《深度学习工程师-吴恩达》03卷积神经网络—深度卷积网络:实例探究 学习总结
作者:jliang
https://blog.csdn.net/jliang3
《深度学习工程师-吴恩达》03卷积神经网络—深度卷积网络:实例探究 学习总结
1.重点归纳
1)计算机视觉领域经典的神经网络
(1)LeNet-5
(2)AlexNet
(3)VGG
2)LeNet-5

这个网络很小只有60k个参数,而现代网络含有一千万到一亿个参数也不在少数
3)AlexNet

(1)与LeNet-5有很多相似之处,不过AlexNet要大很多,有约6000万个参数
(2)AlexNet比LeNet-5优秀的另一个原因是它使用了ReLu函数
4)VGG-16

(1)VGG-16是一个很大的网络,但是结构并不复杂,这一点非常吸引人。
(2)文献中揭示了随着网络的加深,图像的高度和宽度都在一定的规律不断缩小,而信道数量在不断增加。这里刚好是在每组卷积操作后信道增加一倍,也就是说图像缩小的比例和信道增加的比例是有规律的。
(3)缺点是需要训练的特征数量非常巨大
5)残差网络

(1)在正常的网络中,把前面经过激活函数后的输出数据a[l]拷贝到神经网络下下层(两层)激活函数之前,这条路径称为“short cut(捷径)”/“skip connection(跳远连接)”
(2)原有的a[l+2]=g(z[l+2])变成a[l+2]=g(z[l+2]+a[l]),也就是加上了这个a[l]产生了一个残差块
(3)这条捷径是在进行激活函数之前加上的,可以跳过一层或多层网络,从而将信息传递到神经网络的更深层
(4)使用残差块能够训练更深的神经网络,所以构建一个ResNet网络就是通过将很多这样的残差块堆积在一起形成一个深度神经网络
(5)为什么有用:
- 这些残差块学习恒等函数非常容易,你能确定表现能力不会受影响,很多时候甚至可以提高表现,或者说至少不会降低网络表现。因此创建类似残差网络可以提升网络性能。
- 如果这些被添加隐层单元学到了一些有用信息,那么它可能比学习恒等函数表现表现得更好。而这些深度普通网络,随着网络的加深,就算选择用来学习恒等函数的参数都很困难,所以多层网络后表现不但没有更好,反而更糟。
6)1*1卷积

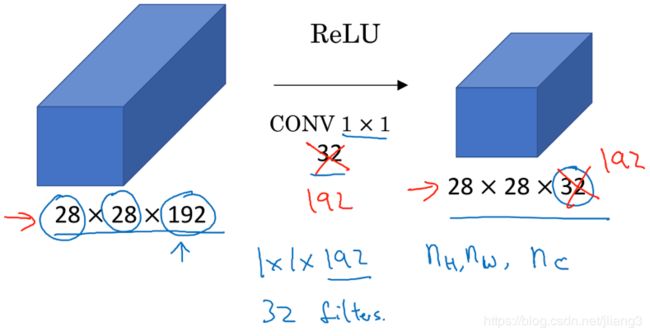
(1)如果输入图片大于1个信道,效果相当于把同一位置的多个信道都乘以一个系数,然后再累加在一起,然后应用ReLu非线性函数。相当于对同一位置的所有值进行了一次全连接。
(2)如果我们想压缩信道并减少计算,则可以使用1*1卷积进行压缩,也可以通过增加1*1卷积的滤波器数量来增加信道数量。
(3)如果使用1*1卷积但是却不改变输入信道数量,相当于1*1卷积只是添加了非线性函数让网络学习更复杂的函数。
7)Inception网络

(1)Inception层的作用就是代替人工来确定卷积层中的过滤类型,或者确定是否需要创建卷积层或池化层。
(2)通过1*1卷积来构建瓶颈层,从而大大降低计算成本。

(3)Inception模块

(5)Inception网络就是将多个Inception模块组合在一起
8)计算机视觉常见的工作流
- 先选择一个你喜欢的架构
- 接着寻找一个开源实现,从github下载下来
- 以此为基础进行迁移学习
9)迁移学习

