吴恩达深度学习课程疑难点笔记系列-结构化机器学习项目-第1周&第2周
本笔记系列参照吴恩达深度学习课程的视频和课件,并在学习和做练习过程中从CSDN博主何宽和博客园的博主marsggbo分享的文章中得到了帮助,再此表示感谢。
“结构化机器学习项目”这节课的主要学习的内容:介绍一些常用的机器学习项目策略,比如如何设置评估指标、划分数据集、如何分析误差以及定位误差产生的原因,另外也介绍了迁移学习、多任务学习、端到端深度学习的概念
这节课学习内容的主要疑难点:
一、如何设置指标
系统的指标一般有好几个,一般我们需要确认一个指标为优化指标(optimizing metric),其它为满足指标

图 1 图1 图1
图1中的例子中,我们可以看到,如果对模型运行的时间有限制,比如100ms以内,虽然C的准确率是最高的,但是它的运行时间超出了100ms,所以不应该采用,因此,A、B都满足时间限制指标,但B的准确率跟高,所以B更满足我们的要求。
这个例子中我们可以看出,准确率是系统的优化指标,而运行时间是系统的满足指标
有时候系统的数字指标很多,不知道如何做取舍,比如准确率和召回率
准确率(%)= T P ( 真 正 例 ) 预 测 为 “ 正 ” 的 样 本 数 \frac{TP(真正例)} {预测为“正”的样本数} 预测为“正”的样本数TP(真正例)= T P ( 真 正 例 ) T P ( 真 正 例 ) + F P ( 假 正 例 ) ∗ 100 \frac{TP(真正例)}{TP(真正例)+FP(假正例)}*100 TP(真正例)+FP(假正例)TP(真正例)∗100
召回率(%)= T P ( 真 正 例 ) 预 测 正 确 的 样 本 数 \frac{TP(真正例)}{预测正确的样本数} 预测正确的样本数TP(真正例)= T P ( 真 正 例 ) T P ( 真 正 例 ) + T F ( 真 负 例 ) ∗ 100 \frac{TP(真正例)}{TP(真正例)+TF(真负例)}*100 TP(真正例)+TF(真负例)TP(真正例)∗100
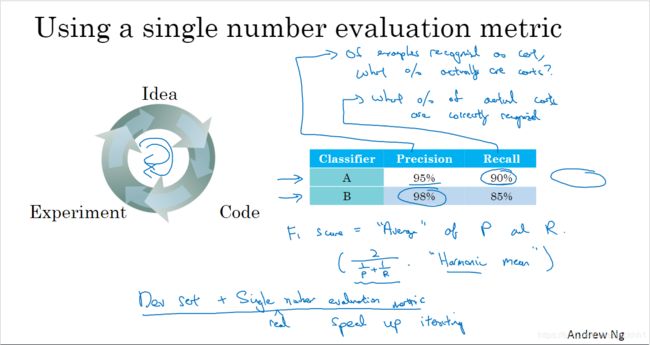
图 2 图2 图2
图2的示例中,针对准确率和召回率,分类器A和B各有一项指标优先于对方,我们该如何判断哪个分类器更好了?
可以用“F1 score”来表示:
F 1 = 2 1 P + 1 R , P , R 为 百 分 值 数 值 F1=\frac{2}{\frac{1}{P}+\frac{1}{R}},P,R为百分值数值 F1=P1+R12,P,R为百分值数值
因此,F1_A= 2 1 95 + 1 90 \frac{2}{\frac{1}{95}+\frac{1}{90}} 951+9012=0.924,F1_B= 2 1 98 + 1 85 \frac{2}{\frac{1}{98}+\frac{1}{85}} 981+8512=0.91,因为F1_A>F1_B,我们可以判断A分类器要优于B分类器。
二、如何划分数据集
这个知识点其实之前也提到过,一般我们把数据集(百万规模)划分为 training set\ development set \ test set ,其中training set 占98%,dev set 占1%,test set 占1%,这当中dev set和test set必须来自同一分布并且从所有数据中随机取出。
为什么要求dev set 和test set必须来自同一分布了?
那是因为我们设置dev set的初衷是用来在模型开发过程中及时验证模型能不能达到我们设置的单一数字指标的,为了在dev set上达到指标,我们可能会付出几个月的努力,而如果test set的数据不跟dev set 的数据同一分布,那我们的模型表现肯定会大幅降低,这样就白白浪费几个月的努力,太不值了!
