分享丨李飞飞、吴恩达、Bengio等人的顶级深度学习课程------斯坦福大学Andrew Ng教授主讲的《机器学习》公开课观后感
斯坦福CS231n 2017春季课程全公开,视频+PPT+英文字幕
2017年08月16日 21:11:43 Dean0Winchester 阅读数:5217

全部课程视频(英文字幕):http://t.cn/R9Dfnxn
所有课程资料、PPT等:http://cs231n.stanford.edu/syllabus.html
课程描述

讲师和助教团队
计算机视觉在我们的社会中已经无处不在,例如应用于搜索、图像理解、apps、地图、医疗、无人机、自动驾驶汽车,等等。大部分应用的核心是视觉识别任务,例如图像分类、定位和检测。神经网络(又称“深度学习”)方法最新的进展大大提高了这些最先进的视觉识别系统的性能。本课程将带大家深入了解深度学习的架构,重点是学习这些任务,尤其是图像分类任务的端到端模型。
在为期10周的课程中,同学们将要学习实现、训练和调试自己的神经网络,并深入了解计算机视觉的最前沿的研究。期末作业将涉及训练一个数百万参数的卷积神经网络,并将其应用于最大的图像分类数据集(ImageNet)。我们将重点介绍如何创建图像识别问题,学习算法(例如反向传播算法),训练和微调网络的实用工程技巧,引导学生进行实际操作和最终的课程项目。本课程的背景知识和材料的大部分来自 ImageNet 挑战赛。
先修要求
-
熟练使用Python,C / C ++高级熟悉所有的类分配都将使用Python(并使用numpy)(我们为那些不熟悉Python的人提供了一个教程),但是一些深入学习的库 我们可以看看后面的类是用C ++编写的。 如果你有很多的编程经验,但使用不同的语言(例如C / C ++ / Matlab / Javascript),你可能会很好。
-
大学微积分,线性代数(例如MATH 19或41,MATH 51)您应该很乐意使用衍生词和理解矩阵向量运算和符号。
-
基本概率和统计学(例如CS 109或其他统计学课程)您应该知道概率的基础知识,高斯分布,平均值,标准偏差等。
-
CS229(机器学习)的等效知识我们将制定成本函数,采用导数和梯度下降执行优化。
课程 Notes:
课程Notes: http://cs231n.github.io/
模块0:准备内容
Python / Numpy 教程
IPython Notebook 教程
Google Cloud 教程
Google Cloud with GPU教程
AWS 教程
模块1:神经网络
-
图像分类:数据驱动的方法,k最近邻法,train/val/test splits
L1 / L2距离,超参数搜索,交叉验证
-
线性分类:支持向量机,Softmax
参数化方法,bias技巧,hinge loss,交叉熵损失,L2正则化,web demo
-
优化:随机梯度下降
本地搜索,学习率,分析/数值梯度
-
反向传播,直觉
链规则解释,real-valued circuits,gradient flow中的模式
-
神经网络第1部分:建立架构
生物神经元模型,激活函数,神经网络架构
-
神经网络第2部分:设置数据和损失
预处理,权重初始化,批量归一化,正则化(L2 /dropout),损失函数
-
神经网络第3部分:学习和评估
梯度检查,完整性检查,动量(+ nesterov),二阶方法,Adagrad / RMSprop,超参数优化,模型集合
-
把它放在一起:一个神经网络案例研究
极小2D玩具数据示例
模块2:卷积神经网络
-
卷积神经网络:架构,卷积/池化层
层,空间排列,层模式,层大小模式,AlexNet / ZFNet / VGGNet案例研究,计算考虑
-
理解和可视化卷积神经网络
tSNE嵌入,deconvnets,数据梯度,fooling ConvNets,human comparisons
-
迁移学习和微调卷积神经网络
内容简介
Lecture 1:面向视觉识别的卷积神经网络课程简介