(1)如果你有很少的数据,则冻结别人的整个网络权重,删除别人的softmax层,构建自己的softmax层,只需在自己的数据上训练softmax层权重。
(2)如果你有更多的训练数据
- 部分层冻结,部分层使用别人的权重作为初始值进行训练:你应该冻结更少的层(靠前面的层),然后训练别人模型后面的层。如果输出层的类别数量与别人不同,也需要构建你自己的softmax层。
- 直接去掉别人后面几层,然后构建自己的隐藏层以及softmax层来替代它。
(3)如果你有越多的训练样本,你需要冻结的层数越少,你能够训练的层数就越多。如果你有非常多的训练样本,你可以把别人的真个整个权重作为初始值,然后训练整个网络。
10)数据扩充
(1)常见的方式:
- 垂直镜像对称
- 随机裁剪:随机选取一块空间进行裁剪,可以产生多种裁剪输出
- 旋转
- 剪切图像
- 局部弯曲
(2)色彩转换增强方式
- RGB根据某种概率分布来决定改变的大小
- PCA颜色增强(AlexNet论文)
(3)实施数据增强:使用CPU多线程读取图片并进行图片扭曲,然后再把批量图片传递给另外一个CPU/GPU进程进行训练

2.为什么要进行实例探究?
1)找设计灵感
2)计算机视觉任务中表现良好的神经网络框架往往也适用于其他任务。说如果有人已经训练或计算出擅长识别猫狗人的神经网络框架,你完全可以借鉴别人的神经网络框架来解决你的问题(例如你的任务是构建自动驾驶汽车)。
3)经典的网络,这些都是非常有效的神经网络范例,当中的一些思路为现代计算机视觉技术发展奠定了基础。
(1)LeNet-5
(2)AlexNet
(3)VGG
4)残差网络ResNet,训练了一个深达152层的神经网络,并且在如何有效训练方面总结出了一些有趣的想法和敲门。
3.经典网络
1)LeNet-5

(1)在现代版本中使用softmax作为分类输出,而当时LeNet-5网络在输出层使用了另外一种现在已经很少用到的分类器。
(2)相比起现代网络,这个网络很小只有60k个参数,而现代网络含有一千万到一亿个参数也不在少数
(3)还有一种模式至今仍然经常使用,就是一个或多个卷积层后跟着一个池化层,然后又是若干个卷积层,然后是全连接层,然后是输出。这种排列方式很常用。
(4)论文中使用sigmoid和tanh函数而不是Relu函数
(5)经典的LeNet-5网络在池化后进行了非线性函数(如sigmoid)处理
2)AlexNet

(1)与LeNet-5有很多相似之处,不过AlexNet要大很多,
(2)有约6000万个参数
(3)AlexNet比LeNet-5优秀的另一个原因是它使用了ReLu函数
3)VGG-16
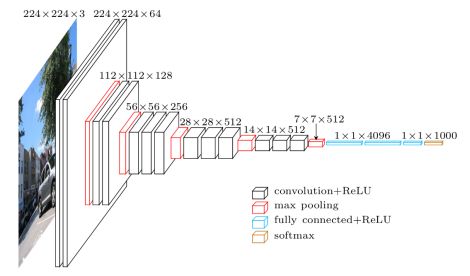
(1)这是一种只需要专注于构建卷积层的简单网络,它的最大优点就是它的确简化了神经网络结构。它是16层的网络(除池化层外共16层),共1.38亿个参数


