网络爬虫:URL去重策略之布隆过滤器(BloomFilter)的使用
前言:
最近被网络爬虫中的去重策略所困扰。使用一些其他的“理想”的去重策略,不过在运行过程中总是会不太听话。不过当我发现了BloomFilter这个东西的时候,的确,这里是我目前找到的最靠谱的一种方法。
如果,你说URL去重嘛,有什么难的。那么你可以看完下面的一些问题再说这句话。
关于BloomFilter:
Bloom filter 是由 Howard Bloom 在 1970 年提出的二进制向量数据结构,它具有很好的空间和时间效率,被用来检测一个元素是不是集合中的一个成员。如果检测结果为是,该元素不一定在集合中;但如果检测结果为否,该元素一定不在集合中。因此Bloom filter具有100%的召回率。这样每个检测请求返回有“在集合内(可能错误)”和“不在集合内(绝对不在集合内)”两种情况,可见 Bloom filter 是牺牲了正确率以节省空间。
以前的去重策略:
1.想到过的URL去重策略
- 在数据库中创建字段的UNIQUE属性
- 在数据库中创建一个唯一的索引,在插入数据之前检查待插入的数据是否存在
- 使用Set或HashSet保存数据,确保唯一
- 使用Map或是一个定长数组记录某一个URL是否被访问过
2.以上去重策略存在的问题
(1)对于在数据库中创建字段的UNIQUE属性, 的确是可以避免一些重复性操作。不过在多次MySQL报错之后,程序可能会直接崩溃,因此这种方式不可取
(2)如果我们要在每一次插入数据之前都去检查待插入的数据是否存在,这样势必会影响程序的效率
(3)这种方式是我在第一次尝试的时候使用的,放弃继续使用的原因是:OOM。当然,这里并不是程序的内存泄露,而程序中真的有这么多内存需要被占用(因为从待访问队列中解析出来的URL要远比它本身要多得多)
(4)在前几篇博客中,我就有提到使用Map对象来保存URL的访问信息。不过,现在我要否定它。因为,在长时间运行之后,Map也是会占用大量的内存。只不过,会比第3种方式要小一些。下面是使用Map

BloomFilter的使用:
1.一般情况下BloomFilter使用内存的情况:
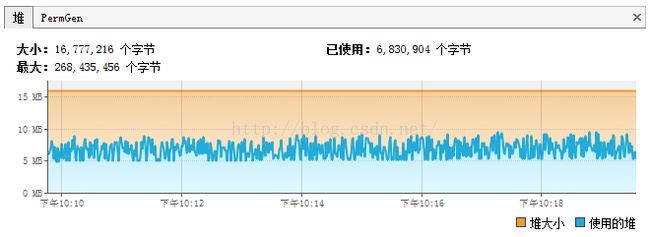
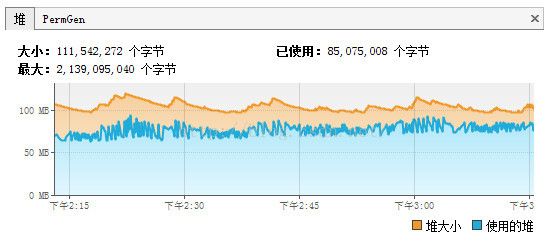
2.爬虫程序中BloomFilter使用内存的情况(已运行4小时):
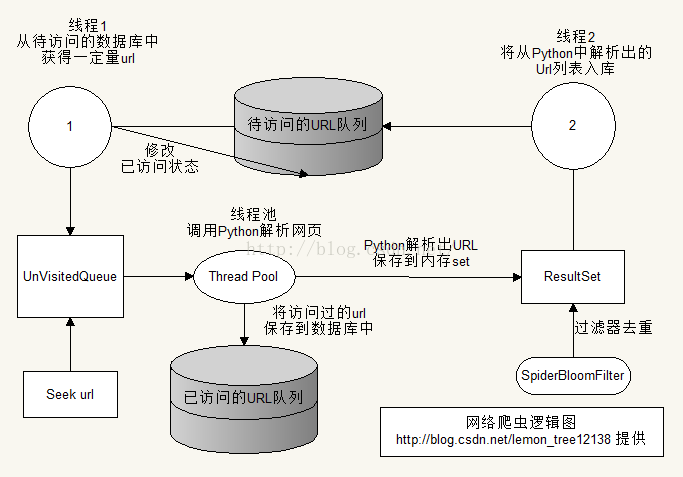
3.程序结构图
4.BloomFilter的一般使用
此处关于BloomFilter的Java代码部分,参考于:http://www.cnblogs.com/heaad/archive/2011/01/02/1924195.html
如果你看了上面的文章,相信你已经了解到布隆过滤器的空间复杂度是S(n)=O(n)。关于这一点,相信你已经从上面的内存使用情况中了解到了这一点。那么以下会是一些相关的Java代码展示。而在查重过程也很有效率,时间复杂度是T(n)=O(1)。
BloomFilter.java
import java.util.BitSet;
public class BloomFilter {
/* BitSet初始分配2^24个bit */
private static final int DEFAULT_SIZE = 1 << 25;
/* 不同哈希函数的种子,一般应取质数 */
private static final int[] seeds = new int[] { 5, 7, 11, 13, 31, 37, 61 };
private BitSet bits = new BitSet(DEFAULT_SIZE);
/* 哈希函数对象 */
private SimpleHash[] func = new SimpleHash[seeds.length];
public BloomFilter() {
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
// 将字符串标记到bits中
public void add(String value) {
for (SimpleHash f : func) {
bits.set(f.hash(value), true);
}
}
// 判断字符串是否已经被bits标记
public boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bits.get(f.hash(value));
}
return ret;
}
/* 哈希函数类 */