划分数据集的时候还有个重要的点,就是如果模型投入使用后,接触的数据和训练时的数据有些不同的时候,我们该怎么划分数据集了?让我们看看图3和图4的PPT示例
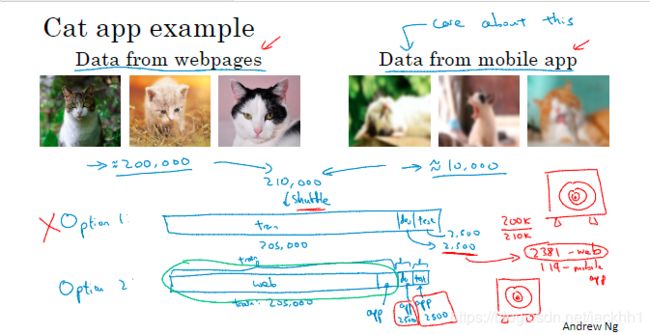
图 3 图3 图3
图3中,模型主要用来识别手机APP中用户拍的猫图片,这些图片它不是那么清晰,而且猫的姿态各异,我们获取用来做数据集的图片也比较少,月10000张,这点数据量明显不够,因此我们从网上下载了大概200 000张猫图片,那这两段数据集的分布就明显有些不同了,如果我们按“option 1”那样把这210 000张图片随机打乱,从中取205 000张作为训练集,2500张作为开发集,2500张作为测试集的话,我们的模型在开发集上进行评估时,实际上只有2381张手机侧的猫图片,这样就未达到开发集的目的,因为我们的模型最终用来识别手机APP中的猫图片,所以开发集的图片应该全部来自手机APP端,因此“option1”不行,我们要像“option2”那样将200 000张网络猫图片和5000张手机猫图片随机作为训练集,剩下5000张手机猫图片一分为二作为开发集和测试集,
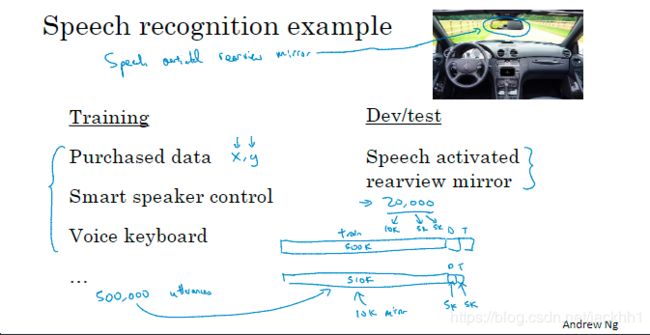
图 4 图4 图4
图4的示例跟图3中的类似,这是一个语音识别的案例,假如我们要做一个后视镜语音识别的产品,为使这个产品的模型达到要求,我们当然需要先获得足够多的数据,而从车载后视镜记录的语音激活、后视镜本地存储的数据20000条明显不够,我们需要购买数据或生产一些语音数据,大概500 000条,要怎么划分数据集好了?结合图3的示例,还是要把开发集和测试集优先保证全部为实际使用场景端的数据,训练集就由10000条真实场景端数据+500 000条购买收集的数据组成,开发集和测试集分别为5000条真实使用场景端的数据。
三、可避免偏差
首先我们要了解下什么是贝叶斯误差:在现有特征集上,任意可以基于特征输入进行随机输出的分类器所能达到的最小误差。这是一个无法求得的数值,因为求得贝叶斯误差的前提是我们知道真实分布,但机器学习根本不知道真实分布。
因此,对于一个猫图片识别模型来说,人类识别的误差几乎可以视为0,它也可视为等于贝叶斯误差
而对比人为误差,训练误差,开发误差
| 场景A | 场景B | |
|---|---|---|
| 人为误差 | 1% | 7.5% |
| 训练误差 | 8% | 8% |
| 开发误差 | 10% | 10% |
场景A中训练误差和人为误差有7%的差距,而开发误差与训练误差只有2%的差距,这个时候我们可以认为模型存在可避免偏差=7%,下一步我们就可以从增大神经网络结构或者训练更长时间的方向去考虑
场景B中训练误差和人为误差只有0.5%的差距,而开发误差与训练误差有2%,这个时候我们可以认为模型的方差太大,可避免偏差很小,下一步我们可以从减小模型方差的方向努力,比如正则化,增大数据集等
因此,可避免偏差是我们用跟贝叶斯误差对比分析后得出的一个数值,如果它比开发误差与训练误差之间的差距大,我们可以认为模型的结构有待改善或者训练的时间不够长,是一种很有效的误差分析指标。
三、如何进行误差分析
进行误差分析时,吴老师建议我们采用一种看似很低级的做法:
取出100个开发集里被错误标签的样本,做一个表格,将这些错误样本进行分类统计,观察每种错误标签占的比例,再根据比例大小,分析模型的改进方向
