视觉SLAM中的对极约束、三角测量、PnP、ICP问题
这篇博客是在学习高翔《视觉SLAM十四讲》过程中对计算机视觉的多视图几何相关知识点做的总结,个人觉得这部分内容比较难,有理解不对的地方请指正!
〇、ORB特征点
对于特征点法的SLAM来说,ORB(Oriented FAST and Rotated BRIEF)特征应该是目前最合适的特征点了。ORB与SIFT、SURF之间的性能对比如下:
- 计算速度:ORB >> SURF >> SIFT(各差一个量级)
- 旋转鲁棒性:SURF > ORB ~ SIFT
- 模糊鲁棒性:SURF > ORB ~ SIFT
- 尺度变换鲁棒性:SURF > SIFT > ORB(ORB算法在尺度方面效果较差)
特征点由关键点和描述子两部分组成,对于ORB特征点来说,它使用的是FAST关键点+BRIEF描述子。
FAST是一种角点,主要检测局部像素灰度变化明显的地方,以速度快著称。但FAST角点本身并不具有尺度和方向信息,针对这一问题,ORB算法通过构建图像金字塔,并在金字塔的每一层上检测角点来实现FAST的尺度不变性;用灰度质心法来实现FAST的旋转不变性。在ORB中,将这种可以描述角点尺度与旋转特性的FAST称为Oriented FAST。
BRIEF是一种二进制描述子,为关键点添加描述子的作用是为了实现图像之间的特征匹配。BRIEF使用了随机选点的比较,速度非常快,而且由于使用了二进制表达,存储起来也十分方便。但原始的BRIEF描述子不具有旋转不变性,图像发生旋转时容易丢失,针对这一问题,ORB算法利用在FAST角点提取阶段计算出的关键点方向信息,使BRIEF具有了较好的旋转不变性。
有了ORB特征点,我们需要用它来做图像间的特征匹配。所谓特征匹配,就是比较特征点的相似度,这个相似度通过它们的描述子来计算。对于BRIEF这种二进制的描述子,通常使用汉明距离(Hamming distance)来度量两个特征点之间的相似程度。汉明距离是指两个长度相等的字符串之间不同数据位的个数,例如:两个8位的二进制串00110100与10110100,它们之间只有第一个数据位不同,所以它们的汉明距离为1。在ORB的特征匹配中,汉明距离越小,特征点的相似度越高,在某种程度上,我们可以认为两个特征点在两帧图像中为同一个点,即完成了特征匹配。
特征匹配在视觉SLAM中真的是至关重要的一步,设想一下,假如每一帧图像都能实现100%的正确匹配,那我们就不再需要各种令人头疼的滤波、优化、回环检测等等,这将是一个多么美好的画面啊啊啊。。。但,现实告诉你,绝大部分的图像之间是不可能做到100%正确匹配的,所以说,SLAM的主要工作在后端,就是如何利用不准确的数据估计得到准确的结果。
当然,下面总结的在视觉SLAM中经常用到的,非常重要的,Multiple View Geometry in Computer Vision中的,比较难以理解又容易混淆的几个算法,都是在理想的特征匹配结果之上推导出来的。
一、对极几何
对极几何(Epipolar geometry)又叫对极约束,是根据图像二维平面信息来估计单目相机帧间运动或双目相机相对位姿关系的一种算法。直观来讲,当相机在两个不同视角对同一物体进行拍摄时,物体在两幅图像中的成像肯定会有不同,那么,根据这两幅不同的图像,我们如何判断出相机的位姿发生了怎样的变化,这正是对极几何要解决的问题。
需要明确的是,在对极几何中,我们的已知条件仅仅是每幅图像中特征点的像素坐标,当然,计算对极约束的前提是我们必须知道两幅图像中特征点之间准确的匹配关系。
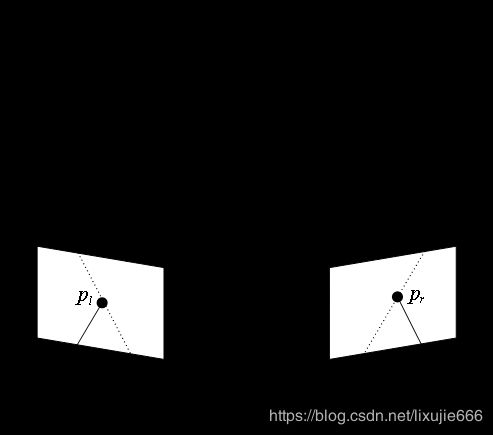
|
如图1所示,以其中一对匹配点为例。 P P P为空间中的一点(坐标未知),其在左边图像中的投影为 p l = [ u l , v l , 1 ] T \color{#F00}p_l=[u_l,v_l,1]^\text T pl=[ul,vl,1]T,在右边图像中的投影为 p r = [ u r , v r , 1 ] T \color{#F00}p_r=[u_r,v_r,1]^\text T pr=[ur,vr,1]T,当我们以相机坐标系 O L O_L OL为参考坐标系时,有:
(1) { s l p l = K P s r p r = K ( R P + t ) ⟹ { s l K − 1 p l = P s r K − 1 p r = R P + t \begin{cases} s_lp_l = KP \\ s_rp_r = K(RP+t) \end{cases}\implies \begin{cases} s_lK^{-1}p_l = P \\ s_rK^{-1}p_r = RP+t \end{cases}\tag{1} {slpl=KPsrpr=K(RP+t)⟹{slK−1pl=PsrK−1pr=RP+t(1)
其中 s l s_l sl、 s r s_r sr分别为点 P P P在相机坐标系 O L O_L OL、 O R O_R OR中的 z z z坐标值(即深度), K K K为 3 × 3 3\times 3 3×3的相机内参矩阵, R R R、 t t t即为 O L O_L OL与 O R O_R OR之间的相对位姿关系。取 x l = K − 1 p l , x r = K − 1 p r \color{#F0F}x_l=K^{-1}p_l,\,x_r=K^{-1}p_r xl=K−1pl,xr=K−1pr,则有:
(2) { s l x l = P s r x r = R P + t ⟹ s r x r = R ( s l x l ) + t ⟹ s r x r = s l R x l + t \begin{cases} s_lx_l = P \\ s_rx_r = RP+t \end{cases}\implies s_rx_r = R(s_lx_l)+t\implies s_rx_r = s_lRx_l+t\tag{2} {slxl=Psrxr=RP+t⟹srxr=R(slxl)+t⟹srxr=slRxl+t(2)
上式两边同时左乘 t t t的反对称矩阵 t ∧ t^\wedge t∧,相当于两侧同时与 t t t做外积( t t t与自身的外积 t ∧ t = 0 t^\wedge t=\bf 0 t∧t=0):
(3) s r t ∧ x r = s l t ∧ R x l s_rt^\wedge x_r=s_lt^\wedge Rx_l\tag{3} srt∧xr=slt∧Rxl(3)
然后,两侧同时左乘 x r T x_r^{\text T} xrT:
(4) s r x r T t ∧ x r = s l x r T t ∧ R x l s_rx_r^{\text T}t^\wedge x_r=s_lx_r^{\text T}t^\wedge Rx_l\tag{4} srxrTt∧xr=slxrTt∧Rxl(4)
上式左侧中, t t t与 x r x_r xr的外积 t ∧ x r t^\wedge x_r t∧xr是一个与 t t t和 x r x_r xr都垂直的向量,所以,再将 x r T x_r^{\text T} xrT与 t ∧ x r t^\wedge x_r t∧xr做内积,其结果必为 0 0 0,从而有:
(5) s l x r T t ∧ R x l = 0 ⟹ s l ( K − 1 p r ) T t ∧ R ( K − 1 p l ) = 0 ⟹ p r T K -T t ∧ R K − 1 p l = 0 \color{#F00}s_lx_r^{\text T}t^\wedge Rx_l=0\implies s_l(K^{-1}p_r)^{\text T}t^\wedge R(K^{-1}p_l)=0\implies p_r^{\text T}K^{\text {-T}}t^\wedge RK^{-1}p_l=0\tag{5} slxrTt∧Rxl=0⟹sl(K−1pr)Tt∧R(K−1pl)=0⟹prTK-Tt∧RK−1pl=0(5)
(5)式以非常简洁的形式描述了两幅图像中匹配点对 p l p_l pl和 p r p_r pr之间存在的数学关系,这种关系就叫对极约束。另外,我们称 E = t ∧ R \color{#F00}E=t^\wedge R E=t∧R为本质矩阵(Essential Matrix),称 F = K -T t ∧ R K − 1 = K -T E K − 1 \color{#F00}F=K^{\text {-T}}t^\wedge RK^{-1}=K^{\text {-T}}EK^{-1} F=K-Tt∧RK−1=K-TEK−1为基础矩阵(Fundamental Matrix),于是(5)式可以进一步简化为:
(6) x r T E x l = p r T F p l = 0 x_r^{\text T}Ex_l=p_r^{\text T}Fp_l=0\tag{6} xrTExl=prTFpl=0(6)
OK,现在我们需要重新明确一下对极几何的工作:对极几何是要利用已知的 n n n对如上述 p l p_l pl、 p r p_r pr这样的匹配点(二维像素坐标),来计算相机的运动 R R R、 t t t,即求解本质矩阵 E E E或基础矩阵 F F F。具体求解过程可参看《视觉SLAM十四讲》P143-148。
对极几何存在的问题:根据对极约束求解得到的相机旋转运动 R R R是准确的,平移运动 t t t是不具备真实尺度的。
二、三角测量
三角测量(Triangulation)又叫三角化,是根据前后两帧图像中匹配到的特征点像素坐标以及两帧之间的相机运动 R R R、 t t t,计算特征点三维空间坐标的一种算法。直观来讲,当有两个相对位置已知的相机同时拍摄到同一物体时,如何根据两幅图像中的信息估计出物体的实际位姿,即通过三角化获得二维图像上对应点的三维结构,这正是三角测量要解决的问题。

|
如图2所示为三角测量基本原理的示意图,该图与图1非常相似,但应该注意其中的区别:此时我们已经知道了 O L O_L OL与 O R O_R OR的关系, p l p_l pl、 p r p_r pr也是已知的,要求的是点 P P P的三维空间坐标。由(1)式我们知道,要求点 P P P的三维坐标,需要先求深度 s s s;由(2)式我们有:
(7) s r x r = s l R x l + t s_rx_r = s_lRx_l+t\tag{7} srxr=slRxl+t(7)
对上式两侧左乘一个 x r x_r xr的反对称矩阵 x r ∧ x_r^\wedge xr∧,得:
(8) s r x r ∧ x r = s l x r ∧ R x l + x r ∧ t ⟹ s l x r ∧ R x l + x r ∧ t = 0 s_rx_r^\wedge x_r = s_lx_r^\wedge Rx_l+x_r^\wedge t\implies s_lx_r^\wedge Rx_l+x_r^\wedge t=\bf 0\tag{8} srxr∧xr=slxr∧Rxl+xr∧t⟹slxr∧Rxl+xr∧t=0(8)
(8)式是一个超定方程组(Overdetermined system),通常只能求得它的最小二乘解。当我们求出 s l s_l sl后,根据(7)式就很容易求出 s r s_r sr,最后由(1)式,我们有:
(9) { s l K − 1 p l = P O L , P O L 表示点 P 在相机坐标系 O L 下的三维坐标 s r K − 1 p r = P O R , P O R 表示点 P 在相机坐标系 O R 下的三维坐标 \begin{cases} s_lK^{-1}p_l = P_{O_L}, & \text {$P_{O_L}$表示点$P$在相机坐标系$O_L$下的三维坐标 }\\ s_rK^{-1}p_r = P_{O_R}, & \text {$P_{O_R}$表示点$P$在相机坐标系$O_R$下的三维坐标 } \end{cases}\tag{9} {slK−1pl=POL,srK−1pr=POR,POL表示点P在相机坐标系OL下的三维坐标 POR表示点P在相机坐标系OR下的三维坐标 (9)
上式中 P O L P_{O_L} POL与 P O R P_{O_R} POR之间的关系为:
(10) P O R = R P O L + t P_{O_R}=RP_{O_L}+t\tag{10} POR=RPOL+t(10)
即:以 O L O_L OL坐标系为参考, O R O_R OR经过运动 R R R、 t t t变换到 O L O_L OL,那么原来在 O L O_L OL坐标系下的点 P P P在 O R O_R OR坐标系下表示为 P O R = R P O L + t P_{O_R}=RP_{O_L}+t POR=RPOL+t。如果我们还知道相机与世界坐标系的变换关系 T T T,就可以将 P O L P_{O_L} POL或 P O R P_{O_R} POR转换到世界坐标系下表示,得到点 P P P的世界坐标。