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
// hash函数,采用简单的加权和hash
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
return (cap - 1) & result;
}
}
}Test.java
public class Test {
private final String[] URLS = {
"http://www.csdn.net/",
"http://www.baidu.com/",
"http://www.google.com.hk",
"http://www.cnblogs.com/",
"http://www.zhihu.com/",
"https://www.shiyanlou.com/",
"http://www.google.com.hk",
"https://www.shiyanlou.com/",
"http://www.csdn.net/"
};
private void testBloomFilter() {
BloomFilter filter = new BloomFilter();
for (int i = 0; i < URLS.length; i++) {
if (filter.contains(URLS[i])) {
System.out.println("contain: " + URLS[i]);
continue;
}
filter.add(URLS[i]);
}
}
public static void main(String[] args) {
Test t = new Test();
t.testBloomFilter();
}
}
5.BloomFilter在爬虫中过滤重复的URL
public class ParserRunner implements Runnable {
private SpiderSet mResultSet = null;
private WebInfoModel mInfoModel = null;
private int mIndex;
private final boolean DEBUG = false;
private SpiderBloomFilter mFlagBloomFilter = null;
public ParserRunner(SpiderSet set, WebInfoModel model, int index, SpiderBloomFilter filter) {
mResultSet = set;
mInfoModel = model;
mIndex = index;
mFlagBloomFilter = filter;
}
@Override
public void run() {
long t = System.currentTimeMillis();
SpiderQueue tmpQueue = new SpiderQueue();
PythonUtils.fillAddressQueueByPython(tmpQueue, mInfoModel.getAddress(), mInfoModel.getLevel());
WebInfoModel model = null;
while (!tmpQueue.isQueueEmpty()) {
model = tmpQueue.poll();
if (model == null || mFlagBloomFilter.contains(model.getAddress())) {
continue;
}
mResultSet.add(model);
mFlagBloomFilter.add(model.getAddress());
}
tmpQueue = null;
model = null;
System.err.println("Thread-" + mIndex + ", UsedTime-" + (System.currentTimeMillis() - t) + ", SetSize = " + mResultSet.size());
t = 0;
}
@SuppressWarnings("unused")
private void sleep(long millis) {
try {
Thread.sleep(millis);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} 这段代码的功能是:生产者。从待访问队列中消费一个model,然后调用Python生产链接的列表Queue,并将生成的列表Queue offer到结果SpiderSet中。