Transformers in NLP (一):图说transformer结构
从transformer开始,nlp的模型渐渐开始成为了transformer一族的天下,所以想写一个系列聊一聊在nlp中那些运用transformer的模型。
作为这个系列的第一篇,就从大名鼎鼎的transformer结构开始。
一、编码器(encoder)与解码器(decoder)
最早提出transformer的文章是attention is all you need,研究的nlp的任务是翻译,自然而然就借鉴了seq2seq的翻译结构,有了编码器(encoder)和解码器(decoder)。
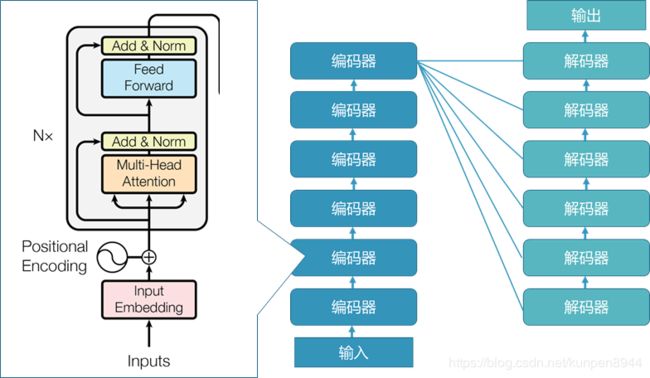
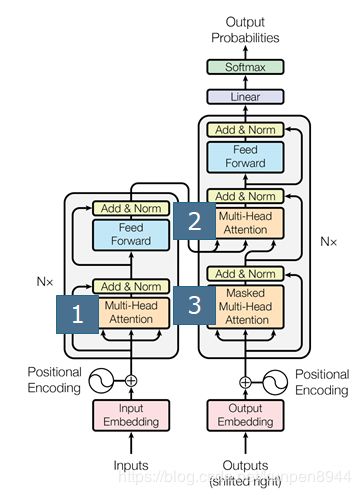
正如下面的图所展示的那样,一个完整的transformer结构是由六个解码器和六个解码器组成,其中六个编码器堆叠而成,最后一层的编码器会将输出输入到每个解码器中。
- 解码器的输入有两部分组成:上一层的解码器的输入(如果是第一层解码器的话是之前翻译的token的embedding)& 最后一层编码器的输入
- 编码器的输入就是上一层的编码器的输出(如果是第一层的编码器的话就是embedding)

1、编码器的结构
六个编码器的结构都是一样的,主要是由:
- 多头自注意力机制(multi-head self-attention mechanism)(下图左框橘色)
- 全连接前馈层(feed forward)(下图左框蓝色)
- 残差网络
- 以及每层都有的层标准化(下图左框黄色)
后面会一个个来介绍。
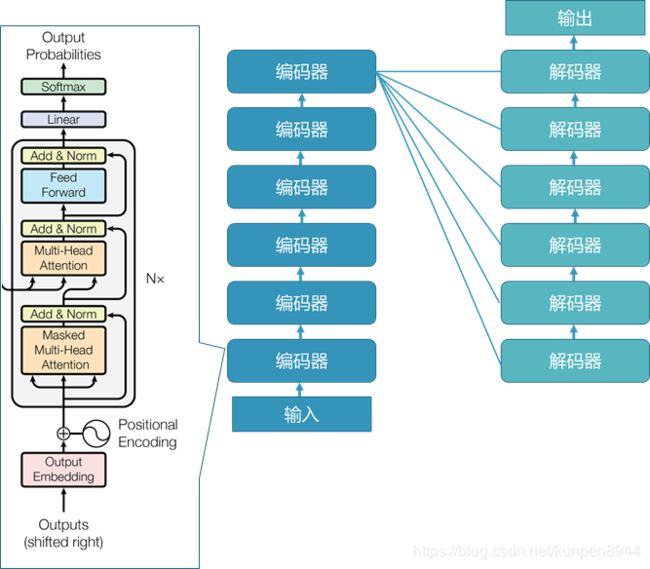
2、解码器的结构
六个解码器的结构都是一样的,主要是由:
- 多头自注意力机制(multi-head self-attention mechanism)(下图左框橘色),解码器会有两种多头自注意力机制,一种是有masked,一种是没有masked
- 全连接前馈层(feed forward)(下图左框蓝色)
- 残差网络
- 以及每层都有的层标准化(下图左框黄色)
二、注意力机制
从上面的介绍可以直观看到,整个transformer模型中,大量出现了一个结构:多头自注意力机制(multi-head attention),为什么叫他“多头”呢,因为他是由很多相似结构的scaled dot-product attention 拼接起来的,直观的展开如下图。