- 输入224x224x3的图片,经过64个卷积核的两次卷积后,采用一次pooling。经过第一次卷积后,c1有(3x3x3)个可训练参数
- 之后又经过两次128的卷积核卷积之后,采用一次pooling
- 再经过三次256的卷积核的卷积之后,采用pooling
- 重复两次三个512的卷积核卷积之后再pooling
- 三次Fc
- 最后是softmax激活函数,输出从1000个对象中识别的结果
(2)VGG-16是一个很大的网络,但是结构并不复杂,这一点非常吸引人。
- 这种网络结构很规则,都是几个卷积层后,跟着一个可以压缩图像大小的池化层(把图像缩写一半)
- 卷积层的过滤器数量变化存在一定的规律,每一组卷积层让过滤器增加一倍,然后到512个时可能作者认为已经足够大了,然后后面的层数就不再增加
(3)缺点是需要训练的特征数量非常巨大
(4)还有VGG-19的网络结构,但是VGG-16和VGG-19性能不分上下,所以一般使用VGG-16。
(5)文献中揭示了随着网络的加深,图像的高度和宽度都在一定的规律不断缩小,而信道数量在不断增加。这里刚好是在每组卷积操作后信道增加一倍,也就是说图像缩小的比例和信道增加的比例是有规律的。
(6)keras实现VGG-16
from keras import Sequential
from keras.layers import Dense, Activation, Conv2D, MaxPooling2D, Flatten, Dropout
from keras.layers import Input
from keras.optimizers import SGD
model = Sequential()
# BLOCK 1
model.add(Conv2D(filters = 64, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block1_conv1', input_shape = (224, 224, 3)))
model.add(Conv2D(filters = 64, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block1_conv2'))
model.add(MaxPooling2D(pool_size = (2, 2), strides = (2, 2), name = 'block1_pool'))
# BLOCK2
model.add(Conv2D(filters = 128, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block2_conv1'))
model.add(Conv2D(filters = 128, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block2_conv2'))
model.add(MaxPooling2D(pool_size = (2, 2), strides = (2, 2), name = 'block2_pool'))
# BLOCK3
model.add(Conv2D(filters = 256, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block3_conv1'))
model.add(Conv2D(filters = 256, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block3_conv2'))
model.add(Conv2D(filters = 256, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block3_conv3'))
model.add(MaxPooling2D(pool_size = (2, 2), strides = (2, 2), name = 'block3_pool'))
# BLOCK4
model.add(Conv2D(filters = 512, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block4_conv1'))
model.add(Conv2D(filters = 512, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block4_conv2'))
model.add(Conv2D(filters = 512, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block4_conv3'))
model.add(MaxPooling2D(pool_size = (2, 2), strides = (2, 2), name = 'block4_pool'))
# BLOCK5
model.add(Conv2D(filters = 512, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block5_conv1'))
model.add(Conv2D(filters = 512, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block5_conv2'))
model.add(Conv2D(filters = 512, kernel_size = (3, 3), activation = 'relu', padding = 'same', name = 'block5_conv3'))
model.add(MaxPooling2D(pool_size = (2, 2), strides = (2, 2), name = 'block5_pool'))
# FC
model.add(Flatten())
model.add(Dense(4096, activation = 'relu', name = 'fc1'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation = 'relu', name = 'fc2'))
model.add(Dropout(0.5))
4.残差网络
1)很深很深的网络很难训练,因为存在梯度消失和梯度爆炸问题,我们可以利用跳远连接构建能够训练深度网络的ResNets,甚至可以超过100层。
2)残差网络

(1)在正常的网络中,把前面经过激活函数后的输出数据a[l]拷贝到神经网络下下层(两层)激活函数之前,这条路径称为“short cut(捷径)”/“skip connection(跳远连接)”
(2)原有的a[l+2]=g(z[l+2])变成a[l+2]=g(z[l+2]+a[l]),也就是加上了这个a[l]产生了一个残差块
(3)这条捷径是在进行激活函数之前加上的,可以跳过一层或多层网络,从而将信息传递到神经网络的更深层
(4)使用残差块能够训练更深的神经网络,所以构建一个ResNet网络就是通过将很多这样的残差块堆积在一起形成一个深度神经网络
3)普通网络与残差网络
(1)普通网络

(2)给普通网络每两层/多层增加一个捷径构成一个残差块,从而形成了残差网络

(3)对于普通网络,随着网络深度的加深,训练错误会先减少,然后增多。
- 而理论上网络深度越深训练效果越好,而实际上如果没有残差网络,深度越深意味着越难用优化算法来训练,所以网络越深,训练错误会越多。
- 有了ResNets后,即使网络再深,训练效果表现依然很好。
- 残差网络有助于解决梯度消失和梯度爆炸问题,

5.残差网络为什么有用?
1)残差网络起作用的主要原因:这些残差块学习恒等函数非常容易,你能确定表现能力不会受影响,很多时候甚至可以提高表现,或者说至少不会降低网络表现。因此创建类似残差网络可以提升网络性能。
(1)一个普通网络越深,它在训练集上表现会有所减弱;在训练ResNet网络时,并不会减弱,甚至还会加强。

