ALBERT真的瘦身成功了吗?
前言
最近在项目中使用BERT更新了服务久矣的TextCNN,但更新之路较为崎岖。线下验证BERT-Base版本较TextCNN提高较为明显,但是推到线上,Inference时间爆炸了;无奈,只好减少Transformer层数,由12层减少到4层,由于此项目场景下的Input较短,所以使用4层Transformer并没有太多效果层的损失,性能上Inference时间减少了2.3倍,后面又将服务由CPU集群迁移到GPU集群,Inference时间又减少了7倍。
整个上线过程较为麻烦,要不断修改Transformer层数来调节Inference时间和Acc,Recall;层数越少,Inference时间越短,但是Acc和Recall就越差,反之亦然。
项目上线之后,有一天无意间看到ALBERT(A Lite BERT),一种轻量级BERT,并且是由Google自己推出的,各种公众号和软文都在推“瘦身成功”,效果应该不错吧。由于之前上线BERT时一直被Inference时间限制,于是本着“效果和BERT一致的情况下,ALBERT应该Inference时间更短”的出发点,开启了以下炼丹之路...
先说一下结论,所谓的“瘦身成功”并不是我所期待的那种成功。ALBERT只减参数不减计算量。
瘦身三板斧及Tricks
作者对BERT进行了三处大的改进,其中前两项致力于减少模型的参数,即瘦身,但是我们都知道,一般情况下,参数量大的模型会比参数量小的模型效果好,所以瘦身肯定会损失性能,所以就出现了第三斧及后面的一些Tricks。
总结来看, Factorized embedding parameterization 和 Cross-layer parameter sharing 是为了减少参数达到瘦身目的,而 SOP(sentence-order prediction loss) 、n-gram masking 、input sequence limit 、remove dropout等都是为了补回来瘦身导致的性能损失。
Factorized embedding parameterization
对于BERT,WordPiece embedding size E(词向量维度)和hidden layer size H(隐层维度)是相等的,BERT-base H=E=768,BERT-large H=E=1024。而作者认为E和H不必须相等,E可以小于H,想想一个字或者词用768维甚至1024维度的向量去表示,确实有点过长了,作者又给出,词向量学习的是“上下文无关”的表达,而隐层向量学习的是“上下文相关”的表达,原文表达如下:
WordPiece embeddings are meant to learn context-independent representations, whereas hidden-layer embeddings are meant to learn context-dependent representations .
作者提出分解embedding参数,即把E单独提出来,并减小维度插入V和H之间,V指的是vocabulary的字数,论文中V=3w。那么对于model embedding的复杂度就变成了下式:
![]()
那我们来算一笔账,对于BERT-large,V=3w,把位置编码postion embedding也算进来,H=1024,embedding参数总量为 (3w+512)*1024 = 31M;对于ALBERT-large,假设E=128,embedding参数总量为(3w+512)*128+128*1024=4M,减少了31M-4M=27M,而对比下图ALBERT-large比BERT-large总的参数足足减少了334M-18M=316M,所以说 Factorized embedding 并不是瘦身的关键点,而接下来的 Parameter sharing 才是。

我们再来看看,Factorized embedding减少了模型参数,会不会带来性能的损失?答案是会。如下图可以看到随着E从768减小到64,Avg也是逐渐减小的,最多已经相差1个百分点了,如果是后续的fine-tuning task中,这个相差会更大。损失的这些性能怎么办呢?后面作者会找地方补回来。

Cross-layer parameter sharing
ALBERT瘦身的关键一板斧,就是Cross-layer parameter sharing。作者提出参数共享有三种方式:只共享FFN、只共享Attention patameters和全部共享。

如上图所示,首先来算一笔账,看下参数是怎么减少的。
我们可以把transformer分成三部分:attention、normalization layer、FFN,其中normalization layer参数量很少,忽略不计,重点就看attention和FFN。
我们就对比ALBERT-base,E=768,layers(transformer层数)=12,A(multi head头数)=12。
FFN计算公式为:![]() ,这是一个input和output维度一样的MLP变形网络,hidden size的变化为768->3072->768(或者512->2048->512),此处的参数量为W1和W2,单层layer FFN-parameters=2*768*3072=4.7M,那么shared-FFN之后,12层layer的FFN-parameters就只有4.7M,因为每一层的都一样,对比not-shared,12层layer FFN-parameters=12*2*768*3072=56.6M,参数减少56.6M-4.7M=51M,刚好和上表中108M-57M=51M相等。
,这是一个input和output维度一样的MLP变形网络,hidden size的变化为768->3072->768(或者512->2048->512),此处的参数量为W1和W2,单层layer FFN-parameters=2*768*3072=4.7M,那么shared-FFN之后,12层layer的FFN-parameters就只有4.7M,因为每一层的都一样,对比not-shared,12层layer FFN-parameters=12*2*768*3072=56.6M,参数减少56.6M-4.7M=51M,刚好和上表中108M-57M=51M相等。
atteention的计算主要分成4个参数,Wq、Wk、Wv、Wo,其中12个头的Wq、Wk、Wv参数总量为12*3*768*64=1.7M,Wo参数量为768*768=0.6M,所以单层layer attention-parameters=1.7+0.6=2.3M,那么shared-attention之后,12层layer的attention-parameters就只有2.3M,因为每一层都一样,对比not-shared,12层layer attention-parameters=12*2.3M=27.6M,参数减少27.6M-2.3M=25M,刚好和上表中108M-83M=25M相等。
同理,如果attention和FFN all shared之后,参数减少也可由上面两种情况相加得到。
我们再看看性能变化。可以看到只共享attention参数,会在瘦身的同时,保证性能不变;但是作者不甘于此,采用了暴力“all shared”的方式,毫不顾忌“all shared”之后性能会有近2个点的损失,就真的如此不顾及嘛?并不是,后面作者又找了其他方式,把性能补回来。
至此,ALBERT瘦身的操作都结束了,由上可以看到,embedding分解和parameter sharing极大减小了模型的参数,尤其是后者,但是都带来了性能的损失,就最坏的情况来讲,前者会有1个点的损失,后者会有2个点的损失,加起来近3个点了,这还怎么超越BERT?怎么屠榜?接下来就是作者为了提升性能做的一堆操作。
SOP(Sentence-order prediction loss)
BERT模型中NSP(next-sentence prediction loss)过于简单,它把“topic prediction”和“coherence prediction”融合到了一起,原文描述如下
NSP conflates topic prediction and coherence prediction in a 2 single task .
其实在ALBERT之前,已经有人提出NSP会破坏BERT的效果,所以在后续改进中,有人选择移除这个损失。
SOP是对NSP的改良版,正样本构造和NSP相同,负样本由“从不同documents选”变成“同一篇文章中两个逆序的句子”,这样模型会更加forces学习语料的连贯性。如下图所示,由SOP换成NSP,性能大概有1个点的提升,和Factorized embedding损失的性能可以相抵。