例如课程里的猫识别器,我们取出一些错误标签的样本,统计错误标签的种类:dog、great cats、blurry、Instagram,并将每个种类的数目统计出来,计算比例

图 5 图5 图5
如图5所示,如果我们模型的错误率是10%,假如我们把优化方向放在解决“Dog”类型的错误标记,即使此类错误全部解决,那优化后的错误率是10%-10%*8%=9.2%,提升不到,
而做成表格后我们可以很明显看到,“Great Cats”和“blurry”类型的错误标记占大多数,我们应该着重解决这两类的问题,因为解决好这两类问题后,我们的模型肯定会大幅减少错误率
因此,吴老师说了,虽然上面这种方法虽然很笨,实际上它会帮我们节省很多时间,因为如果方向错了,在怎么优化都是这浪费时间
另外对于错误标记(incorrectly labeled,指样本本身标签错误,不是模型的输出错误)的样本,我们也可以根据上面的方法将该类型产生的错误比例计算出来,一边分析
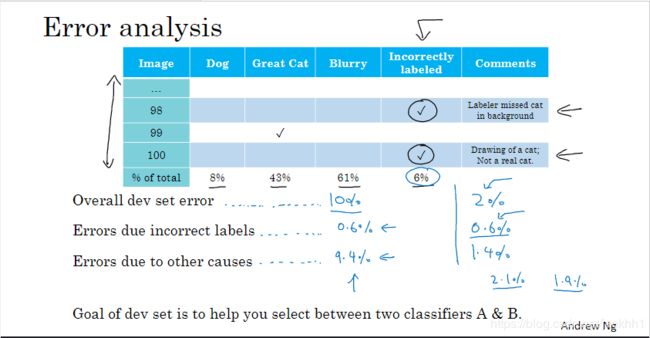
图 6 图6 图6
如图6所示,如果整个模型的误差是10%,手动统计的错误标签的比例为6%,那么整个模型的其它类型的误差就为9.4%,很明显,优化“错误标签”类误差对模型没有很大提升,而如果整个模型的误差是2%,手动统计的错误标签比例依然为0.6%的话,该类型的误差占到了整个模型误差的30%,那就很应该要注意优化此类误差了,因为它对模型的性能有明显的影响了。
最后,吴老师给出了3点纠正开发/测试集里错误样本的建议:
- 开发集合测试集需应用一样的过程,为了确保他们依旧属于同一分布。上面也提到过开发集和测试集必须要求来自同一分布,不然模型的开发过程就白费了
- 我们算法也要在正确的样本里进行运行,不光光是在错误的样本里运行。(吴老师说这一步讲道理是要做的,要不然优化后的算法存在一点不公平性,但由于错误的比例往往比正确的比例少,在正确的样本集里跑的时间要远大于错误样本的时间,所以这一步很少做)
- 训练集的分布和开发/测试集的分布可以有一点儿不同
四、定位数据不匹配
在上面的“可避免误差”概念中,吴老师说如果开发集和训练集之间的误差差距比训练集误差和人为误差之间的差距大,那模型可能是方差过大,但这是基于训练集和开发集来自同一分布的情况,如果训练集和开发集不是同一分布了,出现图7左上的情况时,我们该做出怎样的判断了?

图 7 图7 图7
办法总是有的,面对训练集和开发集/测试集不是同一分布的情况,我们可以事先从训练集中做一个“训练开发集”,它和训练集是同一分布,但不用于训练。
然后我们看图7中右上部分内容,假如1:
- 训练误差:1%
- 训练开发误差:9%
- 开发误差:10%
我们可以猜测模型可能是有很大的方差,因为虽然训练误差很小,但是来自同一分布的训练开发误差达到了9%。
假如2:
- 训练误差:1%
- 训练开发误差:1.5%
- 开发误差:10%
我们可以猜测模型可能存在数据不匹配的问题,因为训练误差和训练开发误差都很小,而开发误差很大。
我们再看看图7中右下部分,假如3:
- 人类误差:≈0%
- 训练误差:10%
- 训练开发误差:11%
- 开发误差:12%
我们可以猜测模型的可避免误差很大,因为训练误差和训练开发误差很接近,训练开发误差和开发误差也很接近。
假如4:
- 人类误差:≈0%
- 训练误差:10%
- 训练开发误差:11%
- 开发误差:20%
我们可以猜测模型既存在可避免偏差,也存在数据不匹配的问题,因为不仅训练误差和人为误差相差很大,开发误差和训练开发误差也很大!