- 跳远连接输入时a[l+2]=g(z[l+2]+a[l]),即a[l+2]=g(w[l+2]a[l+1]+b[l+2]+a[l])。
- 如果使用L2正则化或权重衰减,w[l+2]的值会被压缩;如果对b应用权重衰减,也达到同样的效果。这里w是关键项,假设使用ReLu激活函数(a>=0),如果w[l+2]=0,a[l+2]=g(a[l])。
- 跳远连接使我们很容易得出a[l+2]= a[l],即使给神经网络添加这两层网络,它的表现也并不逊色于更简单(浅)的网络,因为学习恒等函数对它来说很简单。
- 经管它多了两层,也只是把a[l]的值赋给a[l+2](如果没有学习到有用信息时)。所以给大型网络增加两层网络时,不论添加到中间还是末端位置,也并不影响网络的表现。
(2)如果这些被添加隐层单元学到了一些有用信息,那么它可能比学习恒等函数表现表现得更好。而这些深度普通网络,随着网络的加深,就算选择用来学习恒等函数的参数都很困难,所以多层网络后表现不但没有更好,反而更糟。
2)网络维度问题
(1)假设a[l+2]和a[l]具有相同维度,ResNets使用了许多相同卷积,所以这个a[l]的维度等于这个输出层的维度。因为同一个卷积保留了维度,所以很容易得出这个捷径连接。
(2)假设输入和输出不同维度,就会在a[l]上乘以一个矩阵Ws来保证输入维度与输出维度一致,这个Ws是通过学习得到的矩阵。
a[l+2]=g(z[l+2]+ Wsa[l])
3)把卷积网络转变成深度卷积网络

(1)只需要添加跳远连接。
(2)这个网络它们大多都是相同的,这些都是卷积层,而不是全连接层。因为它们是相等的卷积,维度是一样。
(3)ResNet也类似其他网络,也会有很多卷积层,其中偶尔会有池化层或类似池化层的层,这时候需要Ws来调整网络的维度。
(4)普通网络和ResNet网络常用的网络结构是Conv-Conv-Conv-Pool- Conv-Conv-Conv-Pool- Conv-Conv-Conv-Pool依次重复,
6.网络中的网络以及1*1卷积
1)1*1卷积/Network in Network

(1)对于输入图片只有1个信道时,相当于把所有输入都乘以了一个系数就直接输出,卷积效果不佳。
(2)如果输入图片大于1个信道,效果相当于把同一位置的多个信道都乘以一个系数,然后再累加在一起,然后应用ReLu非线性函数。相当于对同一位置的所有值进行了一次全连接。
(3)一般情况下有多个滤波器,以便在输入层上实施一个非凡(non trivial)计算
2)改变(压缩/扩展)信道数量
(1)我们可以使用池化层来压缩高度和宽度,如果我们想压缩信道并减少计算,则可以使用1*1卷积进行压缩。
(2)如果使用1*1卷积但是却不改变输入信道数量,相当于1*1卷积只是添加了非线性函数让网络学习更复杂的函数。
(3)也可以通过增加1*1卷积的滤波器数量来增加信道数量。
7.谷歌Inception网络简介
1)在构建网络时,我们需要决定滤波器的大小(1*1、3*3、5*5),或者要不要添加池化层,而Inception网络的作用是代替你来做决定。我们可以应用各种类型的过滤器,只需要把输出连接起来训练。虽然网络架构变得更加复杂,但网络表现变得非常好。

