以武会友,两大主流联邦学习产品体验
如今,AI技术在几乎每个行业中都展现出了自己的优势,无人驾驶汽车,医疗保健,互联网金融等已经深入我们的生活。然而随着大数据和AI技术的逐渐成熟,各机构和组织对数据安全和用户隐私的妥协意识也日益增强,对数据隐私和安全的重视已成为全球性的重要问题。同时欧盟于2018年5月25日发布实施了《通用数据保护条例》 [GDPR], 旨在保护用户的个人隐私和数据安全,中国和美国也正在制定类似的隐私和安全法案。受此影响,国内外多方安全计算产业化应用的步伐明显加快。在国外产品创新活跃的同时,国内多方安全计算的技术产品蓬勃发展,已经形成了一定的优势。
纵览国内外,不乏一些优秀的产品和系统,早在2016年谷歌公司就提出了联邦学习的概念,经过多轮的打磨推出了TensorFlow Federated;英伟达公司也在NVIDIA NGC-Ready 服务器上开发了用于分布式协作联邦学习训练的Clara FL;国内也有许多优秀的学者先驱,其中既有老牌的技术大厂,也有新晋的优秀团队,共同在这条赛道驰骋,为隐私计算、安全建模不断添砖加瓦。
据笔者了解,国内市场已有如下公司各自推出了相关的产品:
- FATE:微众银行AI团队推出的工业级联邦学习框架
- MORSE:蚂蚁区块链打造的数据安全共享基础设施
- PrivPy:华控清交研发的安全多方计算平台
- FMPC:富数科技推出的私有化部署联邦建模平台
- 蜂巢系统:平安科技自主研发的联邦智能系统
- 点石平台:百度研发的可信云端计算及联合建模平台
本文优先选择FATE、FMPC两款产品,从产品界面、性能、使用方法等方面与大家进行分享。其他平台分析及使用我们将在后续系列文章更新,感兴趣的同学可持续关注。
本次将从系统架构、数据管理,模型训练,模型预测,性能评估五个方面依次进行介绍:
一、FATE联邦学习框架 – v1.2
1、系统架构:
1)FATE技术架构如(图1)所示,部分模块简介如下:
- EggRoll:分布式计算和存储的抽象;
- Federated Network:跨域跨站点通信的抽象;
- FATE FederatedML:联邦学习算法模块,包含了目前联邦学习所有的算法功能;
- FATE-Flow | FATE-Board:完成一站式联邦建模的管理和调度以及整个过程的可视化;
- FATE-Serving:联邦学习模型API模块。
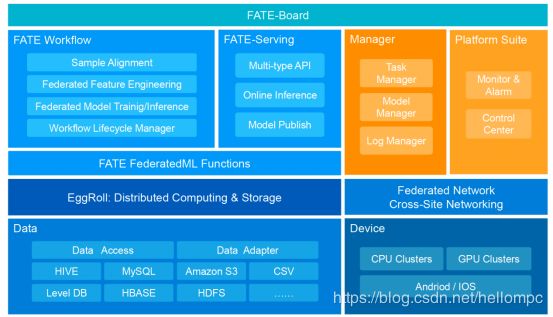
(图1)
2、数据管理
1)FATE执行上传文件需要编辑上传数据配置upload_load_role.json(图2):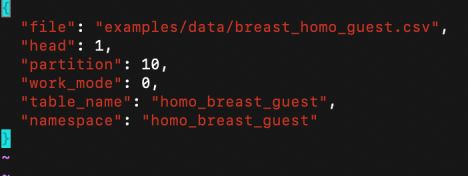
再执行如下命令,将文件上传到dataio组件:
3、模型训练:
1) FAETE 运行job主要通过fate_flow模块来完成,fate_flow是联邦学习模块运行和管理的主要模块,用于提交任务、解析参数、生成并执行job、保存和查询日志等功能;一个典型的fate_flow : (图3)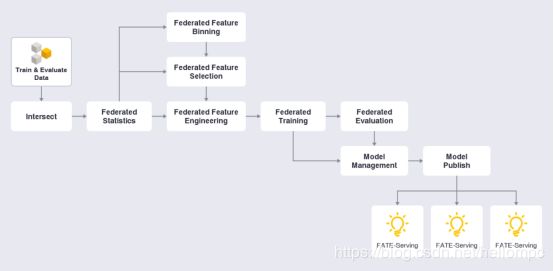
(图3)
Job需通过执行fate_flow_client命令进行提交,命令需要提供两个参数文件,一个是DSL文件,另一个是conf配置文件。DSL文件将诸如数据输入、功能设计和分类/回归模块等组件,组合为有向无环图(DAG);conf文件对运行的算法组件相关参数信息进行配置,如逻辑回归中的学习率,树模型中的最大深度等。
配置文件后在fate_flow文件目录下执行如下命令开始任务:
python fate_flow_client.py -f submit_job -d examples/test_hetero_lr_job_dsl.json -c examples/test_hetero_lr_job_conf.json
执行任务后可在FATE-Board面板查看任务信息及相关日志。(图4)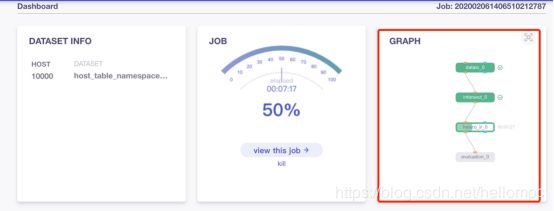
(图4)
4、模型预测
1) FATE进行模型预测前需要通过命令行根据jobid读取model_id及model_version:
python ${your_fate_install_path}/fate_flow/fate_flow_client.py -f job_config -j ${jobid} -r guest -p
然后编写预测配置文件test_predict_conf.json: (图5)
(图5)
最后使用如下命令进行预测,预测结果可在FATE-Board通过job_id进行查看;
python ${your_fate_install_path}/fate_flow/fate_flow_client.py -f submit_job -c ${predict_config}
二、FMPC联邦建模平台 – v1.4.1
1、系统架构
技术架构如(图6)所示,部分模块简介如下: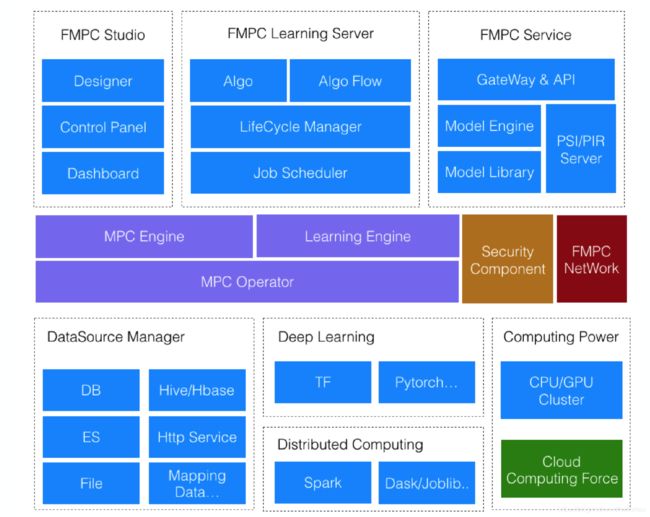
(图6)
2、数据管理
FMPC上传文件有四种方式,分别为本地csv、url、DB数据库、接口方式,以csv文件为例(图7),通过页面点选欲上传的本地文件路径,并填入文件相关信息,配置权限: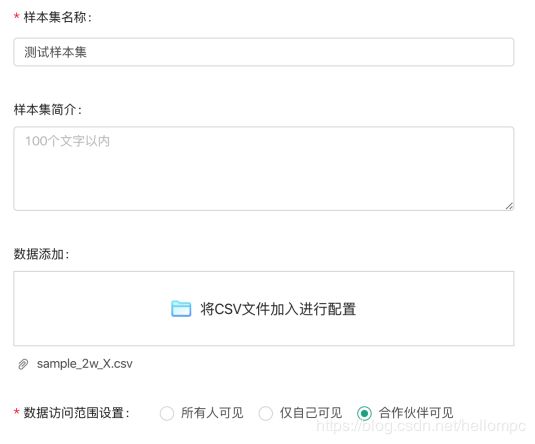
(图7)
3、模型训练
FMPC通过项目的形式建立模型训练任务,项目中通过点选的方式进行包含数据融合/探索分析/特征工程/数据建模/模型评估等一系列操作,如下是FMPC的建模流程图(图8):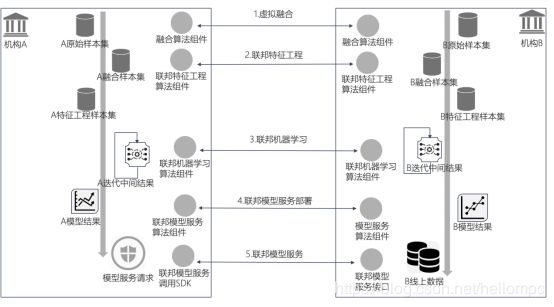
