Stanford CoreNLP依存关系分析、词性标注及句子主语分析(使用Python) 超详细截图手把手教学,新手友好
前言
Stanford CoreNLP的源代码是使用Java写的,提供了Server方式进行交互。stanfordcorenlp是一个对Stanford CoreNLP进行了封装的Python工具包,GitHub地址,使用非常方便。本文以stanfordcorenlp接口为例(本文所用版本为Stanford CoreNLP 3.9.1),讲解Python调用StanfordCoreNLP的使用方法。
安装依赖
1:下载安装JDK 1.8及以上版本。
2:下载Stanford CoreNLP文件,解压。
3:处理中文还需要下载中文的模型jar文件,然后放到stanford-corenlp-full-2018-02-27根目录下即可(注意一定要下载这个文件,否则它默认是按英文来处理的)。
常用接口
StanfordCoreNLP官网给出了python调用StanfordCoreNLP的接口。
Python packages using the Stanford CoreNLP server
These packages use the Stanford CoreNLP server that we’ve developed over the last couple of years. You should probably use one of them.
- stanfordcorenlp by Lynten Guo. A Python wrapper to Stanford CoreNLP server, version 3.8.0. Also: PyPI page.
- pycorenlp, A Python wrapper for Stanford CoreNLP by Smitha Milli that uses the new CoreNLP v3.6+ server. Available on PyPI.
- corenlp-pywrap by Sherin Thomas also uses the new CoreNLP v3.6+ server. Python 3.x (only). Also: PyPI page.
- Stanford CoreNLP Python Interface: A reference implementation of a Python interface to the Stanford CoreNLP server. By Arun Chaganty. PyPI page.
- pynlp ,A (Pythonic) Python wrapper for Stanford CoreNLP by Sina. PyPI page.
- NLTK since version 3.2.3 has a new interface to Stanford CoreNLP using the StanfordCoreNLPServer. Among other places, see instructions on using the dependency parser and the code for this module, and if you poke around the documentation, you can find equivalent interfaces to other CoreNLP components; for example here is Stanford CoreNLP NER. Much of the work for this was done by Dmitrijs Milajevs.
1.下载NLP相关包:
网址: https://stanfordnlp.github.io/CoreNLP/index.html
需要下载的包看下图:

2.准备jar包
将下载下来的stanford-corenlp-full-2016-10-31解压并将下载中文的jar文件
stanford-chinese-corenlp-2016-10-31-models.jar放到该目录下。
3.在Python中安装stanfordcorenlp
使用pip安装stanfordcorenlp:
简单使用命令:pip install stanfordcorenlp
选择USTC镜像安装(安装速度很快,毕竟国内镜像):pip install stanfordcorenlp -i http://pypi.mirrors.ustc.edu.cn/simple/ --trusted-host pypi.mirrors.ustc.edu.cn
如果使用Pycharm也可以再设置中安装stanfordcorenlp
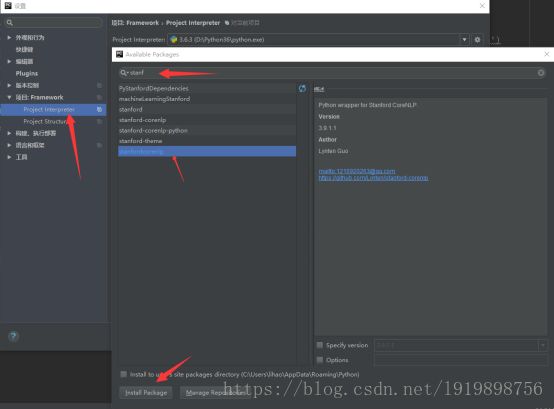
4.在Python环境下调用stanfordcorenlp:
Simple usage
from stanfordcorenlp import StanfordCoreNLP
nlp = StanfordCoreNLP(r'G:\JavaLibraries\stanford-corenlp-full-2018-02-27')
#这里改成你stanford-corenlp所在的目录
sentence = 'Guangdong University of Foreign Studies is located in Guangzhou.'
print 'Tokenize:', nlp.word_tokenize(sentence)
print 'Part of Speech:', nlp.pos_tag(sentence)
print 'Named Entities:', nlp.ner(sentence)
print 'Constituency Parsing:', nlp.parse(sentence)
print 'Dependency Parsing:', nlp.dependency_parse(sentence)
nlp.close() # Do not forget to close! The backend server will consume a lot memery.
Output format:
# Tokenize
[u'Guangdong', u'University', u'of', u'Foreign', u'Studies', u'is', u'located', u'in', u'Guangzhou', u'.']
#Part of Speech
[(u'Guangdong', u'NNP'), (u'University', u'NNP'), (u'of', u'IN'), (u'Foreign', u'NNP'), (u'Studies', u'NNPS'), (u'is', u'VBZ'), (u'located', u'JJ'), (u'in', u'IN'), (u'Guangzhou', u'NNP'), (u'.', u'.')]
# Named Entities
[(u'Guangdong', u'ORGANIZATION'), (u'University', u'ORGANIZATION'), (u'of', u'ORGANIZATION'), (u'Foreign', u'ORGANIZATION'), (u'Studies', u'ORGANIZATION'), (u'is', u'O'), (u'located', u'O'), (u'in', u'O'), (u'Guangzhou', u'LOCATION'), (u'.', u'O')]
# Constituency Parsing
(ROOT
(S
(NP
(NP (NNP Guangdong) (NNP University))
(PP (IN of)
(NP (NNP Foreign) (NNPS Studies))))
(VP (VBZ is)
(ADJP (JJ located)
(PP (IN in)
(NP (NNP Guangzhou)))))
(. .)))
#Dependency Parsing
[(u'ROOT', 0, 7), (u'compound', 2, 1), (u'nsubjpass', 7, 2), (u'case', 5, 3), (u'compound', 5, 4), (u'nmod', 2, 5), (u'auxpass', 7, 6), (u'case', 9, 8), (u'nmod', 7, 9), (u'punct', 7, 10)]如果要分析中文句子可以使用下面的代码:
# _*_coding:utf-8_*_
# Other human languages support, e.g. Chinese
sentence = '清华大学位于北京。'
with StanfordCoreNLP(r'G:\JavaLibraries\stanford-corenlp-full-2018-02-27', lang='zh') as nlp:
print(nlp.word_tokenize(sentence))
print(nlp.pos_tag(sentence))
print(nlp.ner(sentence))
print(nlp.parse(sentence))
print(nlp.dependency_parse(sentence))5.启动CoreNLP服务器命令:
使用过命令
java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -port 9000 -timeout 15000在windows中,再cmd中进入到Stanford CoreNLP目录中执行该命令