1、scaled dot-product attention
首先,我们来介绍最基本的组成单元:scaled dot-product attention。这部分的输入会有三个:q (query),k (key),v (value)。
假设我们的任务是将 亚热带(中文) 翻译成 아열대 (韩文),scaled dot-product attention的计算流程如下:
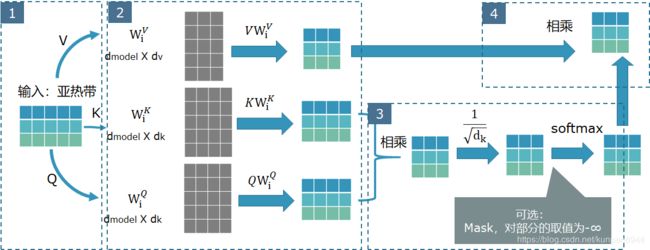
- 第一个框:首先,经过embedding的部分,可以得到“亚热带”三个词对应的embedding,一个seq_length X embedding_dim的矩阵,这里的话就是3X5的矩阵。
- 第二个框:seq_length X embedding_dim的矩阵,分别乘以三个映射(project)矩阵(三个灰色的矩阵WVi,WKi,WQi),三个矩阵分别对应了三个输入k,v,q(在我们的例子中k,q,v都是同一个东西,即第一个框的输出)。结果是得到映射后的表示矩阵,维度分别是:seq_length X dv,seq_length X dk,seq_length X dk。(图里的dmodel就是embedding_dim)
- 第三个框:映射后的k矩阵和q矩阵相乘,得到一个 seq_length X seq_length 的矩阵,通过除以 d k \sqrt{dk} dk和softmax进行归一,这里要注意的是,softmax之前有一个可选的操作mask,也就是之前说的解码器会有的特别的masked多头自注意力层有的机制,目的是将还没预测的序列的信息mask掉。可以看到,这里的矩阵是 seq_length X seq_length ,我们可以将之近似看作是 输入的sequence的所有token之间相关关联系数的矩阵,更准确的说该矩阵的Aij可以理解为是对i对应的token,第j个对应token的权重。
- 第四个框:将第三个框的结果与第二个框中v的映射相乘,简单理解的话,就是基于token和token之间的权重来重新计算这个token投射后的新表征。之前有说法说bert可以学习到基于上下文的单词表征,应该主要也是因为这个结构。
将整个过程用公式表示的话,如下:
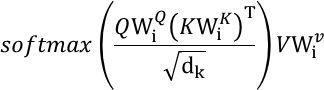
2、multi-head attention
既然已经知道了scaled dot-product attention的结构,那么多头自注意力机制是如何由前者构成的呢?很简单,我们会有h个scaled dot-product attention结构,每个结构中的映射(project)矩阵(三个灰色的矩阵WVi,WKi,WQi)不共享,这样就可以得到h个最终的表示矩阵,将这些结果拼接起来,得到一个seq_length X h dv的矩阵,然后乘以矩阵Wo(维度是h dv X dmodel ),这样就可以得到一个多头自注意力输出矩阵,维度大小为:seq_length X dmodel。在attention is all you need中,h的设置是8,dmodel=512,dk=dv=dmodel/h=64。这样即可以学习到h个不同的映射矩阵,同时计算消耗也和只有一个单头的dk=dv=512的计算复杂度一致。
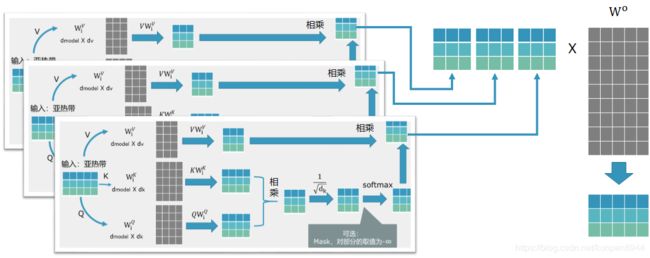
3、transformer中三种多头自注意力机制的应用
在transformer中会有三种多头自注意力机制的应用:
- 下图标1处:Encoder的自注意力层,这一种的k,q,v就是上一层encoder的输出;如果是第一层encoder的话,k,q,v就是都是embedding
- 下图标2处:Encoder-decoder attention,这个结构是在解码器之中,q是同一层解码器中mask mulit-head attention(也就是下图标3处)的输出,k,v是最后一层编码器的输出;
- 下图标3处:Decoder的自注意力层,基本和解码器的自注意力层是一致的,区别是对需要加上一层Masked,将还没预测的序列的信息遮掩掉,采用的方法就是把部分取值设置为-∞,换而言之就是将没预测token embedding对已经预测token embedding的权重影响设置为负无穷,来阻止信息泄露的发生。
三、对encoder-decoder内部结构的一个梳理
看完了transformer的关键结构多头自注意力的介绍,接下来,我们按照模型实际的层,一层层来看一下transformer这个encoder-decoder结构的情况。
1、embedding层
Embedding的作用和在word2vec的模型中一致,但是比较有意思的是下图圈出来的三个部分:output embedding、input embedding以及pre-softmax linear transformation是共享参数的,也就是对于input & output而言,共享embedding意味着这是一个双语的词表(因为transformer使用的是翻译任务)。
我参考了一下其他博客的意见总结下来,共享参数的作用如下:
- 首先,共享参数可以减少参数数目,让模型更容易收敛
- 再次,对于pre-softmax和input&output而言,共享意味着这三个地方的矩阵都可以得到充分训练