Lecture 1介绍了计算机视觉这一领域,讨论了其历史和关键性挑战。我们强调,计算机视觉涵盖各种各样的不同任务,尽管近期深度学习方法取得了一些成功,但我们仍然远远未能实现人类水平的视觉智能的目标。
关键词:计算机视觉,寒武纪爆炸,暗箱,Hubel 和 Wiesel,积木块世界,规范化切割,人脸检测,SIFT,空间金字塔匹配,定向梯度直方图,PASCAL视觉对象挑战赛,ImageNet挑战赛
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture1.pdf
Lecture 2:图像分类

Lecture 2 使图像分类问题正式化。我们讨论了图像分类问题本身的难点,并介绍了数据驱动(data-driven)方法。我们讨论了两个简单的数据驱动图像分类算法:K-最近邻法(K-Nearest Neighbors)和线性分类(Linear Classifiers)方法,并介绍了超参数和交叉验证的概念。
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture2.pdf
Lecture 3:损失函数和最优化
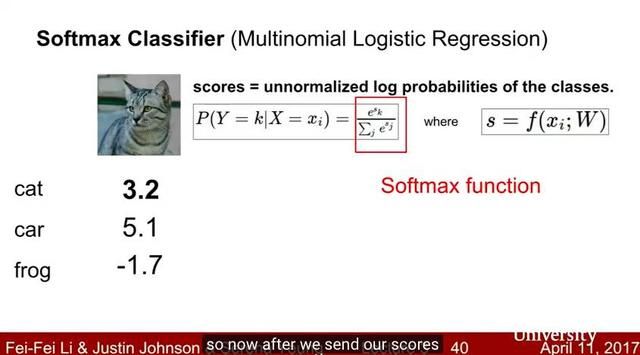
Lecture 3 继续讨论线性分类器。我们介绍了损失函数的概念,并讨论图像分类的两个常用的损失函数:多类SVM损失(multiclass SVM loss)和多项逻辑回归损失(multinomial logistic regression loss)。我们还介绍了正规化(regularization ),作为对付过拟合的机制,以及将权重衰减(weight decay )作为一个具体的例子。 我们还介绍了优化(optimization)的概念和随机梯度下降(stochastic gradient descent )算法。我们还简要讨论了计算机视觉特征表示(feature representation)的使用。
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture3.pdf
Lecture 4:神经网络介绍

在 Lecture 4 中,我们从线性分类器进展到全连接神经网络(fully-connected neural network)。本节介绍了计算梯度的反向传播算法(backpropagation algorithm),并简要讨论了人工神经网络与生物神经网络之间的关系。
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture4.pdf
Lecture 5:卷积神经网络

在 Lecture 5 中,我们从完全连接的神经网络转向卷积神经网络。我们将讨论卷积网络发展中的一些关键的历史里程碑,包括感知器,新认知机(neocognitron),LeNet 和 AlexNet。我们将介绍卷积(convolution),池化(pooling)和完全连接(fully-connected)层,这些构成了现代卷积网络的基础。
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture5.pdf
Lecture 6:训练神经网络1
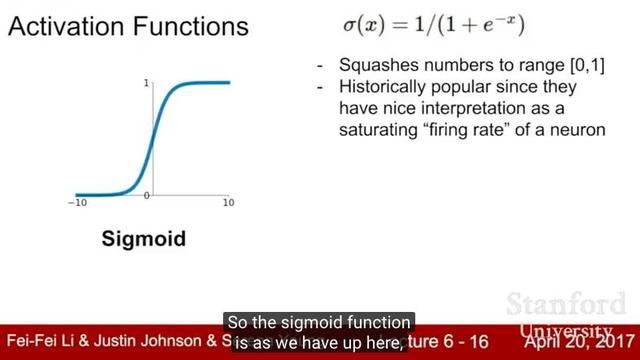
在Lecture 6中,我们讨论了现代神经网络的训练中的许多实际问题。我们讨论了不同的激活函数,数据预处理、权重初始化以及批量归一化的重要性; 我们还介绍了监控学习过程和选择超参数的一些策略。
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture6.pdf
Lecture 7:训练神经网络2
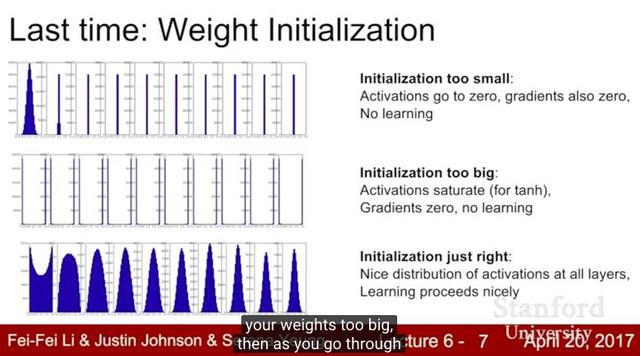
Lecture 7继续讨论训练神经网络中的实际问题。我们讨论了在训练期间优化神经网络的不同更新规则和正则化大型神经网络的策略(包括dropout)。我们还讨论转移学习(transfer learnin)和 fine-tuning。
关键词:优化,动量,Nesterov动量,AdaGrad,RMSProp,Adam,二阶优化,L-BFGS,集合,正则化,dropout,数据扩张,迁移学习,fine-tuning
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture7.pdf
Lecture 8:深度学习软件

