对hbase调优首先需要对hbase架构有一个初步认知。

hbase写数据
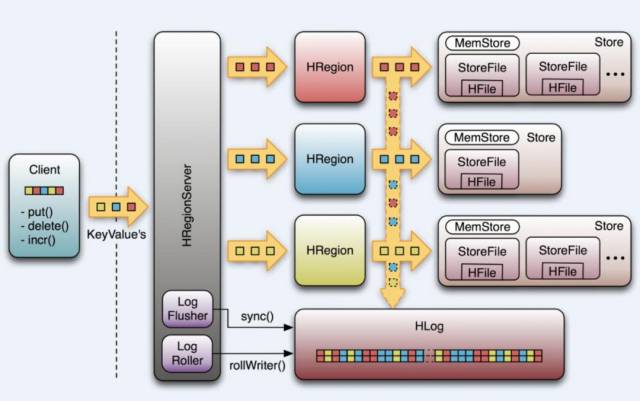
在HBase 中无论是增加新行还是修改已有的行,其内部流程都是相同的。HBase 接到命令后存下变化信息,或者写入失败抛出异常。
默认情况下,执行写入时会写到两个地方:
1、预写式日志(write-ahead log,也称HLog);
2、MemStore。
HBase 的默认方式是把写入动作记录在这两个地方,以保证数据持久化。只有当这两个地方的变化信息都写入并确认后,才认为写动作完成。
MemStore 是内存里的写入缓冲区,HBase 中数据在永久写入硬盘之前在这里累积。当MemStore 填满后,其中的数据会刷写到硬盘,生成一个HFile。HFile 是HBase 使用的底层存储格式。HFile 对应于列族,一个列族可以有多个HFile,但一个HFile 不能存储多个列族的数据。在集群的每个节点上,每个列族有一个MemStore。
hbase读数据
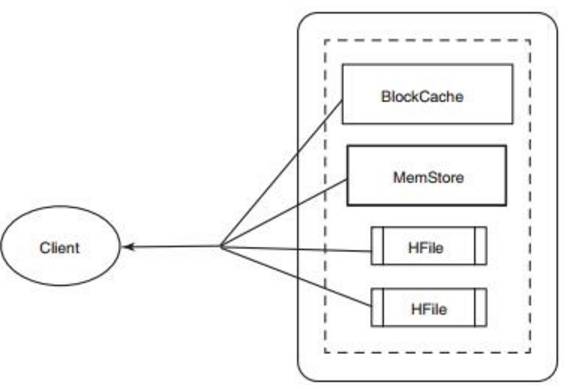
如果想快速访问数据,通用的原则是数据保持有序并尽可能保存在内存里。HBase实现了这两个目标,大多情况下读操作可以做到毫秒级。HBase 读动作必须重新衔接持久化到硬盘上的HFile 和内存中MemStore 里的数据。HBase 在读操作上使用了LRU(最近最少使用算法)缓存技术。这种缓存也叫做BlockCache,和MemStore 在一个JVM 堆里。BlockCache 设计用来保存从HFile 里读入内存的频繁访问的数据,避免硬盘读。每个列族都有自己的BlockCache。掌握BlockCache 是优化HBase 性能的一个重要部分。
BlockCache 中的Block 是HBase从硬盘完成一次读取的数据单位。HFile 物理存放形式是一个Block 的序列外加这些Block的索引。这意味着,从HBase 里读取一个Block 需要先在索引上查找一次该Block 然后从硬盘读出。Block 是建立索引的最小数据单位,也是从硬盘读取的最小数据单位。Block大小按照列族设定,默认值是64 KB。从HBase 中读出一行,首先会检查MemStore 等待修改的队列,然后检查BlockCache看包含该行的Block 是否最近被访问过,最后访问硬盘上的对应HFile。
hbase调优
1、g1收集器 vs cms收集器
cms收集器在物理上区分年轻代和年老代空间。g1收集器会将heap分成很多region,然后在逻辑上区分年轻代和年老代空间。g1收集器主要用于控制垃圾回收的时间。对于hbase使用场景,大部分老年代的对象是memstore或者blockcache。对比测试发现cms收集器有更好的表现。
cms配置调优
设置较大的heap size。使用CMSInitiatingOccupancyFraction=70。值70为JVM的使用百分比,当达到这个阈值后将启动回收任务。这个值比较合适的值是要略大于memstoresize 40%+ blockcache 20%。如果CMSInitiatingOccupancyFraction这个值小于60%会导致频繁gc报警。
新生代收集器UseParNewGC
使用UseParNewGC收集器,并加大新手代空间大小占heap size 25%,因为memstore(40%)加blockcache(20%)占总heap的60%,这两部分空间会被存放到年老代空间。所以新生代空间不应该大于1-60%.让更多的gc发生在新生代,UseParNewGC可以并行的收集,收集成本低。
TargetSurvivorRatio设置
TargetSurvivorRatio=90设置 Survivor 区的可使用率。这里设置为 90%,则允许 90%的 Survivor 空间被使用。默认值是 50%。故该设置提高了 Survivor 区的使用率。当存放的对象超过这个百分比,则对象会向年老代压缩。因此,这个选项更有助于将对象留在年轻代。
启用gc压缩
使用UseCMSCompactAtFullCollection和CMSFullGCsBeforeCompaction=4。
2、swap的设置
推荐设置为0,这样只有在物理内存不够的情况下才会使用交换分区。这个参数设置是由于JVM虚拟机如果使用了swap在GC回收时会花费更多的时间。
3、开启特性MSLAB
hbase.hregion.memstore.mslab.enabled=true.MLAB特性是在分析了HBase产生内存碎片的根因后给出了解决方案,这个方案虽然不能够完全解决Full GC带来的问题,但是一定程度上延缓了full GC的产生间隔。
4、加大MSLAB 分配方式分配的块区大小
hbase.hregion.memstore.mslab.chunksize默认值为2MB。修改为6MB。如果这个值较小会报警:压缩队列空间不足。
5、加大hbase.hregion.memstore.block.multiplier
默认值为2,增大到6.如 memstore 的大小增加到 hbase.hregion.memstore.block.multiplier 的值乘以 hbase.hregion.flush.size=256mb字节的值,则块将写入。此设置可用于在更新流量快速增长时防止超过 memstore。
6、设置hbase.hregion.majorcompaction
hbase.hregion.majorcompaction=7天。一个星期做一次majorcompaction.
