梯度消失问题和梯度爆炸问题,总的来说可以称为梯度不稳定问题。
【要背住的知识】:用ReLU代替Sigmoid,用BN层,用残差结构解决梯度消失问题。梯度爆炸问题的话,可以用正则化来限制。sigmoid的导数是【0,0.25】.
出现原因
两者出现原因都是因为链式法则。当模型的层数过多的时候,计算梯度的时候就会出现非常多的乘积项。用下面这个例子来理解:

这是每层只有1个神经元的例子,每个神经元的激活函数都是sigmoid,然后我们想要更新b1这个参数。
按照大家都公认的符号来表示:
- \(w_1\*x_1 + b_1 = z_1\)这就是z的含义;
- \(\sigma(z_1)=a_1\),这是a的含义。
可以得到这个偏导数:
\(\frac{\partial C}{\partial b_1} = \frac{\partial z_1}{\partial b_1}\frac{\partial a_1}{\partial z_1} \frac{\partial z_2}{\partial a_2}\frac{\partial a_2}{\partial z_2} \frac{\partial z_2}{\partial a_3}\frac{\partial a_3}{\partial z_3} \frac{\partial z_3}{\partial a_4}\frac{\partial a_4}{\partial z_4} \frac{\partial C}{\partial a_4}\)
然后化简:
\(\frac{\partial C}{\partial b_1}=\sigma'(z_1)w_2\sigma'(z_2)w_3\sigma'(z_3)w_4\sigma'(z_4)\frac{\partial C}{\partial a_4}\)
关键在于这个\(\sigma'(z_1)\),sigmoid函数的导数,是在0~0.25这个区间的,这意味着,当网络层数越深,那么对于前面几层的梯度,就会非常的小。下图是sigmoid函数的导数的函数图:

因此经常会有这样的现象:
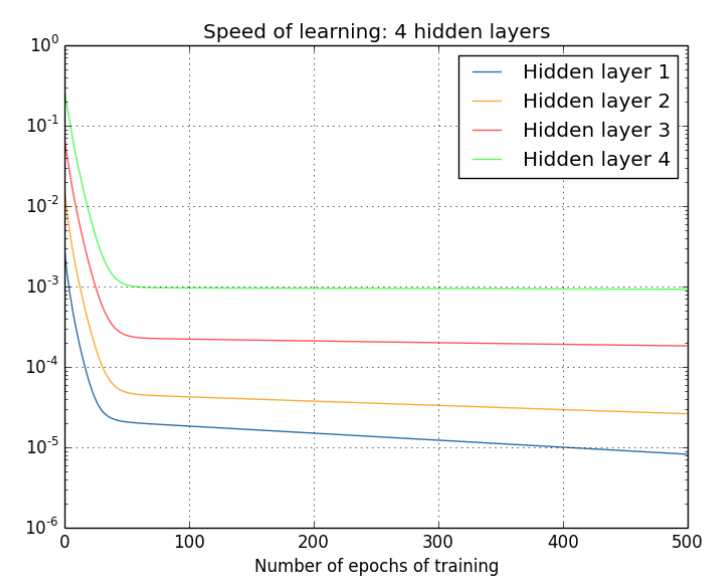
图中,分别表示4层隐含层的梯度变化幅度。可以看到,最浅的那个隐含层,梯度更新的速度,是非常小的。【图中纵轴是指数变化的】。
那么梯度爆炸也很好理解,就是\(w_j\sigma'(z_j)>1\),这样就爆炸了。
【注意:如果激活函数是sigmoid,那么其导数最大也就0.25,而\(w_j\)一般不会大于4的,所以sigmoid函数而言,一般都是梯度消失问题】
【总结】:
- 梯度消失和梯度爆炸是指前面几层的梯度,因为链式法则不断乘小于(大于)1的数,导致梯度非常小(大)的现象;
- sigmoid导数最大0.25,一般都是梯度消失问题。
解决方案
更换激活函数
最常见的方案就是更改激活函数,现在神经网络中,除了最后二分类问题的最后一层会用sigmoid之外,每一层的激活函数一般都是用ReLU。
【ReLU】:如果激活函数的导数是1,那么就没有梯度爆炸问题了。