Lecture 8 讨论了如何使用不同的软件包进行深度学习,重点介绍 TensorFlow 和 PyTorch。我们还讨论了CPU和GPU之间的一些区别。
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture8.pdf
Lecture 9:CNN架构

Lecture 9 讨论了卷积神经网络的一些常见架构。我们讨论了 ImageNet 挑战赛中表现很好的一些架构,包括AlexNet,VGGNet,GoogLeNet 和 ResNet,以及其他一些有趣的模型。
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture9.pdf
Lecture 10:循环神经网络
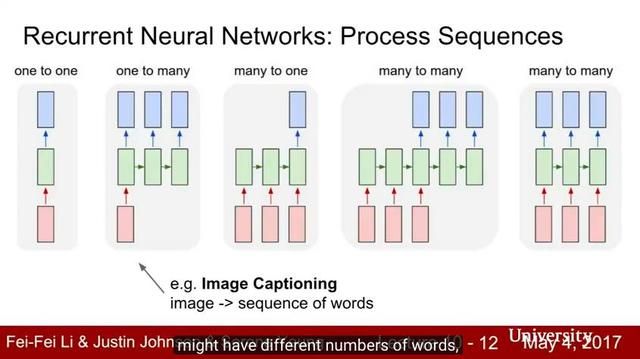
Lecture 10讨论了如何使用循环神经网络为序列数据建模。我们展示了如何将循环神经网络用于语言建模和图像字幕,以及如何将 soft spatial attention 纳入图像字幕模型中。我们讨论了循环神经网络的不同架构,包括长短期记忆(LSTM)和门循环单元(GRU)。
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture10.pdf
Lecture 11:检测和分割

在Lecture 11中,我们超越了图像分类,展示了如何将卷积网络应用于其他计算机视觉任务。我们展示了具有下采样和上采样层的完全卷积网络可以怎样用于语义分割,以及多任务损失如何用于定位和姿态估计。我们讨论了一些对象检测方法,包括基于区域的R-CNN系列方法和 single-shot 方法,例如SSD和YOLO。最后,我们展示了如何将来自语义分割和对象检测的想法结合起来进行实例分割( instance segmentation)。
关键词:语义分割,完全卷积网络,unpooling,转置卷积(transpose convolution),localization,多任务损失,姿态估计,对象检测,sliding window,region proposals,R-CNN,Fast R-CNN,Faster R-CNN,YOLO,SSD,DenseCap ,实例分割,Mask R-CNN
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf
Lecture 12:可视化和理解