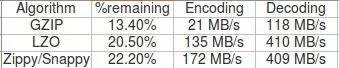
7、选择SNAPPY压缩算法
启用压缩可以大大提高集群的可用性,scan性能显著提升。目前HBase默认支持的压缩算法包括GZ,LZO以及snappy.测试对比之后选择SNAPPY压缩算法
针对特定场景优化在点融hbase主要用来写入数据和scan查询。
密集型场景优化
调大hbase.hregion.max.filesize=2GB
该参数决定底层存储文件(HStoreFile)的最大大小。该参数定义了region的大小。如果列族存储的文件超过这个大小,该region将被拆分。region越大意味着在写的时候拆分越小。
调大hbase.hregion.memstore.flush.size=256MB
该参数定义MemStore的大小,当MemStore超过这个大小时会被刷写到硬盘。一个周期性运行的线程会检查MemStore的大小。刷写到HDFS的数据越多,生成的Hfile越大,会在写的时候减少生成文件的数量,从而减少合并的次数
设置hbase.hregion.memstore.mslab.enabled=true
MemStore-Local Allocation Buffer是Hbase的一个特性,在发生写密集型负载时,它有助于防止堆的碎片化。如果堆太大,打开这个特性有助于减轻垃圾回收暂停时间太长的问题。
设置hbase.regionserver.global.memstore.upperLimit=0.4和hbase.regionserver.global.memstore.lowerLimit=0.4
upperLimit定义在一个RegionServer上MemStore总共可以使用的堆的最大百分比。
遇到upperLimit的时候MemStore被刷写到硬盘,直到遇到lowerLimit时停止,把这两个参数的值设置为彼此相等意味着发生的刷写数据量最小,那时因为upperLimit一直被遇到所以写操作被阻塞。这样做会把写过程中的暂停时间降到最短,但是也会导致更加频繁的刷写动作。可以在每台RegionServer上增加分配给MemStore的堆的比例,但也不要走极端,因为这会导致垃圾回收问题。把upperLimit设置为能够容纳每个region的MemStore乘以每个Region Server上预期的region数量。
顺序读取密集型业务优化
设置BLOCKSIZE =>'262144'
对于特定的表可以增大HFile数据块的大小。数据块越大,则每次硬盘寻道时间可以却处的数据越多。调大此值测试性能是否有所提升。如果此值太大,为扫面定位起始键的时候性能会降低。
设置hbase.client.scanner.caching=500
该参数定义了在扫描器上调用next方法时取回的行的数量。该数字越高,在扫描过程中客户端向Region Server发出的RPC调用越少。该数字越高也意味着客户端使用的内存越多。
关闭数据块缓存
通过Scan.setCacheBlocks()API来关闭数据块的缓存。把一个扫描器读取的所有数据块放进块缓存会导致翻腾缓存的次数太多。对于大规模扫描,可以把此参数设置为false来关闭数据块的缓存。
关闭表的缓存
设置BLOCKCACHE=>'false'.如果一张表主要使用大规模扫描的访问方式,那么他的缓存很可能不会提升性能。相反,你会不断的翻腾缓存,影响其他较小的随机读访问方式的表。可以关闭块缓存以便每次扫描时不再翻腾缓存。
对表进行slat
设置一个较小的slat值,让table的数据分成更少的region在每次扫描的时候可以从一个region中读取更多的数据,从而减少磁盘的寻道时间。
设置VERSIONS=>'1'
对于不需要多版本的数据,设置列族的VERSIONS=1可以加快hbase扫描速度。
参考文献:
1.《hbase实战 Nick Dimiduk,Amandeep Khurana著》
2. Avoiding Full GCs with MemStore-Local Allocation Buffers:http://www.slideshare.net/cloudera/hbase-hug-presentation
本文作者:李振环(点融黑帮),来自点融Data组。对分布式和大数据有浓厚兴趣,目前兴趣包括Web开发和大数据应用,爱玩羽毛球、乒乓球、篮球等运动。