音视频多模态研究点
音视频多模态研究点介绍
前言
关于多模态的学习,其实有很多的研究领域。在音视频方面主要有以下几个相关论文,这是我参照github上一位作者公布的论文名单:
https://github.com/pliang279/awesome-multimodal-ml#audio-and-visual
下面我简单记录论文的相关工作,为今后的研究作为一个铺垫。论文下载地址在文章末尾。
论文分析
1.Learning Individual Styles of Conversational Gesture
代码: http://people.eecs.berkeley.edu/~shiry/speech2gesture
摘要:人类的言语通常伴随着手势和手臂手势。给定音频语音输入,我们将生成合理的手势以随声音一起移动。具体来说,我们执行跨模式转换,从单个发言人的“狂野”独白语音转换为他们的手和手臂动作;我们在未标记的视频上进行训练,对于这些视频,我们仅从自动姿势检测系统中获得了嘈杂的伪地面真相我们提出的模型在定量比较中明显优于基线方法,为支持对手势和语音之间关系的计算理解的研究,我们发布了一个大型的针对特定手势的视频数据集。可以在此http URL上找到 。

个人理解:这篇文章是通过给定音频的输入,生成一个说话的时候声音动作的描述。并且他制作了相关的数据集。我们可以通过这个数据集来继续开展下一步的工作。
2.Capture, Learning, and Synthesis of 3D Speaking Styles
代码:https://github.com/TimoBolkart/voca
摘要:音频驱动的三维面部动画已经得到了广泛的应用,但实现逼真的、类人的表现仍然是一个未解决的问题。这是由于缺乏可用的3D数据集、模型和标准的评估指标。为了弥补这一点,我们介绍了一个独特的四维面部数据集约29分钟的四维扫描捕获在60帧每秒和同步音频从12个扬声器。然后,我们在数据集上训练一个神经网络,从面部表情来识别身份。在这个学习模型中,VOCA(语音操作字符动画)将任何语音信号作为输入——甚至是英语以外的语言的语音——并逼真地模拟各种各样的成人面孔。在训练过程中对子对象标签进行调整,可以让模型学习各种现实的说话风格。VOCA还提供了一个imator控件,可以在动画过程中改变说话风格、依赖身份的面部形状和姿势(即头部、下巴和眼球转动)。据我们所知,VOCA是唯一被读取的逼真的三维面部动画模型。

个人理解:这篇论文的工作是根据一个声音,还有一个静态的3d图生成说话时候的脸部变化。
3.Disjoint Mapping Network for Cross-modal Matching of Voices and Faces
摘要:我们提出了一个新颖的框架,称为不相交映射网络(DIMNet),用于跨模式生物特征匹配,尤其是声音和面部表情。与现有方法不同,DIMNet没有显式学习模态之间的联合关系。相反,DIMNet通过将它们分别映射到它们的共同协变量来学习不同模态的共享表示。这些共享的表示然后可以用来查找模态之间的对应关系。我们从经验上证明,DIMNet可以比其他当前方法实现更好的性能,并具有从概念上更简单且数据密集度较低的其他好处。