Lecture 12讨论了可视化和理解卷积网络内部机制的方法。我们还讨论了如何使用卷积网络来生成新的图像,包括DeepDream和艺术风格迁移。
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture12.pdf
Lecture 13:生成模型
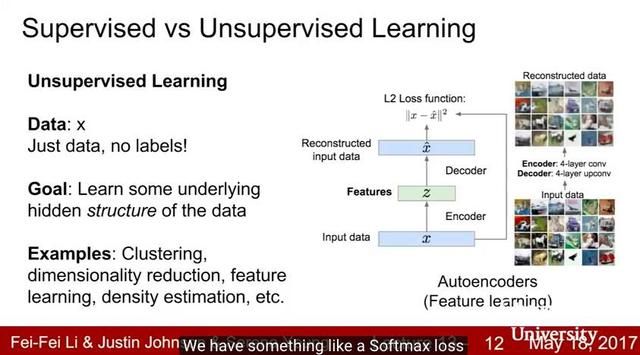
在Lecture 13中,我们超越了监督学习,并将生成模型作为一种无监督学习的形式进行讨论。我们涵盖了自回归的 PixelRNN 和 PixelCNN 模型,传统和变分自编码器(VAE)和生成对抗网络(GAN)。
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture13.pdf
Lecture 14:深度强化学习
在Lecture 14中,我们从监督学习转向强化学习(RL)。强化学习中,智能体必须学会与环境交互,才能最大限度地得到奖励。 我们使用马尔科夫决策过程(MDPs),策略,价值函数和Q函数的语言来形式化强化学习。我们讨论了强化学习的不同算法,包括Q-Learning,策略梯度和Actor-Critic。我们展示了强化学习被用于玩 Atari 游戏,AlphaGo在围棋中超过人类专业棋手等。
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture14.pdf
Lecture 15:深度学习的高效方法和硬件

在Lecture 15中,客座讲师 Song Han 讨论了可用于加快深度学习工作负载训练和推理的算法和专用硬件。我们讨论了剪枝,weight sharing,量化等技术,以及其他加速推理过程的技术,包括并行化,混合精度(mixed precision)等。我们讨论了用于深度学习的专门硬件,例如GPU,FPGA 和 ASIC,包括NVIDIA最新Volta GPU中的Tensor Core,以及谷歌的TPU(Tensor Processing Units)。
关键词:硬件,CPU,GPU,ASIC,FPGA,剪枝,权重共享,量化,二元网络,三元网络,Winograd变换,EIE,数据并行,模型并行,混合精度,FP16,FP32,model distillation,Dense-Sparse-Dense训练,NVIDIA Volta,Tensor Core,Google TPU,Google Cloud TPU
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture15.pdf
Lecture 16:对抗样本和对抗训练