【好处】:可以发现,relu函数的导数在正数部分,是等于1的,因此就可以避免梯度消失的问题。
【不好】:但是负数部分的导数等于0,这样意味着,只要在链式法则中某一个\(z_j\)小于0,那么这个神经元的梯度就是0,不会更新。
【leakyReLU】:在ReLU的负数部分,增加了一定的斜率:
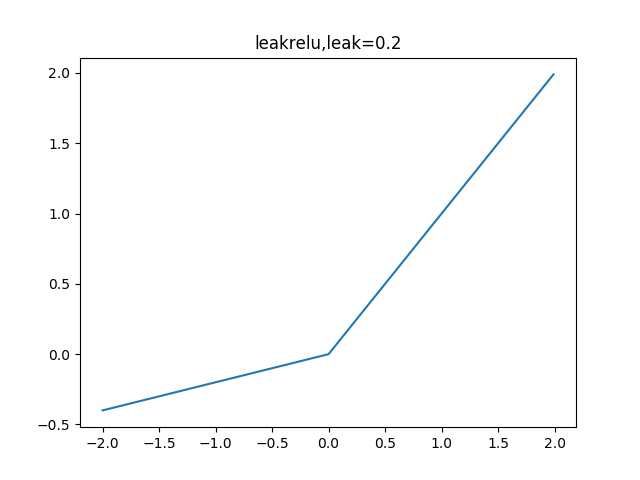
解决了ReLU中会有死神经元的问题。
【elu】:跟LeakyReLU一样是为了解决死神经元问题,但是增加的斜率不是固定的:

但是相比leakrelu,计算量更大。
batchnorm层
这个是非常给力的成功,在图像处理中必用的层了。BN层提出来的本质就是为了解决反向传播中的梯度问题。
在神经网络中,有这样的一个问题:Internal Covariate Shift。
假设第一层的输入数据经过第一层的处理之后,得到第二层的输入数据。这时候,第二层的输入数据相对第一层的数据分布,就会发生改变,所以这一个batch,第二层的参数更新是为了拟合第二层的输入数据的那个分布。然而到了下一个batch,因为第一层的参数也改变了,所以第二层的输入数据的分布相比上一个batch,又不太一样了。然后第二层的参数更新方向也会发生改变。层数越多,这样的问题就越明显。
但是为了保证每一层的分布不变的话,那么如果把每一层输出的数据都归一化0均值,1方差不就好了?但是这样就会完全学习不到输入数据的特征了。不管什么数据都是服从标准正太分布,想想也会觉得有点奇怪。所以BN就是增加了两个自适应参数,可以通过训练学习的那种参数。这样吧每一层的数据都归一化到\(\beta\)均值,\(\gamma\)标准差的正态分布上。
【将输入分布变成正态分布,是一种去除数据绝对差异,扩大相对差异的一种行为,所以BN层用在分类上效果的好的。对于Image-to-Image这种任务,数据的绝对差异也是非常重要的,所以BN层可能起不到相应的效果。】
残差结构

残差结构,简单的理解,就是让深层网络通过走捷径,让网络不那么深层。这样梯度消失的问题就缓解了。
正则化
之前提到的梯度爆炸问题,一般都是因为\(w_j\)过大造成的,那么用L2正则化就可以解决问题。
喜欢的话请关注我们的微信公众号~【你好世界炼丹师】。
- 公众号主要讲统计学,数据科学,机器学习,深度学习,以及一些参加Kaggle竞赛的经验。
- 公众号内容建议作为课后的一些相关知识的补充,饭后甜点。
- 此外,为了不过多打扰,公众号每周推送一次,每次4~6篇精选文章。
微信搜索公众号:你好世界炼丹师。期待您的关注。