个人理解:通过声音和面部的表情进行一个网络的嵌入。从而更有效地进行识别。这个论文从摘要上看的主要工作还不明显,需要进一步的从论文中阅读。
4.Wav2Pix: Speech-conditioned Face Generation using Generative Adversarial Networks
代码:https://imatge-upc.github.io/wav2pix/
摘要:语音是一种丰富的生物特征信号,其中包含有关说话者的身份,性别和情绪状态的信息。在这项工作中,我们探索了通过使用原始语音输入来调节生成对抗网络(GAN)来生成发言人面部图像的潜力。我们提出了一种深度神经网络,该网络以端到端的方式从头开始进行训练,可直接从原始语音波形生成人脸,而无需任何其他身份信息(例如参考图像或单次热编码)。我们的模型通过利用视频中自然对齐的音频和视频信号,以自我监督的方式进行训练。为了从视频数据中进行训练,我们提供了一个为这项工作而收集的新颖数据集,其中包括高质量的youtuber视频,这些视频在语音和视觉信号方面均具有出色的表现力。
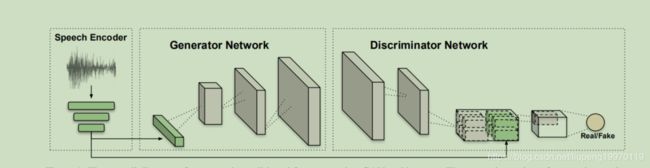
个人理解:通过生成对抗网络生成人的面部。该网络的输入是只有声音,因此我在初步看这篇论文时候,感觉会不会有一些识别精度的难点。但是这篇论文很有意思,后面可以做相关的研究。
5.Jointly Discovering Visual Objects and Spoken Words from Raw Sensory Input
代码:https://github.com/LiqunChen0606/Jointly-Discovering-Visual-Objects-and-Spoken-Words
摘要:在本文中,我们探索了神经网络模型,该模型学习将语音字幕的片段与它们所引用的自然图像的语义相关部分相关联。我们证明,这些视听关联的本地化来自网络内部表示形式,它们是作为执行图像音频检索任务的训练副产品而学习的。我们的模型直接在图像像素和语音波形上运行,并且在训练过程中不依赖任何常规监控,包括标签,分割或模态之间的对齐方式。我们使用Places 205和ADE20k数据集执行分析,表明我们的模型隐式学习了语义耦合的对象和单词检测器。
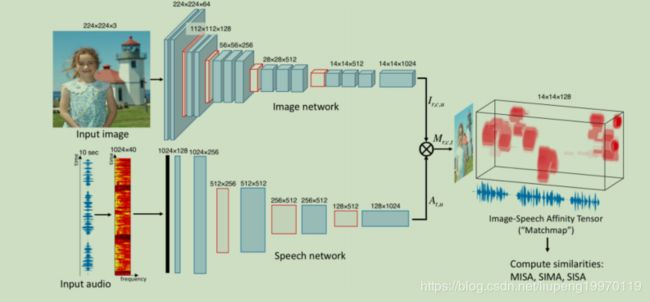
个人理解:这是一个无监督学习。语音字幕中的片段和对应视频中相关部分进行相连。
6.Seeing Voices and Hearing Faces: Cross-modal Biometric Matching
代码:https://github.com/a-nagrani/SVHF-Net