2、Positional encoding
- 位置:在input embedding和output embedding之后

- 作用:为了保存token之间的相对或者绝对的位置
- 实现方式:在input embedding的向量基础上,再按位相加一个positional encoding,如下图

- 公式:论文中给出的计算公式如下:pos表示输入字符的位置,2i和2i+1表示输入字符向量的中的对应的位置。
PE(pos,2i)=sin(pos/100002i/dmodel)
PE(pos,2i+1)=cos(pos/100002i/dmodel)
选择这个公式的原因是为了确保相对关系,PEpos+k和PEpos的Positional encoding的差是固定的,这样可以比较好的表示相对关系。有趣的一点是,i从小到大,对应的波长是越来越长的,不知道这样的设定有什么特别的考虑。
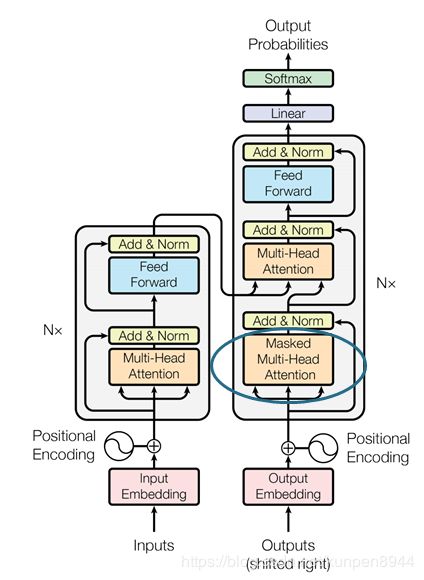
3、Masked Multi-Head Attention
Embedding + postion encoding之后就输入到多头自注意力机制。
Decoder部分比较特别的地方是会有一个masked multi-head attention,我自己理解,这部分是在训练的时候模仿实际推断的场景而设计的结构。在实际的推断过程之中,一句话的推断会经过decoder好几轮,比如“亚热带”的翻译,会先有一个表示句首的字符(比如start)作为outputs输入到decoder,得到第一个翻译的对应字符,随后将start+对应字符输入到decoder,得到第二个翻译的对应字符,以此类推,一直到结束翻译。而在训练的过程中,为了模仿这种效果,在masked multi-head attention中,在自注意力的过程中会对要预测的词以及其左边的词做一个mask,以防信息的泄露,也就是说只能与前文的表征进行自注意力。
4、Add&norm
上面结构图中黄色的部分,表示的公式为LayerNorm(x + Sublayer(x))。这里需要关注两个点:
- 残差网络:在多头注意力机制和feed forward机制的输入在经过网络结构得到输出数据之后,会与原有的输入相加。
- Layer Normalization:对同一层的输出做方差和均值的标准化
5、feed forward
也就是上面结构图的蓝色的部分。
- 这部分的公式如下:FFN(x)=max(0,xW1+b1)W2+b2
- 作用范围:每个position都会做一个这样的转化,每一层转化的参数是一致的,但是在不同的层,参数会不一样。
- 可以理解为,每一层多头注意力输出之后会接一个2048层的全连接层加relu的激活函数,再接一个dmodel的全连接层,这部分被认为是非线性的主要来源。
以上就是我对transformer结构的全部解读。
参考资料
- attention is all you need
- https://www.zhihu.com/question/362131975
- https://blog.csdn.net/longxinchen_ml/article/details/86533005
- https://zhuanlan.zhihu.com/p/60821628