(1)Inception层的作用就是代替人工来确定卷积层中的过滤类型,或者确定是否需要创建卷积层或池化层。
(2)把多个(1*1、3*3、5*5)不同大小的过滤器(使用same padding)以及池化层(特殊池化,使用same padding),并把所有输出值堆积在一起。这样便得到了Inception模块,如上图。
(3)Inception网络的基本思想是不需要人为决定使用哪个过滤器,给网络添加这些参数的所有可能值,然后把这些输出连接起来,让网络自己学习它需要什么样的参数、采用哪些过滤器组合。
(4)这样的inception模块计算代价很大。
2)通过1*1卷积来构建瓶颈层,从而大大降低计算成本
(1)以5*5过滤器为例子,它需要计算28*28*32个输出,对于每个输出需要计算5*5*192次乘法运算,共需要计算28*28*32*5*5*192=1.2亿次乘法运算。
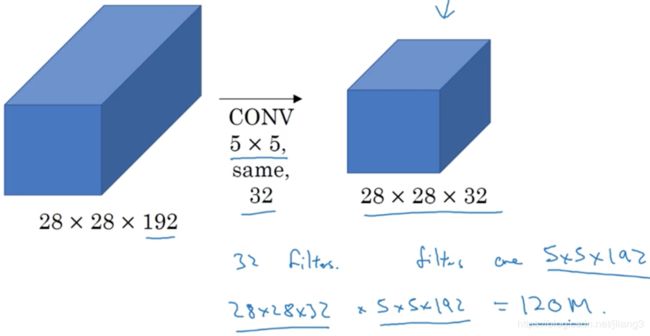
(2)构建瓶颈层来降低计算成本:使用1*1卷积把输入值从192个信道减少到16个信道,然后再计算5*5卷积。

- 输入和输出维度和上面一样。
- 我们把左边的很大的输入层压缩成较少的中间层,这个中间层也成瓶颈层,是网络中最小的部分(像瓶颈一样)。
- 我们先压缩网络,然后再扩大它。
- 第一层计算成本为28*28*16*192=240万,第二层计算成本为28*28*32*5*5*16=1000万,总共1240万。是优化前的1/10计算。
- (3)事实证明,只要合理构建瓶颈层,既可以显著缩小表示层规模,又不会降低网络性能,从而大大降低了计算成本。
8.Inception网络
1)Inception模块

(1)在添加3*3和5*5卷积层之前增加一个1*1的卷积,用于降低计算量
(2)添加1*1卷积时,可以直接添加
(3)添加池化层时,由于信道不变,所以在其后再添加1*1的卷积来改变信道数量
(4)卷积核池化层都使用same padding,步长=1,输入和输出的大小一样
(5)最后再把所有类型的卷积concat在一起
2)Inception网络就是将多个Inception模块组合在一起
(1)网络中有多个Inception模块
(2)每隔几层就会使用池化层来压缩大小
(3)在网络的最后几层是全连接层然后再加一个softmax层作输出。Inception网络会从隐藏层伸出一个分支,这个分支连接全连接层和softmax层作输出,相当于网络中同时有多个地方输出。
- 它确保了即使是隐藏单元和中间层,也参与特征计算,它们也能预测
- 它在Inception网络中起到一种调整的效果,并且能防止网络发生过拟合
3)除了这经典版本的Inception网络,还衍生了Inception V2、Inception V3、Inception V4等版本,还有一个版本引入了跳跃连接的方法,有时也会有特别好的效果。这些新的版本都建立在同一种基础的思想上。
9.使用开源的实现方案
1)事实证明很多神经网络复杂细致,因而难以复制。
(1)因为一些参数调整的细节问题、学习率衰减等影响模型性能
(2)即使是顶尖大学的AI学生或深度学习的博士生也很难通过阅读别人研究论文来复制他人的成果。
2)如果你在做一个计算机视觉应用:
(1)一个常见的工作流是:
- 先选择一个你喜欢的架构
- 接着寻找一个开源实现,从github下载下来
- 以此为基础进行迁移学习
(2)这些网络通畅需要很长的时间来训练,而且需要使用多个GPU,通过庞大的数据集预先训练这个网络。你就可以使用这些网络进行迁移学习。
10.迁移学习
1)如果你下载别人已经训练好的权重结构,通常能够进展得相当快。使用它作为预训练,然后转换到你自己的任务上。
2)例子:识别猫Tigger、猫Misty和其他的三分类问题
(1)下载神经网络的实现,不仅下载代码,把训练好的权重也下载下来。有很多训练好的网络可以下载,如ImageNet数据集有1000个不同的类别。
(2)去掉网络中输出1000个类别的softmax层,然后创建自己的三分类softmax层。
(3)建议冻结别人网络所有层的参数,只训练和softmax层有关的参数。
3)通过使用其他人预训练的权重,即使你只有一个很少的数据集,你很可能也能得到很好的性能。
4)是否支持这种操作取决于使用的框架,幸好大多数神经网络学习框架都支持这种操作。它也许会有trainableParameter=0这样的参数,有时候可能是freeze=1,为了不训练这些前面的层的权重,可以设置这个参数。
5)由于这些前面的层都不可以改变,相当于一个固定的函数,类似图像输入到输入层后直接到最后一层建立一个映射。一个可以加速训练的技巧:
(1)提前把每个输入至最后一层之间的映射(计算特征或激活值)计算好,然后把这个映射结果保存到磁盘。
(2)然后再使用上面保存的结果作为输入,只需训练一个很浅的softmax模型。
6)不同训练样本数量使用不同的方式进行迁移学习