Lecture 16由客座讲师Ian Goodfellow主讲,讨论了深度学习中的对抗样本(Adversarial Examples)。本讲讨论了为什么深度网络和其他机器学习模型容易受到对抗样本的影响,以及如何使用对抗样本来攻击机器学习系统。我们讨论了针对对抗样本的潜在防御,以及即使在没有明确的对手的情况下,如何用对抗样本来改进机器学习系统,。
关键词:对抗样本,Fooling images,fast gradient sign method(FGSM),Clever Hans,对抗防御,物理世界中的对抗样本,对抗训练,虚拟对抗训练,基于模型的优化
PPT:cs231n.stanford.edu/slides/2017/cs231n_2017_lecture16.pdf
近日,在网易公开课视频网站上看完了《机器学习》课程视频,现做个学后感,也叫观后感吧。
学习时间
从2013年7月26日星期五开始,在网易公开课视频网站上,观看由斯坦福大学Andrew Ng教授主讲的计算机系课程(编号CS229)《机器学习》(网址http://v.163.com/special/opencourse/machinelearning.html)(注:最早是在新浪公开课上发现的这门课,看了前几集没有字幕的视频。后来经由技术群网友的指引才找到网易,看到了全部翻译完的视频)。我基本上每天看1-2集,不熟悉的内容会在第二天复习一遍。到2013年8月17日全部视频看完,前后用了23天,中间有几天有事或者脑子不在状态就没看。全部看完之后,又找自己感兴趣的重看,我翻看了第11集的内容,“对开发机器学习应用的建议”,老师根据自己的实际项目经验提出了很好的建议,对我们的实战有很大的帮助。
课程设置和内容
视频课程分为20集,每集72-85分钟。实体课程大概一周2次,中间还穿插助教上的习题课,大概一个学期的课程。
内容涉及四大部分,分别是:监督学习(2-8集)、学习理论(9集-11集)、无监督学习(12-15集)、强化学习(16-20集)。监督学习和无监督学习,基本上是机器学习的二分法;强化学习位于两者之间;而学习理论则从总体上介绍了如何选择、使用机器学习来解决实际问题,以及调试(比如:误差分析、销蚀分析)、调优(比如:模型选择、特征选择)的各种方法和要注意的事项(比如,避免过早优化)。
监督学习,介绍了回归、朴素贝叶斯、神经网络、SVM(支持向量机)、SMO(顺序最小优化)算法等;无监督学习讲了聚类、K-means、GMM(混合高斯模型)、EM算法 、PCA(主成分分析)、LSI(潜在语义索引)、SVD(奇异值分解)、ICA(独立成分分析)等;强化学习主要讲了这类连续决策学习(马尔科夫决策过程,MDP)中的值迭代(VI)和策略迭代(PI),以及如何定义回报函数,如何找到最佳策略等问题。
授课方式
网上有老师的讲义,可以在网易这门课的主页面上打包下载(网址http://v.163.com/special/opencourse/machinelearning.html)。老师基本上是写板书的,PPT是辅助。在黑板上用粉笔边讲解边书写,有助于带动学生的思考,使师生之间有交流有互动。个人以为,比直接显示PPT效果好。数学公式的推导很费时间,课堂上也不可能大多数的时间用来推导公式,所以大量的推导老师要求学生在课下看讲义,或者通过习题课听助教讲解。
授课语言
因为是美国的课堂,当然的教学语言是英语。网易做的不错,除了把老师说的话全部转写下来,还做了中文翻译,前14集翻译得不错,除了偶有错别字之外,专业术语翻译的很好,语句也很流畅。第15集以后一直到最后一堂课,翻译的不是太准确,一些专业术语都翻译错了,很让观者感到不适。但是,无论如何,还是感谢网易这些转写和翻译的无名网友无私的付出。这些小的瑕疵不会让真正热爱这门课程的学习者放弃学习,反而想加入翻译者的队伍,为传播科学知识而贡献力量呢。
观后感
总体感觉,老师讲的不错,是个真正懂机器学习的人。老师在课上也说过,很容易区分那些真正懂机器学习的人,和那些只会纸上谈兵的人。我希望成为第一类,并为此努力着。
老师是华裔,中文名字叫吴恩达,生于伦敦,看上去很亲切。课堂很活跃,老师注重和学生交流,每讲完一个主题,会问学生有问题吗,然后一一作答。
视频大概录制于2007年(个人推测,未经考证),内容上,与现在的机器学习技术比,稍微显得不够多。近年来,机器学习领域有了长足的发展,学术界和工业界齐发力,二者相互促进,达到了前所未有的高度。即便是曾经沉寂的神经网络,近年来也改头换面成了深度学习。不过,从专家的角度看,这不是一种新的机器学习技术,它只是涉及到其中的一个环节——特征选择,并不构成一个独立的学习方法。