现在我们可以使用如下的代码来调用这个server:
# coding=utf-8
from stanfordcorenlp import StanfordCoreNLP
nlp = StanfordCoreNLP('http://localhost', port=9000)
#这里改成了我们server的地址
sentence = 'Functions shall be declared at file scope.'
print(nlp.word_tokenize(sentence))
print(nlp.pos_tag(sentence))
print(nlp.ner(sentence))
print(nlp.parse(sentence))
print(nlp.dependency_parse(sentence))
nlp.close()或者直接在浏览器中访问:

输入句子就能得到直观的结果:
6.分词结果及词性标注:

NNS、VB的意思请见文末的附录
7.依存关系:


上面标注的nsubjpass表示被动的名词主语。可以得到主语是Functions。
附录:
ROOT:要处理文本的语句
IP:简单从句
NP:名词短语
VP:动词短语
PU:断句符,通常是句号、问号、感叹号等标点符号
LCP:方位词短语
PP:介词短语
CP:由‘的’构成的表示修饰性关系的短语
DNP:由‘的’构成的表示所属关系的短语
ADVP:副词短语
ADJP:形容词短语
DP:限定词短语
QP:量词短语
NN:常用名词
NR:固有名词
NT:时间名词
PN:代词
VV:动词
VC:是
CC:表示连词
VE:有
VA:表语形容词
AS:内容标记(如:了)
VRD:动补复合词
CD: 表示基数词
DT: determiner 表示限定词
EX: existential there 存在句
FW: foreign word 外来词
IN: preposition or conjunction, subordinating 介词或从属连词
JJ: adjective or numeral, ordinal 形容词或序数词
JJR: adjective, comparative 形容词比较级
JJS: adjective, superlative 形容词最高级
LS: list item marker 列表标识
MD: modal auxiliary 情态助动词
PDT: pre-determiner 前位限定词
POS: genitive marker 所有格标记
PRP: pronoun, personal 人称代词
RB: adverb 副词
RBR: adverb, comparative 副词比较级
RBS: adverb, superlative 副词最高级
RP: particle 小品词
SYM: symbol 符号
TO:”to” as preposition or infinitive marker 作为介词或不定式标记
WDT: WH-determiner WH限定词
WP: WH-pronoun WH代词
WP$: WH-pronoun, possessive WH所有格代词
WRB:Wh-adverb WH副词
关系表示
abbrev: abbreviation modifier,缩写
acomp: adjectival complement,形容词的补充;
advcl : adverbial clause modifier,状语从句修饰词
advmod: adverbial modifier状语
agent: agent,代理,一般有by的时候会出现这个
amod: adjectival modifier形容词
appos: appositional modifier,同位词
attr: attributive,属性
aux: auxiliary,非主要动词和助词,如BE,HAVE SHOULD/COULD等到
auxpass: passive auxiliary 被动词
cc: coordination,并列关系,一般取第一个词
ccomp: clausal complement从句补充
complm: complementizer,引导从句的词好重聚中的主要动词
conj : conjunct,连接两个并列的词。
cop: copula。系动词(如be,seem,appear等),(命题主词与谓词间的)连系
csubj : clausal subject,从主关系
csubjpass: clausal passive subject 主从被动关系
dep: dependent依赖关系
det: determiner决定词,如冠词等
dobj : direct object直接宾语
expl: expletive,主要是抓取there
infmod: infinitival modifier,动词不定式
iobj : indirect object,非直接宾语,也就是所以的间接宾语;
mark: marker,主要出现在有“that” or “whether”“because”, “when”,
mwe: multi-word expression,多个词的表示
neg: negation modifier否定词
nn: noun compound modifier名词组合形式
npadvmod: noun phrase as adverbial modifier名词作状语
nsubj : nominal subject,名词主语
nsubjpass: passive nominal subject,被动的名词主语
num: numeric modifier,数值修饰
number: element of compound number,组合数字
parataxis: parataxis: parataxis,并列关系
partmod: participial modifier动词形式的修饰
pcomp: prepositional complement,介词补充
