {
return employeeMapper.selectByRowBounds(null, rowBounds);
}
//test
@Test
public void testSelectByRowBounds() {
//此方法用来帮我们做分页的
//它并没有使用limit字句,它的实现原理就是把所有的数据都查询出来,放在内存中了,然后根据条件进行分页
//所以这个方法意义不大,真正做分页还是使用pageHelper
int pageNo = 3;
int pageSize = 5;
int index = (pageNo - 1) * pageSize;
RowBounds rowBounds = new RowBounds(index, pageSize);
List<Employee> empList = employeeService.getEmpListByRowBounds(rowBounds);
for (Employee employee : empList) {
System.out.println(employee);
}
}
自定义Mapper接口

用途
让我们可以根据开发的实际需要对 Mapper接口进行定制。
- 创建自定义的Mappep接口
public interface MyMapper<T>
extends SelectAllMapper<T>,SelectByExampleMapper<T> {//可以自由选择
}
- 具体的Mapper继承自定义的MyMapper接口
public interface EmployeeMapper extends MyMapper<Employee> {
}
- 在Sping的配置文件中配置 MapperScannerConfigurer注册 MyMapper
<bean class="tk.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.example.mapper.mappers"/>
<property name="properties">
<value>
mappers=com.example.mapper.mine_mappers.MyMapper
value>
property>
bean>
然后就可以测试使用了
通用Mapper接口扩展
这里的扩展指的是通用Mapper没有提供的功能
官方例子
举例
批量 update 作为扩展功能的例子:
类似于生成下面这样的SQL语句:
UPDATE tabple_emp SET emp_name=?,emp_age=?,emp_salary=? where emp_id=? ;
UPDATE tabple_emp SET emp_name=?,emp_age=?,emp_salary=? where emp_id=? ;
UPDATE tabple_emp SET emp_name=?,emp_age=?,emp_salary=? where emp_id=? ;
……
为了生成上面那样的 SQL 语句,我们需要使用到 MyBatis 的 foreach 标签。
<foreach collection="list" item="record" separator=";" >
UPDATE tabple_emp
SET emp_name=#{record.empName},
emp_age=#{record.empAge},
emp_salary=#{record.empSalary}
where emp_id=#{record.empId}
foreach>
- 自定义一个接口
@RegisterMapper //这个注解别忘了
public interface MyBatchUpdateMapper<T> {
//method是固定值dynamicSQL,type指定具体提供sql语句的类
@UpdateProvider(type=MyBatchUpdateProvider.class, method="dynamicSQL")
void batchUpdate(List<T> list);
}
- 编写具体实现功能的类,类名为前面接口中type指的是类名,这个类必须继承MapperTemplate,重写构造方法
- 在类中提供一个和前面接口中同名的方法然后实现
具体实现
public class MyBatchUpdateProvider extends MapperTemplate {
//首先继承MapperTemplate,然后重写构造方法
public MyBatchUpdateProvider(Class<?> mapperClass, MapperHelper mapperHelper) {
super(mapperClass, mapperHelper);
}
/* 目的就是让这个方法为我们拼接一个字符串:下面 ↓
UPDATE tabple_emp
emp_name=#{record.empName},
emp_age=#{record.empAge},
emp_salary=#{record.empSalary},
where emp_id=#{record.empId}
*/
//然后提供一个同名的实现方法
public String batchUpdate(MappedStatement statement) {
//1.创建StringBuilder用于拼接SQL语句的各个组成部分
StringBuilder builder = new StringBuilder();
//2.拼接foreach标签
builder.append("" );
//3.获取实体类对应的Class对象
Class<?> entityClass = super.getEntityClass(statement);
//4.获取实体类在数据库中对应的表名
String tableName = super.tableName(entityClass);
//5.生成update子句
String updateClause = SqlHelper.updateTable(entityClass, tableName);
builder.append(updateClause);
builder.append("" );
//6.获取所有字段信息
Set<EntityColumn> columns = EntityHelper.getColumns(entityClass);
String idColumn = null;
String idHolder = null;
for (EntityColumn entityColumn : columns) {
boolean isPrimaryKey = entityColumn.isId();
//7.判断当前字段是否为主键
if(isPrimaryKey) {
//8.缓存主键的字段名和字段值
idColumn = entityColumn.getColumn();
