【16】Flink 之 EventTime 和 Watermark 结合使用解决乱序数据
1、Watermark 使用分析
对于解决乱序数据问题,需要EventTime 和 Watermarks结合使用。
由【15】Flink 之 Time & EventTime & Watermarks可知,Watermarks有两种生成方式,其中With Periodic Watermarks较为常用,采用该方式进行分析。
需要实现接口AssignerWithPeriodicWatermarks,下面是官网使用方法代码示例:

其中:
- extractTimestamp 方法是从数据本身中提取EventTime
- getCurrentWatermar 方法是获取当前水位线
- maxOutOfOrderness 表示是允许数据的最大乱序时间
2、实现watermark
2.1、程序功能
从socket 模拟接收数据, 然后使用map 进行处理, 后面再调用assignTimestampsAndWatermarks 方法抽取timestamp 并生成watermark。最后再调用window打印信息来验证window 被触发的时机。
2.2、程序说明
- 接收socket 数据
// 连接socket获取输入的数据
DataStream<String> text = env.socketTextStream("master", port, "\n");
- 将每行数据按照逗号分隔,每行数据调用map 转换成tuple
// 解析输入的数据
// 输入:0001,1559703420000
// 其中,0001 代表具体的数据,1559703420000 代表数据的 EventTime
// 输出:(0001,1559703420000)
DataStream<Tuple2<String, Long>> inputMap = text.map(
new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String value) throws Exception {
String[] arr = value.split(",");
return new Tuple2<>(arr[0], Long.parseLong(arr[1]));
}
});
- 抽取timestamp , 生成watermar , 允许的最大乱序时间是10s , 并打印
(key,eventtime,currentMaxTimestamp,watermark)等信息
inputMap.assignTimestampsAndWatermarks(
new AssignerWithPeriodicWatermarks<Tuple2<String, Long>>() {
Long currentMaxTimestamp = 0L; // 当前最大时间戳
final Long maxOutOfOrderness = 10000L;// 最大允许数据的乱序时间是10s
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
/**
* 定义生成watermark的逻辑
* 默认100ms被调用一次
* getCurrentWatermark()方法是获取当前水位线
*/
@Nullable
@Override
public Watermark getCurrentWatermark() {
return new Watermark(currentMaxTimestamp - maxOutOfOrderness);
}
// 定义如何提取timestamp
@Override
public long extractTimestamp(Tuple2<String, Long> element, long previousElementTimestamp) {
long timestamp = element.f1; // 获取时间戳
currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp); // 求当前最大时间戳
long id = Thread.currentThread().getId();
System.out.println("currentThreadId:"+id+",key:"+
element.f0+",eventtime:["+element.f1+" | "+
sdf.format(element.f1)+"],currentMaxTimestamp:["+currentMaxTimestamp+" | "+
sdf.format(currentMaxTimestamp)+"],watermark:["+getCurrentWatermark().getTimestamp()+" | "+
sdf.format(getCurrentWatermark().getTimestamp())+"]");
return timestamp;
}
});
- 分组聚合,window 窗口大小为3 秒,输出(key,窗口内元素个数,窗口内最早元素的时间,窗口内最晚元素的时间,窗口自身开始时间,窗口自身结束时间)
waterMarkStream.keyBy(0)
// 设置窗口 3 秒一个
.window(TumblingEventTimeWindows.of(Time.seconds(3))) //按照消息的EventTime分配窗口,和调用TimeWindow效果一样
.apply(new WindowFunction<Tuple2<String, Long>, String, Tuple, TimeWindow>() {
@Override
public void apply(Tuple tuple, TimeWindow window,
Iterable<Tuple2<String, Long>> input, Collector<String> out)
throws Exception {
String key = tuple.toString(); // 数据值,如输入数据中的 1
List<Long> arrarList = new ArrayList<Long>(); // 包含是数据数组
Iterator<Tuple2<String, Long>> it = input.iterator();
while (it.hasNext()) {
Tuple2<String, Long> next = it.next();
arrarList.add(next.f1);
}
Collections.sort(arrarList);
String result = ..... // 拼装打印结果字符串
....
out.collect(result);
}
});
2.3、运行数据查看watermark
通过查看watermark 和timestamp 的时间,通过数据的输出来确定window 的触发条件。
通过ncat开启socket的9003端口,发送一条数据,数据格式为:key,timestamp。其中,key代表实际具体数据的值,timestamp代表时间戳,即事件产生事件 Event Time。

