数据分析实战之决策树(泰坦尼克号乘客生存预测)
本文利用已给特征属性和存活与否标签的训练集和只包含特征信息测试集数据,通过决策树模型来预测测试集数据乘客的生存情况
数据集来源为https://github.com/cystanford/Titanic_Data,可下载数据查看其各字段信息
生存预测的流程:
1、数据探索:
import numpy as np
import pandas as pd
train_data = pd.read_csv(r'C:\Users\hzjy\Desktop\train.csv') #加载数据
test_data = pd.read_csv(r'C:\Users\hzjy\Desktop\test.csv')
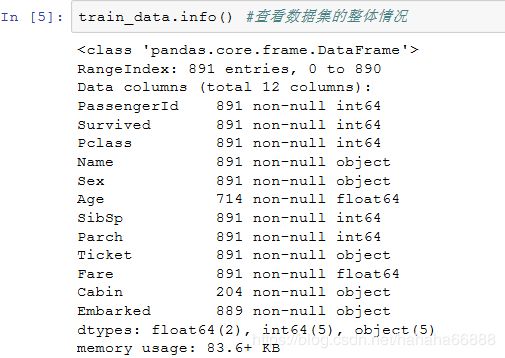
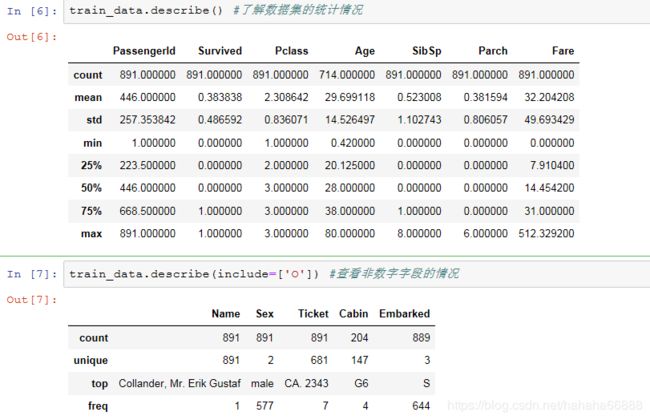
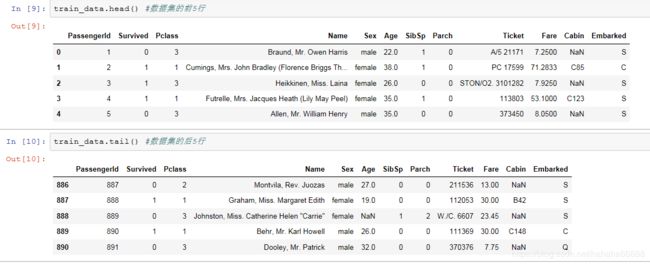
1)训练集数据的整体特征:
2)测试集数据的整体特征:

2、数据清洗
1)训练集:可以看到Age、Cabin、Embarked是有缺失数据的
- Age中的空值可用平均年龄来填充
train_data['Age'].fillna(train_data['Age'].mean(),inplace = True)- Cabin有大量的缺失值,在训练集和测试集中缺失率都比较高,无法补齐
- Embarked为登陆港口,可以根据港口属性补齐。可以看到港口为“S”类型的占比最高,可以考虑把缺失的港口用“S”港口填充

可以看到港口为“S”类型的占比最高,可以考虑把缺失的港口用“S”港口填充
train_data['Embarked'].fillna('S',inplace = True)
2)测试集:可以看到Age、Fare、Cabin是有缺失数据的
- Age中的空值可用平均年龄来填充
test_data['Age'].fillna(test_data['Age'].mean(),inplace = True)- Fare中的空值可用平均票价来填充
test_data['Fare'].fillna(test_data['Fare'].mean(),inplace = True)- Cabin有大量的缺失值,在训练集和测试集中缺失率都比较高,无法补齐
3、特征选择:选择对分类结果有关键作用的特征
1)通过数据探索,发现PassengerId和Name对分类没有太大作用;Cabin有大量的缺失值,可以放弃;Ticket字段编码较乱,没有太大作用。其余字段可能和预测乘客的生存情况有关,通过分类器来处理。
将剩余字段放到特征向量features里。
features = ['Pclass','Sex','Age','SibSp','Parch','Fare','Embarked']
train_features = train_data[features]
train_labels = train_data['Survived']
test_features = test_data[features]2)特征值有一些是字符串,不方便后续的运算,需要把它们转化为数值类型,
- Sex 有male和female两种类型,可以把它变成 Sex=male 和 Sex = female, 数值用0或1来表示
- Embarked 有S 、C 、Q三种类型,可以把它变成Embarked= S 、 Embarked= C、Embarked= Q,数值用0或1来表示
可以使用sklearn 特征选择中的 DictVectorizer类,用它可以处理符号化的对象,将符号转化为数字0或1进行表示
from sklearn.feature_extraction import DictVectorizer
dv = DictVectorizer(sparse = False)
train_features = dv.fit_transform(train_features.to_dict(orient= 'record'))fit_transform可以将特征向量转化为特征矩阵,通过dv.feature_names_ 属性值查看转化后的属性

4、决策树模型:使用ID3算法 构造决策树
在创建决策树时,设置 criterion = 'entropy' ,然后使用 fit 进行训练,将特征值矩阵和分类结果作为参数传入,得到决策树分类器

将预测后的结果导出到文件中:
test_data['Survived'] = pred_labels
test_data.to_csv(r'C:\Users\hzjy\Desktop\test1.csv') #预测后的测试集导出5、模型评估和预测
在预测中,首选需要得到测试集的特征值矩阵,然后使用训练好的决策树进行预测
test_features = dv.transform(test_features.to_dict(orient= 'record'))
pred_labels = clf.predict(test_features)在模型评估中,决策树提供了score函数可以直接得到准确率。但由于我们的测试集中并没有真实的生存状况的结果,只能使用训练集中的数据进行模型评估

用训练集做训练,再用训练集自身做准确率评估,这样得出的准确率并不能代表决策树分类器的准确性。用K折交叉验证统计决策树分类器的准确率。
K折交叉验证的原理:
1)将数据集平均分割成K个等份
2)使用1份的数据作为测试数据,其余作为训练数据
3)计算测试准确率
4)使用不同的测试集,重复2、3步骤。
5)训练k次,最后将k次的测试准确率求平均值,作为对未知数据预测准确率的估计。
在sklearn的model_selection 模型选择中提供了cross_val_score函数

对于不知道测试集实际结果的,要使用K折交叉验证才能知道模型的准确情况
6、决策树可视化
使用graphviz可视化工具把决策树呈现出来
关于graphviz的下载:我用的是anaconda,通过在anaconda prompt界面输入 conda install python-graphviz 来安装graphviz
from sklearn import tree
import graphviz
dot_data = tree.export_graphviz(clf, out_file=None)
graph = graphviz.Source(dot_data)
graph.view()会得到一个决策树可视化的pdf文件。