//※返回格式如:#{record.age,jdbcType=NUMERIC,typeHandler=MyTypeHandler}
idHolder = entityColumn.getColumnHolder("record");
}else {
//9.使用非主键字段拼接SET子句
String column = entityColumn.getColumn();
String columnHolder = entityColumn.getColumnHolder("record");
builder.append(column).append("=").append(columnHolder).append(",");
}
}
builder.append("");
//10.使用前面缓存的主键名、主键值拼接where子句
builder.append("where ").append(idColumn).append("=").append(idHolder);
builder.append("");
//11.将拼接好的字符串返回
return builder.toString();
}
}
- 我们可以定义的一个Mapper接口,并继承于之前定义的那个Mapper接口
public interface MyMapper<T>
extends SelectAllMapper<T>,SelectByExampleMapper<T>,
MyBatchUpdateMapper<T> {//继承自己定义的接口
}
public interface EmployeeMapper extends Mapper<Employee> {
}
service
@Service
public class EmployeeService {
@Autowired
private EmployeeMapper employeeMapper;
public void batchUpdateEmp(List<Employee> empList) {
employeeMapper.batchUpdate(empList);
}
}
这里MyMapper同样需要注册
<bean class="tk.mybatis.spring.mapper.MapperScannerConfigurer">
<property name="basePackage" value="com.example.mapper.mappers"/>
<property name="properties">
<value>
mappers=com.example.mapper.mine_mappers.MyMapper
value>
property>
bean>
最后测试通过即可
ClassPathXmlApplicationContext iocContainer = new ClassPathXmlApplicationContext("spring-context.xml");
EmployeeService employeeService = iocContainer.getBean(EmployeeService.class);
List<Employee> empList = new ArrayList<>();
empList.add(new Employee(25, "newName01", 111.11, 10));
empList.add(new Employee(26, "newName02", 222.22, 20));
empList.add(new Employee(27, "newName03", 333.33, 30));
employeeService.batchUpdateEmp(empList);
iocContainer.close();
二级缓存(了解即可)
注意:实际开发中真正做缓存的都是redis、ehcache…这些
在mapper中加入此注解表示开启二级缓存,传入的实体类需要有序列化
- MyBatis 配置文件开启二级缓存功能

- 在 XxxMapper 接口上使用@CacheNamespace 注解
类型处理器:TypeHandler
简单类型和复杂类型
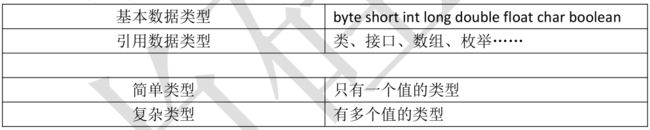
通用 Mapper 默认情况下会忽略复杂类型,对复杂类型不进行“从类到表”的映射。
这时候就需要我们自定义类型转换器了
普通复杂类型处理
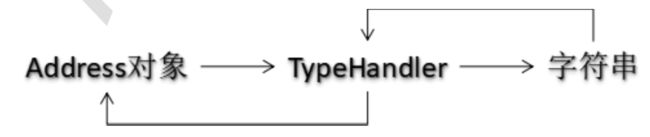
- 新建一个类继承BaseTypeHandler,并且实现其中的抽象方法
public class AddressTypeHandler extends BaseTypeHandler<Address> {
/**
* 设置参数
* 将parameter对象转换成字符串存储到ps对象的i位置
* @param ps
* @param i
* @param address
* @param jdbcType
* @throws SQLException
*/
@Override
public void setNonNullParameter(PreparedStatement ps, int i, Address address, JdbcType jdbcType) throws SQLException {
/* 1.对address对象进行验证 */
if (address == null) {
return;
}
/* 2.从address对象中取出具体数据 */
String province = address.getProvince();
String city = address.getCity();
String street = address.getStreet();
/* 3.拼装成一个字符串
* 规则:各个值之间使用“,”分开 */
StringBuilder builder = new StringBuilder();
builder.append(province)
.append(",")
.append(city)
.append(",")
.append(street);
String parameterValue = builder.toString();
//4.设置参数
ps.setString(i, parameterValue);
}
/**
* 用列的名称取
* @param rs
* @param columnName
* @return
* @throws SQLException
*/
@Override
public Address getNullableResult(ResultSet rs, String columnName) throws SQLException {
//1.根据字段名从rs对象中获取字段值