摘要:我们引入了一项看似不可能的任务:仅给某人讲话的音频片段,确定讲话者是两个面部图像中的哪个。在本文中,我们研究了这一问题以及许多相关的跨模式任务,旨在回答以下问题:我们可以从关于面部的声音中推断出多少,反之亦然?我们使用公开可用的数据集,从静态图像(VGGFace)和音频的说话者识别(VoxCeleb)中使用公开的数据集,“在野外”研究此任务。这些为交叉模式匹配的静态和动态测试提供了培训和测试方案。我们做出了以下贡献:(i)我们介绍了用于二进制和多路交叉模式人脸和音频匹配的CNN架构,(ii)比较了动态测试(可提供视频信息,但音频不是来自同一视频,而是经过静态测试(只有一个静止图像可用),并且(iii)我们使用人工测试作为基准来校准任务的难度。我们展示了CNN确实可以在静态和动态场景中都经过训练来解决此任务,并且甚至在给定声音的情况下对人脸进行10次分类的可能性也大大超过了。CNN在简单示例(例如,两张面孔上的性别不同)上与人类表现相匹配,但在更具挑战性的示例(例如,具有相同性别,年龄和国籍的面孔)上,其表现优于人类。甚至在给定声音的情况下对人脸进行10种分类的机会都大大超过了。CNN在简单示例(例如,两张面孔上的性别不同)上与人类表现相匹配,但在更具挑战性的示例(例如,具有相同性别,年龄和国籍的面孔)上,其表现优于人类。甚至在给定声音的情况下对人脸进行10种分类的机会都大大超过了。CNN在简单示例(例如,两张面孔上的性别不同)上与人类表现相匹配,但在更具挑战性的示例(例如,具有相同性别,年龄和国籍的面孔)上,其表现优于人类。
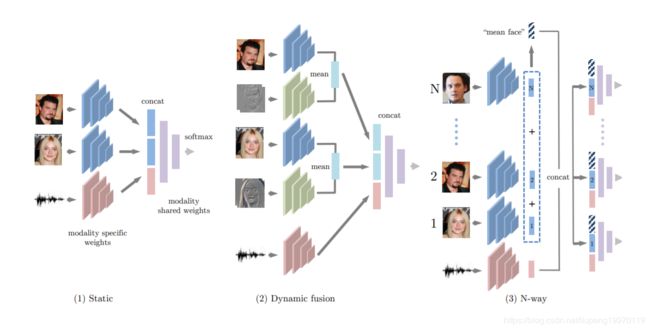
个人理解:仅通过某个人说话的声音片段就能确定是哪一个人在说话。
7.Learning to Separate Object Sounds by Watching Unlabeled Video
摘要:介绍了一种新颖的声源分离方法,实现了这种直观感觉。我们的方法首先对大量未加注释的视频进行处理,以发现每个可见对象的潜在声音表示。特别地,我们使用最先进的图像识别工具来推断每个视频片段中出现的对象,并且我们在每个视频的audic通道上执行非负矩阵分解(NMF)来恢复其频率基向量集。在这一点上,它是未知的音频基地,以配合哪些视觉对象(s)。为了恢复这种关联,我们构造了一个多实例多标签学习(MIML)的新网络,将音频库映射到被检测到的视觉对象的分布。从这个音频基对象关联网络中,我们提取了与每个可视对象相连接的音频基,从而得到了其典型的光谱模式。最后,给出了一个新的视频,我们使用学习的每对象音频基来进行音频源分离。
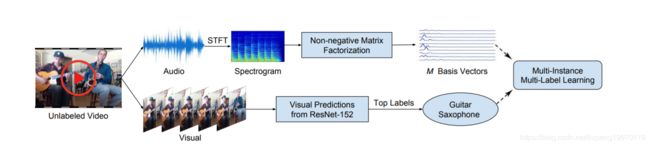
个人理解:理解事物的本质和场景,一般我们是通过看。但是声音也是一种理解。这篇论文使用没有标签的视频。把他们分为音频和图像。对他们进行一个特征的融合,分离对象的声音。。
8.Deep Audio-Visual Speech Recognition
摘要:这项工作的目的是识别有语音或无语音的说话人说话的短语和句子。与以前专注于识别有限数量的单词或短语的作品不同,我们将唇读作为一个开放世界的问题来解决-不受限制的自然语言句子和野外视频。我们的主要贡献是:(1)我们比较了两种用于唇读的模型,一种使用CTC损失,另一种使用序列间损失。两种模型都建立在变压器自我关注架构的基础上。(2)我们研究唇读在多大程度上与音频语音识别相辅相成,特别是当音频信号有噪声时;(3)我们引入并公开发布了用于视听语音识别的新数据集LRS2-BBC,其中包括来自英国电视台的数千个自然句子。