input sequence limit
原版的BERT为了加速训练,做了性能的取舍,前90%的step使用128 sequence length训练,后10%step使用512 sequence length训练,原文描述如下
To speed up pretraing in our experiments, we pre-train the model with sequence length of 128 for 90% of the steps.
ALBERT则几乎全程使用raw sequence length 训练,随机10%的概率选择shorted than 512进行训练,原文描述如下
We always limit the maximum input length to 512, and randomly generate input sequences shorter than 512 with a probability of 10% .
也就是在90%的情况下,ALBERT的输入都是raw sequence length,最长限制512,而BERT则是90%的情况下都只是128,所以输入长了近一倍,我们都知道输入越长,语言模型训练的越好,所以ALBER性能会有提高。
n-gram masking
BERT 的mask language model是直接对字进行masking,ALBERT使用n-gram masking,这其实和后面有人改进word masking一样,对中文进行分词,对词的masking比对字的masking性能会有一定的提升,所以ALBERT使用n-gram masking,其中n取值为1-3。
remove dropout
其实在BERT之后,有人已经研究说明移除BERT的dropout之后,BERT在训练的时候并没有出现过拟合的现象,所以有人在后续的改进中移除了dropout,ALBERT同样移除dropout。
以上就是ALBERT主要的一些操作了,大致可以氛围两个方向,其一是减少参数,其二是弥补参数减少带来的效果损失。另外还有一些比较关键的是,ALBERT想要超过BERT,其实需要更多的训练数据、及加大hidden size。ALBERT是“宽而浅”,BERT是“窄而深”。至于后面的效果对比,可以对照论文。
我所期待
就在写这篇文章的时候,Google更新了ALBERT中文预训练模型V2版本。于是,进行了下面实验。
场景定义为短文本分类,输入长度max_sequence_length=40,训练数据77w,验证数据19w,label 2k+,硬件显卡资源单卡Tesla P100 显存12G。
ALBERT的代码相比BERT整体结构有一点变化,有关DataProcessor和model的代码从run_classifier.py提取出来单独一个classifier_utils.py文件,其他没什么大的变化。
如果遇到“ValueError: Indices have incorrect format: BFH,HO->BFO”这个错误的话,把代码里面的三处“tf.einsum("BFH,HO->BFO", input_tensor, w)”改成对应的小写即可“tf.einsum("bfh,ho->bfo", input_tensor, w)”
对比如下
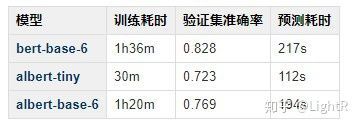
“-6”的意思是只训练bert-base和alber-base的前6层transformer,后面的6层就丢掉了,因为直接训练12层太慢了。
从上图可以看出来:
- albert-tiny是4层transformer,效果最差,速度最快。谁能接受这10个点的准确率损失呢?不知道为啥有人说tiny可以基本保留精度。。。
- 同样是放开6层,bert-base和albert-base对比,albert只快了一点,准确率下降了6个点。我同样也接受不了这6个点下降。。。
所以,同样是base,同样是large,albert比bert好在哪呢?答案是资源,是硬件资源,是显存,其他的性能和inference时间,均没有提高。。。
回到最初的出发点,“效果和BERT一致的情况下,ALBERT应该Inference时间更短”这个是不可能的,从上面那个场景来看,albert-base 12层应该和bert-base 6层的效果一致,多加了6层肯定会大大提高inference时间。
所以我并没有找到把bert升级为albert的理由:
- 同等层数的transformer情况下,bert比albert效果好,albet仅比bert快一点点
- 如果想要降低inference时间,直接减少bert transformer层数就好了,效果损失很小,尤其是对input较短的场景;反而用albert的话,效果损失太大了。
最后有一种场景算是使用albert的理由吧,就是离线运算场景,用albert-xxlarge去fine-tuning task,然后离线inference,毕竟albert-xxlarge是目前最强模型了。(这个模型的时间消耗真的不敢想...)
参考文章:
如何看待瘦身成功版BERT——ALBERT? - Towser的回答 - 知乎 https://www.zhihu.com/question/347898375/answer/839028590