接下来,总结下上面几种数据集偏差差距的含义,我们可以参考吴老师课件上的图,如图8所示

注意:图片8中右边的开发集/测试集误差比训练集误差小,这是有可能,因为我们再训练语音识别类模型时,往往真实场景的输入比训练集简单。
最后我们可以制作图9中表格来表示,并对比红色框框里的数据进行分析模型可能存在的问题。
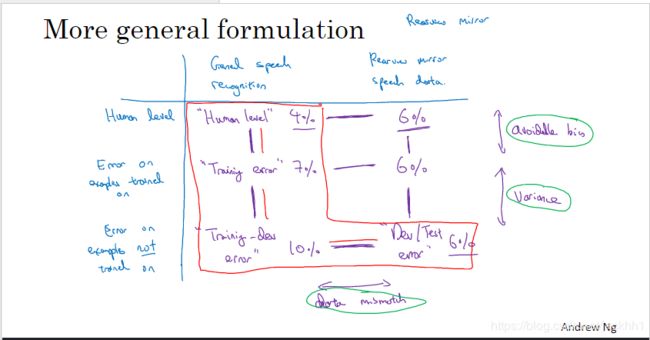
图 9 图9 图9
如果我们遇到了数据不匹配的问题,该用什么方法或系统解决方案了?答案是没有特别有效的方法…
不过吴老师给了两条指导性原则:
- 手动进行误差分析,尝试去理解训练集和开发/测试集之间的区别。一般为了防止模型过拟合,我们一般看训练集和开发集之间的区别。
- 尝试让训练集和开发集之间更相似,或者收集更多数据让开发集/测试集与训练集更加相似。比如:开发集中的语音识别有汽车噪音,我们也可以通过语音合成技术,将训练集的样本合成带有汽车噪音的样本。
五、迁移学习、多任务学习、端到端学习介绍
迁移学习的概念就如同它字面上的意思一样,我们把训练好的一个猫分类器,拿来进行狗分类,可不可以了?当然是可行的
例如,假设我们对信号灯的红、绿灯进行了大量数据的学习,现在有了新任务,即需要识别黄灯,此时我们就不需要从头搭建模型,我们可以继续使用红绿灯网络框架,只需修改神经网络最后一层,即输出层,然后用已经训练好的权重参数初始化这个模型,对黄灯数据进行训练学习。
为什么可以这么做呢?因为尽管最后的标签不一致,但是之前学习的红绿灯模型已经捕捉和学习了很多有用的特征和细节,这对于黄灯的学习十分有帮助,而且这么做也可以大大的加快模型的构建速度。
但迁移学习也是有些限制的:(将A模型运用到B模型)
- A和B需要有类似的输入数据集。比如都是图像识别或者语音识别
- A的数据集要远大于B的数据集
- A中学到的一些低级别特征要对B有所帮助
多任务学习是指模型具有多个输出,与softmax不同,softmax一次只能识别一种物体,而多任务学习一次可以识别多个物体,比如无人驾驶模型。
在行驶路上需要识别很多类型的物体,如行人、红绿灯、指路标志等等,所以此时可以使用多任务学习来实现。神经网络示意图如下:

图 10 图10 图10
如图10所示,最后的 y ^ \hat {y} y^一个有4元素的向量,假设分别是行人、汽车、停车标志、信号灯。如果识别出图片中有哪一个元素,对应位置则输出1。
多任务学习的注意事项如图11所示:

图 11 图11 图11
端到端深度学习是指模型直接将输入X映射到Y,不在中间进行多项分解动作或者流水线那样的动作。
例如,之前人们将音频转换为文本,是需要经过“audio-feature-phonemes-words-transcript"这些步骤才能完成。但有了端到端深度学习后,我们只需要在audio和transcript之间加一个神经网络就行了。
端到端深度学习的优缺点:
优点:
- 让数据说话。比如上面的例子将音频转换为音位再转化为单词文本的做法,其实音位都是语音学家发明出来的,可以认为是他们猜想的,人人的交流可以不用识别具体每个音位的发音,直接通过整个声音得到声音所表达的意思,这就是端到端学习的原理。
- 减少人为设计的组件
缺点: - 需要确保拥有足够的数据
- 它会排除可能有用的手工设计组件
如果想采用端到端的深度学习,我们需要考虑一个核心问题是:
我们是否有足够的数据去学习将X映射到y的函数复杂度?
比如我们找出一张图片的人脸来很容易,但要识别这个人多少岁,那就要难很多,或者我们要识别一张手的X光片的大小很容易,但是要通过这张图片识别出这个人多少岁也会困难很多。