String columnValue = rs.getString(columnName);
//2.验证columnValue是否有效
if(columnValue == null || columnValue.length() == 0 || !columnValue.contains(",")) {
return null;
}
//3.根据“,”对columnValue进行拆分
String[] split = columnValue.split(",");
//4.从拆分结果数组中获取Address需要的具体数据
String province = split[0];
String city = split[1];
String street = split[2];
//5.根据具体对象组装一个Address对象
Address address = new Address(province, city, street);
return address;
}
//从结果集中获取数据库对应的查询结果
//将字符串还原为原始的T对象
/**
* 用列的索引取
* @param rs
* @param columnIndex
* @return
* @throws SQLException
*/
@Override
public Address getNullableResult(ResultSet rs, int columnIndex) throws SQLException {
//1.根据字段名从rs对象中获取字段值
String columnValue = rs.getString(columnIndex);
//2.验证columnValue是否有效
if(columnValue == null || columnValue.length() == 0 || !columnValue.contains(",")) {
return null;
}
//3.根据“,”对columnValue进行拆分
String[] split = columnValue.split(",");
//4.从拆分结果数组中获取Address需要的具体数据
String province = split[0];
String city = split[1];
String street = split[2];
//5.根据具体对象组装一个Address对象
Address address = new Address(province, city, street);
return address;
}
/**
*
* @param cs
* @param columnIndex
* @return
* @throws SQLException
*/
@Override
public Address getNullableResult(CallableStatement cs, int columnIndex) throws SQLException {
//1.根据字段名从rs对象中获取字段值
String columnValue = cs.getString(columnIndex);
//2.验证columnValue是否有效
if(columnValue == null || columnValue.length() == 0 || !columnValue.contains(",")) {
return null;
}
//3.根据“,”对columnValue进行拆分
String[] split = columnValue.split(",");
//4.从拆分结果数组中获取Address需要的具体数据
String province = split[0];
String city = split[1];
String street = split[2];
//5.根据具体对象组装一个Address对象
Address address = new Address(province, city, street);
return address;
}
}
- 注册自定义类型转换器
- 方法一、字段级别:@ColumnType注解
@ColumnType(typeHandler=AddressTypeHandler.class)//注册类型处理器
private Address address;
然后测试就OK了
- 方法二、全局级别:在Mybatis配置文件中配置typeHandlers
首先在字段上加一个
然后在Mybatis配置文件中进行配置@Column private Address address;<typeHandlers> <typeHandler handler="com.example.handlers.AddressTypeHandler" javaType="com.example.entity.Address"/> typeHandlers>
枚举类型
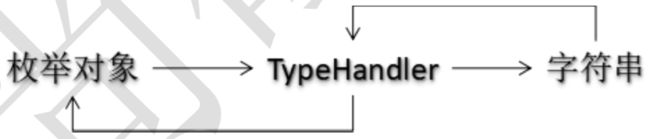
- 方法一、让通用 Mapper 把枚举类型作为简单类型处理
增加一个通用Mapper配置项
在 Spring 配置文件中找到 MapperScannerConfigurer
这里本质上是使用了 org.apache.ibatis.type.EnumTypeHandler<bean class="tk.mybatis.spring.mapper.MapperScannerConfigurer"> <property name="basePackage" value="com.example.mappers"/> <property name="properties"> <value> enumAsSimpleType=true value> property> bean>
然后测试OK - 方法二、为枚举类型配置专门的类型处理器
- 内置
- org.apache.ibatis.type.EnumTypeHandler 在数据库中存储枚举值本身
- org.apache.ibatis.type.EnumOrdinalTypeHandler 在数据库中仅仅存储枚举值的索引
内置的类型处理器不能使用@ColumnType 注解
※注意:加@Column 注解的作用是让通用 Mapper 不忽略枚举类型。<typeHandlers> <typeHandler handler="com.example.handlers.AddressTypeHandler" javaType="com.example.entity.Address"/> <typeHandler handler="org.apache.ibatis.type.EnumOrdinalTypeHandler" javaType="com.atguigu.mapper.entities.SeasonEnum"/> typeHandlers>- 自定义,自定义类型转换器和之前的address的配置方式是一样的
- 内置