(图8)
创建项目后先将要使用的数据加入到项目中,进行数据虚拟融合(利用不经意传输机制进行的加密数据对齐):
(图9)
在数据虚拟融合后可以进行数据分析及特征筛选等操作(图10):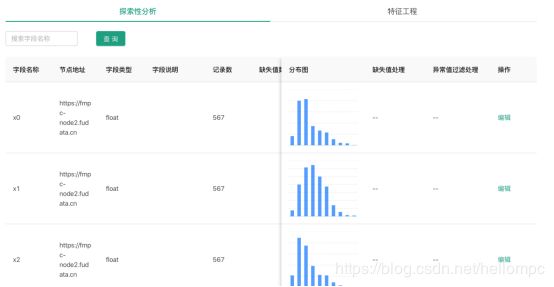
(图10)
探索性分析可以查看并处理缺失值及异常值,特征工程可以进行特征分箱(可选分箱方式:等距/等频/卡方/自定义分箱),并查看对应WOE及IV值:(图10)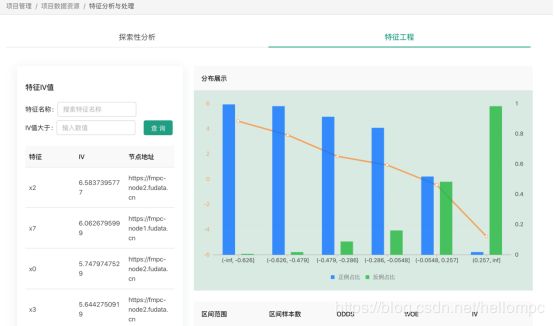
(图11)
进行特征分析及特征筛选后可以选择一种联邦机器学习方法进行建模,并在相同界面查看学习进度及日志:(图12)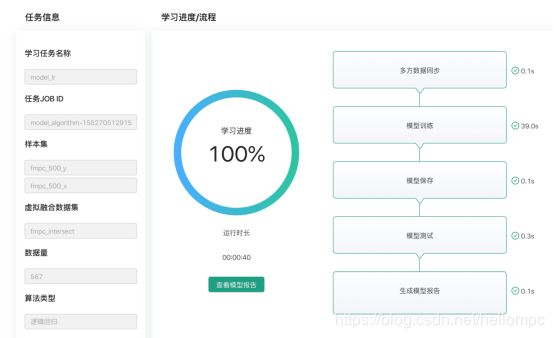
(图12)
4、模型预测
2)FMPC在模型创建后可通过点选配置对应数据资源并发送合作节点进行审核,合作节点审核通过后即可生成模型api进行持续调用,调用接口如(图13)所见:
(图13)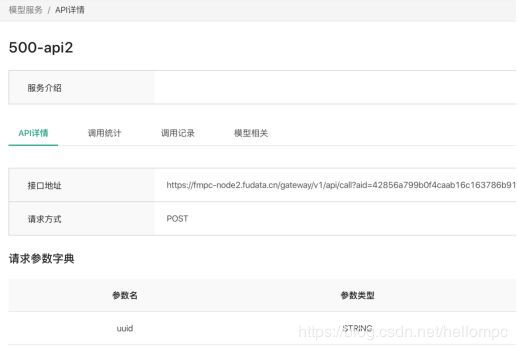
(图14)
5、性能评估:
为了模拟真实业务场景,本次测试准备了如下两份样本:
样本A:两万行数据,1列索引列字段,26个特征字段
样本B:两万行数据,1列索引列字段,1列目标值字典,2个特征字段
在同等环境下同时部署FATE/FMPC两套产品,每次运行任务只独立运行其中一款,得到指标如下: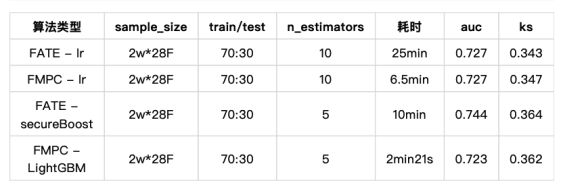
注:n_estimators在lr中代表迭代次数,在树模型中代表树棵树
结果分析
根据以上两款产品使用流程可以看出,两款产品均实现并完成安全建模的闭环流程,但在某些方面还存在一定差异。
1)产品角度:FATE更偏向于面向技术人员,使用者需要具有一定开发能力及算法功底;FMPC更偏向于面向业务人员,使之能在清晰的界面可视化操作。
2)功能健全程度:FATE具有基本建模功能,包括数据上传,模型训练,模型评估,模型预测;FMPC在此基础上添加了特征分析及特征筛选功能,更贴近实际业务场景需求。
3)性能角度:FATE的secureBoost较lr相比训练速度更快,模型精度更高,运行时间在业内属于可接受范围;FMPC与之相比,开创性地采用“松弛迭代法“,在保持精度和准确性的同时,速度提升了3倍左右,在实际业务的多次的迭代和调参中会有较明显的优势。
总体来讲FATE虽是如下安全建模中较为知名的产品,其技术方案值得业内认可;但也不乏一些新星产品做出了属于自己的特色,可能未来将会有更多优秀的产品面世,相互竞争,共同进步,在数据安全领域大放异彩。