老师没有涉及实战。受限于课堂讲授的方式和时间上的限制,课上只能做必要知识点的讲解。
数学公式比较多,似懂非懂的。如果不满足于“知其然”,还要“知其所以然”,以后的方向是搞模型、算法研究的话,那还要补习一下数学知识,必须的。如果仅是为了解决实际问题,对算法要求不高的话,那知道如何运用就够了。剩下的,随着应用系统的不断进展,对整个系统各方面要求的提高,那时会倒逼你进阶的。
遗憾的是,因为没有完全掌握,所以再回看已经看过的视频,还是似懂非懂,但是比第一次要好很多。建议大家多看几遍,加强练习,跟自己的项目相结合,动手实现会加深理解。“精通的目的全在于应用”(毛语),机器学习只是工具,应用到解决实际问题上才能真正体现它的价值。
跟这个课程最接近的,是加州理工学院的《机器学习与数据挖掘》(18集)(网址http://v.163.com/special/opencourse/learningfromdata.html),主讲老师有口音,很重,如果没有中文字幕的帮助,很难快速掌握。目前网易的进展是,翻译完了前4集。
顺便说一句,以后想练专业口语的话,可以多看Andrew Ng这个,跟着说,以后在国际会议上就能充分表达了。听加州理工的这个,也能听懂那些非英语母语国家讲的英语了。不同的地方有不同的英语口音,我们还不算难听的,应该算是好听的,呵呵。
又及,自己心里暗想,土鳖也能“准”“海归”一回。网络带来了革命,网络也给我们这些爱学习的人带来了真正“免费的午餐”。其实,话说回来,就像免费的搜索引擎一样,他们收获的是更大的名声上的胜利,扩大了影响,传播了美誉。像耶鲁大学的一个教授的一句玩笑话,其目的是争取“世界学术霸权”。
Andrew Ng教授的《机器学习》公开课视频(30集)
http://openclassroom.stanford.edu/MainFolder/CoursePage.php?course=MachineLearning
Andrew Ng教授的Deep Learning维基,有中文翻译
http://deeplearning.stanford.edu/wiki/index.php/UFLDL_Tutorial
其他教学资源
韩家炜教授在北大的《数据挖掘》暑期班视频,英文PPT,中文讲解(22集)
http://v.youku.com/v_show/id_XMzA3NDI5MzI=.html(视频:01数据挖掘概念,课程简介,数据库技术发展史,数据挖掘应用)
韩家炜教授(UIUC大学)的《数据挖掘》在线课程
https://wiki.engr.illinois.edu/display/cs412/Home;jsessionid=6BF0A2C36A95A31D2DA754A017756F4B
卡内基•梅隆大学(CMU)的《机器学习》在线课程
http://www.cs.cmu.edu/~epxing/Class/10701/lecture.html
麻省理工学院(MIT)的《机器学习》在线课程
http://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-867-machine-learning-fall-2006/index.htm
加州理工学院(Caltech)的《机器学习与数据挖掘》在线课程
http://work.caltech.edu/telecourse.html(同上述网易公开课http://v.163.com/special/opencourse/learningfromdata.html)
UC Irvine的《机器学习与数据挖掘》在线课程
http://sli.ics.uci.edu/Classes/2011W-178
斯坦福大学的《数据挖掘》在线课程
http://www.stanford.edu/class/stats202/
其他资源
北京机器学习读书会
http://q.weibo.com/1644133
机器学习相关电子书
http://t.cn/zjtPuCS(打开artificial intelligence找子目录machine learning)
附:
主讲教师介绍:(新浪公开课:机器学习http://open.sina.com.cn/course/id_280/)
讲师:Andrew Ng
学校:斯坦福
斯坦福大学计算机系副教授,人工智能实验室主任,致力于人工智能、机器学习,神经信息科学以及机器人学等研究方向。他和他的学生成功开发出新的机器视觉算法,大大简化了机器人的传感器系统。
分享丨李飞飞、吴恩达、Bengio等人的顶级深度学习课程
2018年01月25日 00:00:00 人工智能爱好者俱乐部 阅读数:2626