输出结果为:
![]()
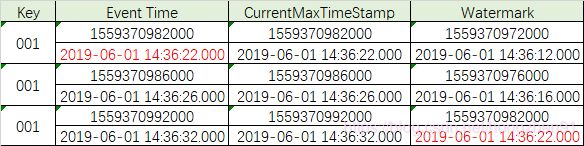
时间戳1559370982000对应的时间为2019-06-01 14:36:22.000,讲数据输入关系通过表格进行呈现便于查看,如下:

此时,wartermark 的时间秒为,已经落后于currentMaxTimestamp10 秒。我们继续输入一条数据:
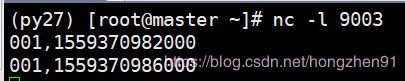
控制台打印输出内容为:
![]()
此时,并没有触发windows窗口执行输出,数据结果表格如下:

第二条数据输入的时间是26秒,再输入一条42秒的数据,如下:
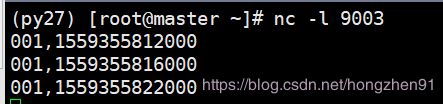
输出内容和表格整理数据如下:
![]()
此时,仍未触发window执行,由第三条数据内容可知,此时的 watermark 的时间已经上升到了等于等一条数据的 Event Time 了。继续输入一条33秒的数据,输入如下:
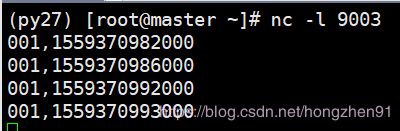
控制台输出:

输出数据表格:

此时,watermar 的时间秒数为23秒,已经超过第一条数据的Event Time时间11秒,但是windows仍然没有执行输出,再继续数据一条增加1秒的数据,即输入一条34秒的数据,如下:
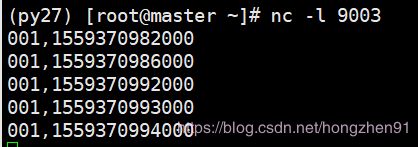
控制台输出:

输出数据表格:
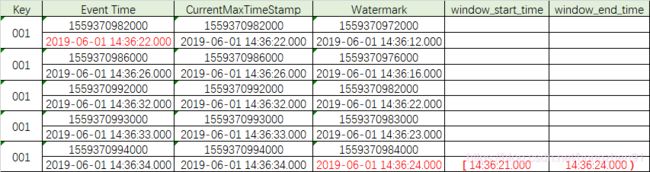
此时,在输入34秒数据的时候触发执行了window,window的触发机制如下:
先是按照自然时间将window划分,在程序中设置了window执行窗口大小为3秒,即每3秒划分一个窗口,对于1分钟的时间会按以下方式对window进行划分,区间形式为左闭右开:
| window 划分机制 |
|---|
| [ 00:00:00,00:00:03 ) |
| [ 00:00:03,00:00:06 ) |
| [ 00:00:06,00:00:09 ) |
| … |
| [ 00:00:18,00:00:21 ) |
| [ 00:00:21,00:00:24 ) |
| [ 00:00:24,00:00:27 ) |
| … |
| [ 00:00:57,00:01:00 ) |
| … |
window 的大小是由程序中定义的,定义如下:
// 设置窗口 3 秒一个
.window(TumblingEventTimeWindows.of(Time.seconds(3))) //按照消息的EventTime分配窗口
输入的数据中的时间是数据本身的产生时间,即 Event Time,根据数据的时间会被划分到不同的 window 窗口中,如果当 window 窗口中有数据,并且满足 window 的触发条件时,则会执行 window 操作,对该 window 中的数据进行处理,但是最终决定 window 是否触发,是由数据的 Event Time 所属的 window 中的 window_end_time 决定的。
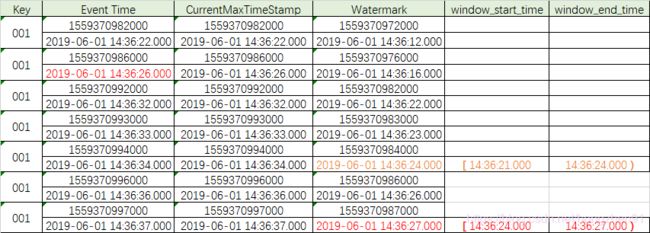
通过上述数据可知,最后一条数据达到后,watermark 水位线上升到了 24 秒,同时结合 window 划分机制可知,第一条数据所在的 window 区间是 [ 00:00:00,00:00:03 ),所以 window 就被触发执行了。
可以通过继续输入数据验证 window 触发机制,输入数据如下:
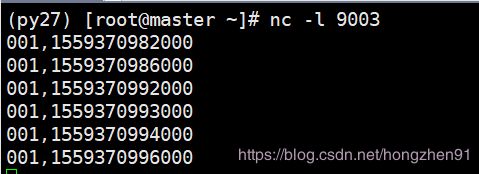
输出:

输出数据表格:
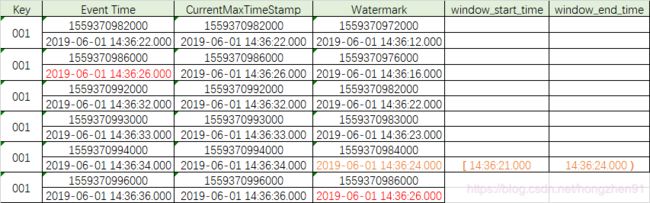
此时,watermark 时间虽然已经达到了第二条数据的时间,但是由于其没有达到第二条数据所在window 的结束时间,所以window 并没有被触发。那么,第二条数据所在的window时间是: [ 00:00:24,00:00:27 ) 。
通过上述结论,需要再次输入一条大于27秒的数据,第二条数据所在的 window 才会触发执行,输入数据如下:
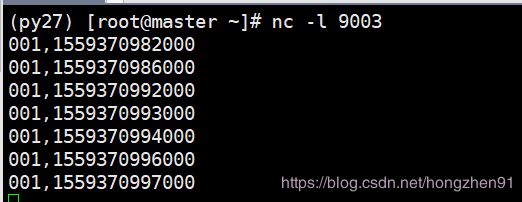
输出:

输出数据表格:
通 过 上 述 测 试 , 可 得 w i n d o w 触 发 条 件 : \color{red}{通过上述测试,可得 window 触发条件:} 通过上述测试,可得window触发条件:
1. watermark 时间 >= window_end_time
2. 在[window_start_time,window_end_time)区间中有数据存在,注意是左闭右开的区间
同时满足了以上2 个条件,window 才会触发。
2、watermark + window 处理乱序数据
上面的测试,数据都是按照时间顺序递增的,现在,我们输入一些乱序的(late)数据,看看watermark 结合window 机制,是如何处理乱序的。
输入两行数据:
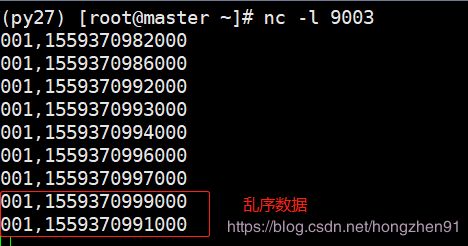
输出:

输出数据表格:

通过输入的39秒和31秒的两条乱序数据可知,虽然输入了一个31秒的数据,但是currentMaxTimestamp 和watermark都没变。此时,结合上一节归纳的 window 触发机制:
- watermark 时间>= window_end_time
- 在[window_start_time,window_end_time)中有数据存在
watermark 时间(14:36:29) < window_end_time(14:36:33),因此不能触发window。
此时,再次输入一条43秒的数据,使得水位线 watermark 可以上升到 33 秒,从而触发 window 执行,输入如下:
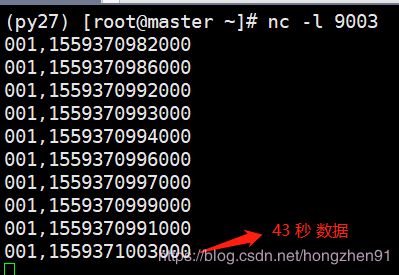
输出:

输出数据表格:
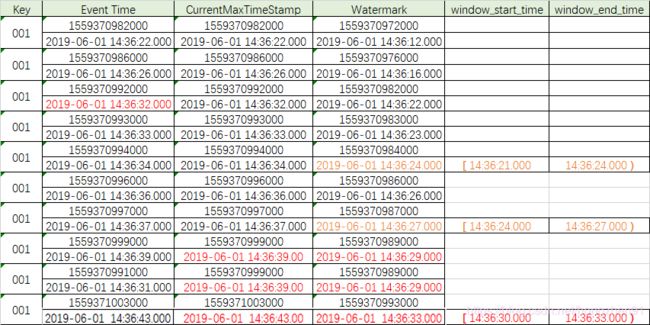
由上输出数据表格可以看到,窗口中有 2 个数据,14:36:31 和14:36:32,但是没有14:36:33 的数据,原因是窗口是一个前闭后开的区间,14:36:31 的数据是属于 [ 14:36:33 , 14:36:36 ) 的窗口的。
通过实验结果表明,对于out-of-order 的乱序数据,Flink 可以通过watermark 机制结合window的操作,来处理一定范围内的乱序数据。
4、late element(延迟数据)的处理
水位线 watermark 设置了允许最大乱序时间,即数据可以晚到的时间,如果在 watermark 设置的时间内数据还是没有能够到达,则为late element(延迟数据),针对延迟数据通常有三种处理方法。
4.1、丢弃数据(默认)
输入一个乱序很多的( 其实只要Event Time < watermark 时间 )数据来测试下:
输入【两条数据】:

输出:
![]()
输出数据表格:

Attention: 此时的 watermark 值是 1559371773000,即 2019-06-01 14:49:33.000
下面再输入几组 eventtime < watermark 的时间的数据
输入【三条数据】:

输出:

此时并没有触发window。因为输入的数据所在的窗口已经执行过了,flink 默认对这些迟到的数据的处理方案就是丢弃。
4.2、allowedLateness 指定允许数据延迟的时间
在某些情况下,希望对迟到的数据再提供一个宽容的时间。也就是说,水位线 watermark 提供了一个允许数据最大乱序时间,如果在这个时间内,乱序数据还没有能够到达的话,可以再提供一个时间,如果这个时间内数据到了也是可以的。Flink 提供了allowedLateness 方法可以实现对迟到的数据设置一个延迟时间,在指定延迟时间内到达的数据还是可以触发window 执行的。
采用allowedLateness 需要对代码进行修改:

DataStream<String> window = waterMarkStream.keyBy(0)
// 设置窗口 3 秒一个
.window(TumblingEventTimeWindows.of(Time.seconds(3))) //按照消息的EventTime分配窗口,和调用TimeWindow效果一样
.allowedLateness(Time.seconds(2))//允许数据迟到2秒
...
输入【两条数据】:

输出:
![]()
输出数据表格:
结果同上,正常触发 window 执行。
此时 watermark 是 2019-06-01 14:49:33.000
那么现在再输入几条 eventtime < watermark 的数据验证一下效果。
输入【三条数据】:

输出:

从输出可以看到,后面输入的 30、31、32 秒的三条数据,每条都触发了 window 执行操作。
输出数据表格:
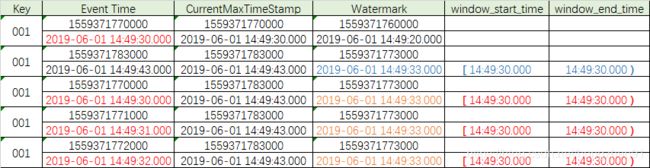
再输入一条数据,把 watermark 调整到14:36:34。
输入:
输出:

输出数据表格:

此时,把 watermark 上升到了34秒,再输入几条 eventtime < watermark 的数据验证一下效果
输入:

输出:
输入的三行数据都触发了window 的执行。
再输入一条数据,把 watermark 调整到 35 秒。
输入:

输出:
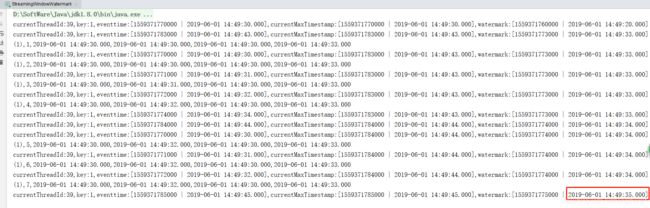
此时,watermark 上升到了 35 秒,再输入几条 eventtime < watermark 的数据验证一下效果。
输入:

输出:

此时,发现这几条数据都没有触发window。
分析:
- 当 watemark 等于14:49:33 的时候,正好是 window_end_time,所以会触发 [14:49:30 , 14:49:33) 的 window 执行。
- 当窗口执行过后,我们输入 [14:49:30 , 14:49:33) window 内的数据会发现 window 是可以被触发的。
- 当watemark 提升到 14:49:34 的时候,输入 [14:49::30 , 14:49:33) window 内的数据会发现window 也是可以被触发的。
- 当watemark 提升到 14:49:35 的时候,输入 [14:49::30 , 14:49:33) window 内的数据会发现 window 不会被触发了。
由于在前面程序中设置了allowedLateness(Time.seconds(2)),可以允许延迟在2s 内的数据继续触发window 执行。
总结:
对于此窗口而言,允许2 秒的迟到数据,即第一次触发是在 watermark >=window_end_time 时,第二次(或多次)触发的条件是 watermark < window_end_time + allowedLateness 时间内,这个窗口有 late 数据到达时。
解释:
- 当 watermark 等于 14:49:34 的时候,输入 eventtime 为 14:49:30、14:49:31、14:49:32 的数据的时候,是可以触发的,因为这些数据的 window_end_time 都是 14:49:33,也就是 14:49:34 < 14:49:33+2 为 true。
- 当 watermark 等于 14:49:35 的时候,再次输入 eventtime 为 14:49:30、14:49:31、14:49:32 的数据的时候,这些数据的window_end_time 都是14:49:33,此时,14:49:35 < 14:49:33+2 为 false 。所以最终这些数据迟到的时间太久了,就不会再触发window 执行。
4.3、sideOutputLateData 收集迟到的数据
通过sideOutputLateData 可以把迟到的数据统一收集,统一存储,方便后期排查问题。采用sideOutputLateData 需要修改代码:

//保存被丢弃的数据
OutputTag<Tuple2<String, Long>> outputTag = new OutputTag<Tuple2<String, Long>>("late-data"){};
//注意,由于getSideOutput方法是SingleOutputStreamOperator子类中的特有方法,所以这里的类型,不能使用它的父类dataStream。
SingleOutputStreamOperator<String> window = waterMarkStream.keyBy(0)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))//按照消息的EventTime分配窗口,和调用TimeWindow效果一样
//.allowedLateness(Time.seconds(2))//允许数据迟到2秒
.sideOutputLateData(outputTag)
.apply(new WindowFunction<Tuple2<String, Long>, String, Tuple, TimeWindow>() {
/**
* 对window内的数据进行排序,保证数据的顺序
* @param tuple
* @param window
* @param input
* @param out
* @throws Exception
*/
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable<Tuple2<String, Long>> input, Collector<String> out) throws Exception {
String key = tuple.toString();
List<Long> arrarList = new ArrayList<Long>();
Iterator<Tuple2<String, Long>> it = input.iterator();
while (it.hasNext()) {
Tuple2<String, Long> next = it.next();
arrarList.add(next.f1);
}
Collections.sort(arrarList);
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS");
String result = key + "," + arrarList.size() + "," + sdf.format(arrarList.get(0)) + "," + sdf.format(arrarList.get(arrarList.size() - 1))
+ "," + sdf.format(window.getStart()) + "," + sdf.format(window.getEnd());
out.collect(result);
}
});
//把迟到的数据暂时打印到控制台,实际中可以保存到其他存储介质中
DataStream<Tuple2<String, Long>> sideOutput = window.getSideOutput(outputTag);
...
输入:
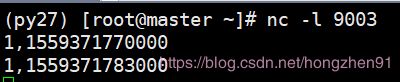
输出:

此时,window 被触发执行了,此时 watermark 是 14:49:33 ,输入几个 eventtime < watermark 的数据测试一下.
输入:
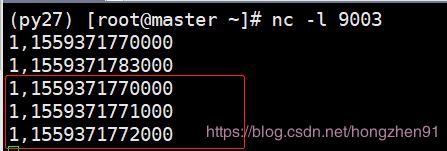
输出:

此时,针对这几条迟到的数据,都通过sideOutputLateData 保存到了outputTag 中。
5、在多并行度下使用 watermark
以上实现的 watermark 的前提均是通过全局设置了并行度为1,即:
env.setParallelism(1);
如果这里设置的并行度不为1,或者没有设置并行度的情况下,则情况就会不同,如将并行度改为4:
env.setParallelism(8);
通过线程 id 观察程序执行情况:
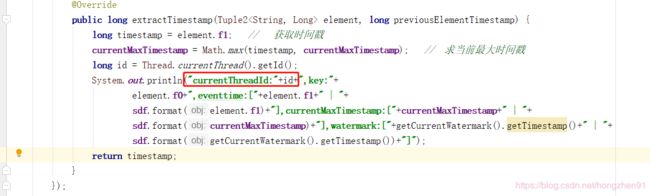
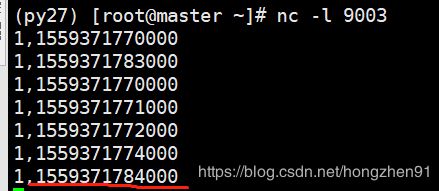
输入【7条数据】:

输出:

通过控制台打印输出可知,此时并没有触发 window 。因为,这 7 条数据都是被不同的线程处理的。每个线程都有一个watermark 。在多并行度的情况下,watermark 对齐会取所有 channel 最小的 watermark 。
但是现在设置了 8 个并行度,这 7 条数据都被不同的线程所处理,到现在还没获取到最小的 watermark,所以window 无法被触发执行。多并行度下 watermark 机制如下图所示:

下面把代码中的并行度调整为2:
env.setParallelism(2);
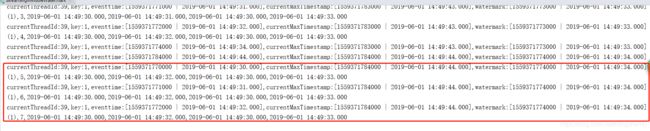
输入如下内容:

输出:
![]()
此时会发现,当第三条数据输入完以后, [14:49:30 , 14:49:33) 这个 window 被触发了。前两条数据输入之后,获取到的最小 watermark 是 14:49:20,这个时候对应的window 中没有数据。第三条数据输入之后,获取到的最小 watermark 是14:49:30,这个时候对应的窗口就是 [14:49:30 , 14:49:33),所以就触发执行。
下一篇:【17】Flink 之 并行度(Parallel)及设置