CUDA中Block大小的选择
这里介绍两种比较官方的做法,这两种做法的原理是一致的,都是基于SM占用率最大化的原则。
API函数--cudaOccupancyMaxPotentialBlockSize
从CUDA6.5开始,提供了一个很有用的函数cudaOccupancyMaxPotentialBlockSize,该函数定义在cuda_runtime.h,定义如下:
template
__inline__ __host__ CUDART_DEVICE cudaError_t cudaOccupancyMaxPotentialBlockSize(
int *minGridSize,
int *blockSize,
T func,
size_t dynamicSMemSize = 0,
int blockSizeLimit = 0)
{
return cudaOccupancyMaxPotentialBlockSizeVariableSMem(minGridSize, blockSize, func, __cudaOccupancyB2DHelper(dynamicSMemSize), blockSizeLimit);
}
//The meanings for the parameters is the following
minGridSize = Suggested min grid size to achieve a full machine launch.
blockSize = Suggested block size to achieve maximum occupancy.
func = Kernel function.
dynamicSMemSize = Size of dynamically allocated shared memory. Of course, it is known at runtime before any kernel launch. The size of the statically allocated shared memory is not needed as it is inferred by the properties of func.
blockSizeLimit = Maximum size for each block. In the case of 1D kernels, it can coincide with the number of input elements. 注意:对于二维数据,根据计算出的blocksize,自己调整为二维格式,例如blocksize=1024,则二维dim3 blocksize(32,32);
它可以计算出在SM占用率最大时blocksize的大小,可以根据此值配置Block。这样就可以不去关心各种硬件资源的限制,那确实是一件很麻烦的事情。下面是该函数的一个示例:
#include "cuda_runtime.h"
#include
/************************/
/* TEST KERNEL FUNCTION */
/************************/
__global__ void MyKernel(int *a, int *b, int *c, int N)
{
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) { c[idx] = a[idx] + b[idx]; }
}
/********/
/* MAIN */
/********/
void main()
{
const int N = 1000000;
int blockSize; // The launch configurator returned block size
int minGridSize; // The minimum grid size needed to achieve the maximum occupancy for a full device launch
int gridSize; // The actual grid size needed, based on input size
int* h_vec1 = (int*) malloc(N*sizeof(int));
int* h_vec2 = (int*) malloc(N*sizeof(int));
int* h_vec3 = (int*) malloc(N*sizeof(int));
int* h_vec4 = (int*) malloc(N*sizeof(int));
int* d_vec1; cudaMalloc((void**)&d_vec1, N*sizeof(int));
int* d_vec2; cudaMalloc((void**)&d_vec2, N*sizeof(int));
int* d_vec3; cudaMalloc((void**)&d_vec3, N*sizeof(int));
for (int i=0; i>>(d_vec1, d_vec2, d_vec3, N);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&time, start, stop);
printf("Kernel elapsed time: %3.3f ms \n", time);
printf("Blocksize %i\n", blockSize);
cudaMemcpy(h_vec3, d_vec3, N*sizeof(int), cudaMemcpyDeviceToHost);
for (int i=0; i 占用率计算器的方法
NVIDIA已经提供了一个很好的计算工具--CUDA_Occupancy_Calculator.xls,存放位置为C:\Program Files\NVIDIA GPUComputing Toolkit\CUDA\v7.5\tools,如下图所示。

该计算器的使用方法在help中,主要是填写绿框和橙色框中的内容,几点说明如下:
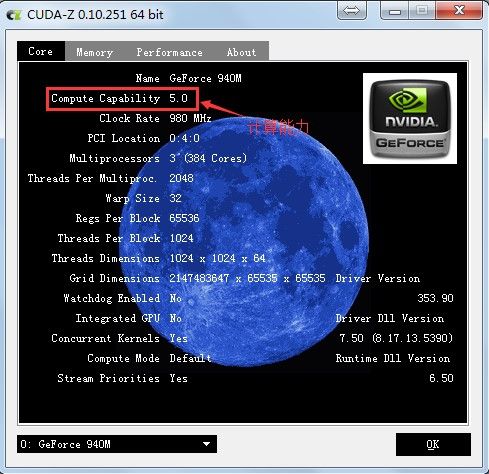
a.计算版本可以使用CUDA-Z软件进行查询,很小的软件,可以监控显卡的各种参数,软件界面如下:
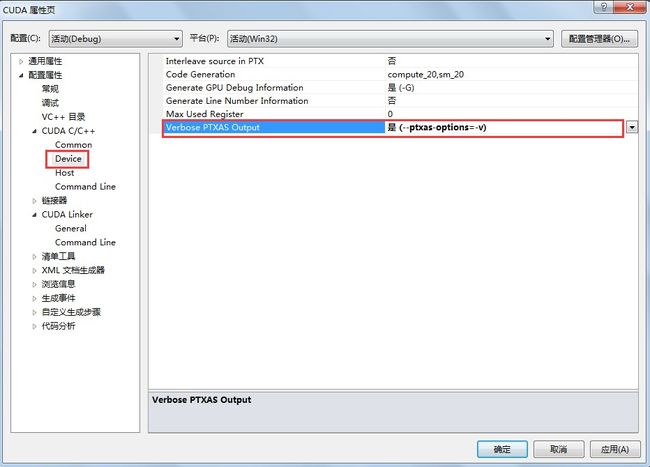
b. 使用编译指令”--ptxas-options=-v”查询Register和SharedMemory,操作如下:
以VS2010为例,首先打开Project属性,将“配置属性 -> CUDA C/C++ -> Device -> Verbose PTXAS Output”设置为“是”;
重新编译之后,即可在输出窗口看到类似下面的信息,
ptxas info : Compilingentry function '_Z8my_kernelPf' for 'sm_10'
ptxas info : Used 5registers, 8+16 bytes smem
可以看出本程序使用了5 个Register 和8+16 个Byte 的Shared Memory,但是如果程序在运行时还定义了2048 Byte 的external shared memory array,则总的Shared Memory 占用应当是2048+8+16=2072。将Register 和Shared Memory信息填入计算器中,即可看到计算器的计算结果,如下图所示。
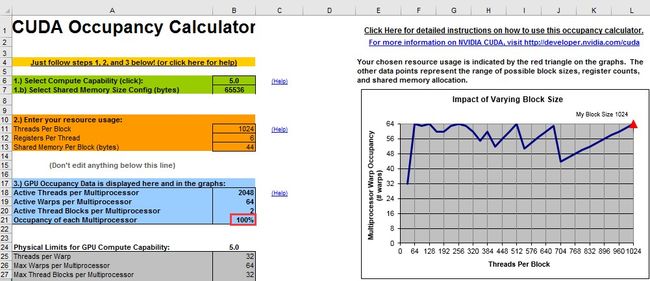
图中显示SM的占用率为100%,没有计算能力被浪费,说明这种配置是合理的。
参考文章:
[1] https://stackoverflow.com/questions/9985912/how-do-i-choose-grid-and-block-dimensions-for-cuda-kernels
[2] CUDA_Occupancy_Calculator.xls
[3] https://devblogs.nvidia.com/parallelforall/cuda-pro-tip-occupancy-api-simplifies-launch-configuration/
[4] http://bbs.csdn.net/topics/390756748