pobj : object of a preposition,介词的宾语
poss: possession modifier,所有形式,所有格,所属
possessive: possessive modifier,这个表示所有者和那个’S的关系
preconj : preconjunct,常常是出现在 “either”, “both”, “neither”的情况下
predet: predeterminer,前缀决定,常常是表示所有
prep: prepositional modifier
prepc: prepositional clausal modifier
prt: phrasal verb particle,动词短语
punct: punctuation,这个很少见,但是保留下来了,结果当中不会出现这个
purpcl : purpose clause modifier,目的从句
quantmod: quantifier phrase modifier,数量短语
rcmod: relative clause modifier相关关系
ref : referent,指示物,指代
rel : relative
root: root,最重要的词,从它开始,根节点
tmod: temporal modifier
xcomp: open clausal complement
xsubj : controlling subject 掌控者
中心语为谓词
subj — 主语
nsubj — 名词性主语(nominal subject) (同步,建设)
top — 主题(topic) (是,建筑)
npsubj — 被动型主语(nominal passive subject),专指由“被”引导的被动句中的主语,一般是谓词语义上的受事 (称作,镍)
csubj — 从句主语(clausal subject),中文不存在
xsubj — x主语,一般是一个主语下面含多个从句 (完善,有些)
中心语为谓词或介词
obj — 宾语
dobj — 直接宾语 (颁布,文件)
iobj — 间接宾语(indirect object),基本不存在
range — 间接宾语为数量词,又称为与格 (成交,元)
pobj — 介词宾语 (根据,要求)
lobj — 时间介词 (来,近年)
中心语为谓词
comp — 补语
ccomp — 从句补语,一般由两个动词构成,中心语引导后一个动词所在的从句(IP) (出现,纳入)
xcomp — x从句补语(xclausal complement),不存在
acomp — 形容词补语(adjectival complement)
tcomp — 时间补语(temporal complement) (遇到,以前)
lccomp — 位置补语(localizer complement) (占,以上)
— 结果补语(resultative complement)
中心语为名词
mod — 修饰语(modifier)
pass — 被动修饰(passive)
tmod — 时间修饰(temporal modifier)
rcmod — 关系从句修饰(relative clause modifier) (问题,遇到)
numod — 数量修饰(numeric modifier) (规定,若干)
ornmod — 序数修饰(numeric modifier)
clf — 类别修饰(classifier modifier) (文件,件)
nmod — 复合名词修饰(noun compound modifier) (浦东,上海)
amod — 形容词修饰(adjetive modifier) (情况,新)
advmod — 副词修饰(adverbial modifier) (做到,基本)
vmod — 动词修饰(verb modifier,participle modifier)
prnmod — 插入词修饰(parenthetical modifier)
neg — 不定修饰(negative modifier) (遇到,不)
det — 限定词修饰(determiner modifier) (活动,这些)
possm — 所属标记(possessive marker),NP
poss — 所属修饰(possessive modifier),NP
dvpm — DVP标记(dvp marker),DVP (简单,的)
dvpmod — DVP修饰(dvp modifier),DVP (采取,简单)
assm — 关联标记(associative marker),DNP (开发,的)
assmod — 关联修饰(associative modifier),NP|QP (教训,特区)
prep — 介词修饰(prepositional modifier) NP|VP|IP(采取,对)
clmod — 从句修饰(clause modifier) (因为,开始)
plmod — 介词性地点修饰(prepositional localizer modifier) (在,上)
asp — 时态标词(aspect marker) (做到,了)
partmod– 分词修饰(participial modifier) 不存在
etc — 等关系(etc) (办法,等)
中心语为实词
conj — 联合(conjunct)
cop — 系动(copula) 双指助动词????
cc — 连接(coordination),指中心词与连词 (开发,与)
其它
attr — 属性关系 (是,工程)
cordmod– 并列联合动词(coordinated verb compound) (颁布,实行)
mmod — 情态动词(modal verb) (得到,能)
ba — 把字关系
tclaus — 时间从句 (以后,积累)
— semantic dependent
cpm — 补语化成分(complementizer),一般指“的”引导的CP (振兴,的)