目前,深度学习和深度强化学习已经在实践中得到了广泛的运用。整理了深度学习和深入强化学习相关的在线课程,其中包括它们在自然语言处理(NLP),计算机视觉和控制系统中的应用教程。
吴恩达:深度学习专项
这系列课程侧重于讲解深度学习的基础和在不同领域的运用方式,如医疗健康,自动驾驶,手语阅读,音乐生成和自然语言处理等。课程共包含五个子课程,有视频讲座。同时,课程用户将获得使用TensorFlow解决实际问题的实践经验。
链接:https://www.coursera.org/specializations/deep-learning
CMU: 深度学习
该课程由苹果人工智能研究所主任Ruslan Salakhutdinov主导。课程首先讲解了一些例如前馈神经网络、反向传播、卷积模型等的基本知识。然后介绍深度学习中的要点,包括有向图和无向图模型,独立成分分析(ICA),稀疏编码,自动编码器,限制玻尔兹曼机(RBM),蒙特卡罗方法,深度信念网络,深度玻尔兹曼机和亥姆霍兹机。其他内容包括深度网络中的正则化和优化、序列建模和深度强化学习。
链接:http://www.cs.cmu.edu/~rsalakhu/10707/
斯坦福大学:深度学习理论(Stat385)
本课程讨论深度学习理论方面的知识。有8次特邀嘉宾讲座,这些嘉宾是深度学习、计算神经科学和统计学方面的领军人物。您将有机会在深度学习中,针对当前的研究趋势,探索他们观点的多样性和跨学科性。这门课有视频讲座。
链接:https://stats385.github.io/
Yoshua Bengio: 深度学习
该课程由蒙特利尔大学主导。课程首先回顾了神经网络的基本知识,包括感知器,反向传播算法和梯度优化。然后介绍了神经网络、概率图形模型、深度网络和表示学习等前沿知识。
链接:https://ift6266h16.wordpress.com/
UC Berkeley: 深度强化学习
该课程包括强化学习的基本知识:Q-学习和策略梯度,同时还包含了高级模型学习和预测、提取、奖励学习以及高级深度强化学习,例如信赖域策略梯度方法、actor-critic方法、探索方法。本门课有视频讲座。
链接:http://rll.berkeley.edu/deeprlcourse/
Google & Udacity: 深度学习
该课程由谷歌首席科学家Vincent Vanhoucke和Udacity的Arpan Chakraborty共同创立。课程内容包括深度学习、深层神经网络、卷积神经网络和针对文本和序列的深层模型。课程作业要求使用tensorflow。这门课有视频讲座。
链接:https://cn.udacity.com/course/deep-learning--ud730
斯坦福大学:基于深度学习的自然语言处理(CS224n)
该课程是2017年冬斯坦福大学 “cs224n:深度学习中的自然语言处理”课程的压缩版,也是斯坦福大学2018课程的延续版。课程讨论了如何将深度学习应用在自然语言处理中,自然语言处理中的问题以及在自然语言处理中使用深度学习的限制。讲师有Christopher Manning和Richard Socher。
链接:https://www.youtube.com/playlistlist=PL3FW7Lu3i5Jsnh1rnUwq_TcylNr7EkRe6
牛津大学:自然语言处理中的深度学习
本课程涵盖深度学习的基本原理以及如何将其应用在自然语言处理中。用户将学习如何定义这个领域中的数学问题,以及获得使用CPU和GPU的实际编程的经验。讲师分别来自牛津大学、CMU、DeepMind和英伟达公司。 这门课程包括视频讲座。
链接:https://github.com/oxford-cs-deepnlp-2017/lectures
李飞飞:视觉识别中的卷积神经网络(cs231n)
本课程将涵盖深度学习的基础知识,以及如何将深度学习技术应用于计算机视觉。学生将通过作业和最终项目获得如何训练和微调神经网络的实践经验。该课程主要使用Python语言。本课程包括视频讲座。
链接:http://cs231n.stanford.edu/
CMU: 深度学习入门
本课程由苹果公司人工智能研究所主任Ruslan Salakhutdinov主导,对深度学习做了一个快速而深入的介绍。课程共分为四个一小时时长的视频讲座,涵盖了监督学习,无监督学习,以及深度学习中的模型评估和开放式的研究问题等内容。
链接:https://simons.berkeley.edu/talks/tutorial-deep-learning
RLDM: 深度强化学习入门
课程由DeepMind的David Silver主导,发表于第二届强化学习与决策多学科会议(RLDM)上。在这一个半小时的视频教程中,用户将了解深度学习,强化学习的基本原理,以及如何将深度学习和强化学习以各种方式结合:即深度价值函数,深度策略,和深度模型。此外,用户还能向顶级专家学习如何处理这些方法中的发散问题。
链接:http://videolectures.net/rldm2015_silver_reinforcement_learning/
UC Berkeley: 深度强化学习入门
这是一个关于强化学习长达一小时的教程,配有视频讲座。用户将看到强化学习能有多厉害。
链接:https://simons.berkeley.edu/talks/pieter-abbeel-2017-3-28
MLSS: 深度强化学习入门
课程由OpenAI公司的研究科学家John Schulman主导,包括4个1小时长的视频讲座,并带有针对实验室问题的练习。
链接:https://www.youtube.com/playlistlist=PLjKEIQlKCTZYN3CYBlj8r58SbNorobqcp