个人理解:这个没看太懂。大致意思好像是通过音频和嘴唇的变化更准确的把语言翻译出来。
9.Look, Listen and Learn
摘要:我们考虑这样一个问题:通过观看和收听大量未标记的视频,我们能学到什么?视频本身包含了一个有价值的,但迄今为止尚未开发的信息来源——视频流和音频流之间的对应关系,我们介绍了一个利用这一点的新颖的“视听对应”学习任务。从零开始训练视频和音频网络,除了原始的无约束视频本身之外,不需要任何额外的监督,可以成功地解决这个任务,更有趣的是,可以得到良好的视频和音频表示。这些特性在两个完善的分类基准上设置了新的最先进技术,并与ImageNet分类上的最先进的自监督方法相媲美。我们还演示了该网络能够在两种模式中定位对象,以及执行细粒度的识别任务。
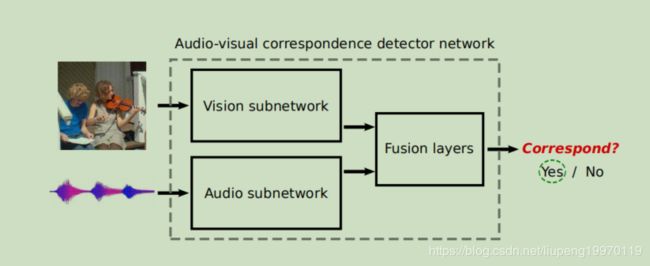
个人理解:通过输入视频中的音频和图像部分判断这两个数据是不是同一个关联数据。
10.Unsupervised Learning of Spoken Language with Visual Context
摘要:人类在会读或写之前就学会了说话,那么为什么计算机不能做同样的事情呢?在本文中,我们提出了一种深层神经网络模型,该模型能够使用未转录的音频训练数据进行初级口语习得,其唯一的监督形式是上下文相关的视觉图像。我们描述了我们的数据的收集,包括超过12万个地方图像数据集的语音字幕,并在一个图像搜索和注释任务上评估我们的模型。我们还提供了一些可视化,这表明我们的模型正在学习识别标题光谱图中的有意义的单词。

个人理解:通过上下文的视觉图像监督学习音频单词。在这篇论文中,以学习跨音频和视觉模式的高级语义概念。来自多种模式的相关传感器数据流——在本例中是一个视觉图像,伴随着描述该图像的语音字幕——被用来训练网络,使其能够使用未标记的训练数据发现模式。例如,这些网络能够从连续的语音信号中找出“水”这个词的实例,并将它们与包含水体的图像联系起来。网络直接从数据中学习这些关联,而不使用传统的语音识别、文本转录或任何专业的语言知识。
11.SoundNet: Learning Sound Representations from Unlabeled Video
代码: http://projects.csail.mit.edu/soundnet/
摘要:我们利用在野外收集的大量未标记声音数据来学习丰富的自然声音表示。我们利用视觉和声音之间的自然同步来学习使用200万个未标记视频的声音表示。未标记的视频的优点是可以经济地大规模获取,但仍包含有关自然声音的有用信号。我们提出了一个学生-教师培训程序,该程序使用未标记的视频作为桥梁,将成熟的视觉识别模型中的辨别性视觉知识转换为声音模态。与声音场景/对象分类的标准基准上的最新结果相比,我们的声音表示可显着提高性能。
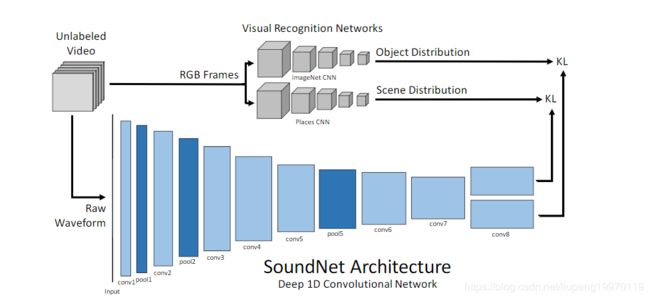
个人理解:从没有标签的视频中学习声音场景和对象分类。该网络的模型向比较。其他的标准模型更为准确。
论文下载
链接:https://pan.baidu.com/s/19tHKvfO10Y6KRwPRt8951w
提取码:1dt0
复制这段内容后打开百度网盘手机App,操作更方便哦