(1)如果你有更多的训练数据
- 部分层冻结,部分层使用别人的权重作为初始值进行训练:你应该冻结更少的层(靠前面的层),然后训练别人模型后面的层。如果输出层的类别数量与别人不同,也需要构建你自己的softmax层。
- 直接去掉别人后面几层,然后构建自己的隐藏层以及softmax层来替代它。
(2)如果你有越多的训练样本,你需要冻结的层数越少,你能够训练的层数就越多。如果你有非常多的训练样本,你可以把别人的真个整个权重作为初始值,然后训练整个网络。
7)计算机视觉识别领域是一个经常使用迁移学习的领域,除非你有一个极其大的数据集以及非常大的计算量预算,可以从头开始计算。
11.数据扩充
1)计算机视觉的主要问题就是没有办法得到充足的数据,数据远远不够。更多的数据对计算机视觉任务都是由帮助的,数据增强对计算机视觉训练会有帮助。无论是使用迁移学习使用别人的预训练模型开始,或者是从头到尾自己训练模型。
2)常见的数据增加方式

(1)垂直镜像对称
(2)随机裁剪:随机选取一块空间进行裁剪,可以产生多种裁剪输出
不是一种完美的方法,如果你随机裁剪的那部分没有包含被识别主题的主要特征,模型就很难学习到。在实践中,这个方法还是很实用的。
(3)旋转
(4)剪切图像
(5)局部弯曲
可以同时使用上面的多种方式进行数据增强,但是实践中因为太复杂了,所以使用得很少。
3)色彩转换增强方式

(1)RGB根据某种概率分布来决定改变的大小。例如把图片改偏紫色/黄色/蓝色一点,这么做的原因是也许阳光下或者灯光下的颜色变得更黄一点,这样可以使模型更鲁棒。
(2)PCA颜色增强(AlexNet论文)。比如说图片呈现紫色,即主要含有红色和蓝色,绿色比较少,PCA颜色增强算法就会对红色和蓝色增减很多,绿色相对少一点,总体的颜色保持一致。
4)训练过程实施数据增强(数据量比较大时)

(1)在一个/多个线程上读取并扭曲图片:使用CPU线程不停的从硬盘中读取图片,并使用CPU线程实现图片扭曲(随机裁剪、颜色变化、镜像等),不同的图片可能实施不同的扭曲。
(2)并把这些数据构成批数据/mini批数据,再把这些图片给其他线程/进程,然后在CPU/GPU上开始训练。
5)数据增强过程也有一些超参数,比如说颜色变化多少、随机裁剪使用的参数等。与训练模型类似,一开始时可以下载别人开源的代码来了解他们如何实现数据增强。
12.计算机视觉现状
1)深度学习已经成功应用于在计算机视觉、自然语言处理、语音识别、在线广告、物流等问题上。
2)如果你有很多数据,你可以选择更简单的算法以及更少的手工工程;当你没有那么多数据时,需要更多的手工工程。
3)机器学习应用时两种知识来源:
(1)被标识的数据,监督学习中的(x,y)
(2)手工工程,在缺乏数据的时候,获得良好表现的方式使花更多的时间进行架构设计
4)表现良好的一些小技巧(不建议在构建生产系统时使用这些方法)
(1)集成:独立训练几个神经网络,并平均输出它们的输出。在比赛中可能会有1%、2%的提升,但几乎从不用于实际生产中,因为需要打很多的计算资源和时间。
(2)对基准测试进行Multi-crop:一种将数据扩展应用到测试图像的形式。使用数据扩展的方式产生多个图像,并分别对多个图像分别进行测试,并使用它们的平均值作为输出。常用10-crop。