三、PnP问题
PnP(Perspective-n-Point)是根据图像中特征点的二维像素坐标及其对应的三维空间坐标,来估计相机在参考坐标系中位姿的一类算法。直观来讲,当相机观察到空间中的某一物体时,我们已经知道了该物体在某一参考坐标系下的位置和姿态,那么如何通过图片中物体的成像判断出相机此时在参考坐标系下的位姿?这正是PnP要解决的问题,即利用已知三维结构与图像的对应关系求解相机与参考坐标系的相对关系(相机的外参)。
PnP是一类问题,针对不同的情况有不同的解法,常见的算法有:P3P、DLS、EPnP、UPnP等。

|
如图3所示,考虑空间中某个点 P P P,它在世界坐标系 O w O_w Ow中的齐次坐标为 P = [ x , y , z , 1 ] T P=[x,y,z,1]^{\text T} P=[x,y,z,1]T,其投影到图像中的像素坐标为 p = [ u , v , 1 ] T p=[u,v,1]^{\text T} p=[u,v,1]T。假设此时相机坐标系 O c O_c Oc与世界坐标系 O w O_w Ow之间的相对位姿关系由 R R R、 t t t来描述,则有:
(11) s [ u v 1 ] = K [ R t ] [ x y z 1 ] = [ f x 0 u 0 0 f y v 0 0 0 1 ] [ r 11 r 12 r 13 t 1 r 21 r 22 r 23 t 2 r 31 r 32 r 33 t 3 ] [ x y z 1 ] \color{#F00} s\begin{bmatrix} u \\ v \\ 1 \\ \end{bmatrix} = K\left[\begin{array}{c|c}R&t\end{array}\right]\begin{bmatrix} x\\y\\z\\1 \end{bmatrix} = \begin{bmatrix} f_x&0&u_0 \\0 &f_y&v_0\\0&0&1\end{bmatrix} \left[ \begin{array}{ccc|c} r_{11}&r_{12}&r_{13}&t_1 \\ r_{21}&r_{22}&r_{23}&t_2 \\ r_{31}&r_{32}&r_{33}&t_3 \end{array} \right] \begin{bmatrix}x\\y\\z\\1\end{bmatrix}\tag{11} s⎣⎡uv1⎦⎤=K[Rt]⎣⎢⎢⎡xyz1⎦⎥⎥⎤=⎣⎡fx000fy0u0v01⎦⎤⎣⎡r11r21r31r12r22r32r13r23r33t1t2t3⎦⎤⎣⎢⎢⎡xyz1⎦⎥⎥⎤(11)
其中的 R = [ r 1 r 2 r 3 ] = [ r 11 r 12 r 13 r 21 r 22 r 23 r 31 r 32 r 33 ] R=\begin{bmatrix}\bf r_1&\bf r_2&\bf r_3\end{bmatrix}=\begin{bmatrix}r_{11}&r_{12}&r_{13}\\r_{21}&r_{22}&r_{23}\\r_{31}&r_{32}&r_{33}\end{bmatrix} R=[r1r2r3]=⎣⎡r11r21r31r12r22r32r13r23r33⎦⎤、 t = [ t 1 t 2 t 3 ] t=\begin{bmatrix}t_1\\t_2\\t_3\end{bmatrix} t=⎣⎡t1t2t3⎦⎤即为我们要求的旋转矩阵与平移向量,其实它俩就是所谓的相机外参。通过相机的外参可以将世界坐标系下的点转换到相机坐标系下表示,通过相机的内参可以将相机坐标系下的点转换到像素坐标系下表示。
为了简化表示,我们暂时不考虑相机内参(因为内参 K K K是已知且不变的),并令 T 34 = [ R t ] = [ r 11 r 12 r 13 t 1 r 21 r 22 r 23 t 2 r 31 r 32 r 33 t 3 ] = [ t 11 t 12 t 13 t 14 t 21 t 22 t 23 t 24 t 31 t 32 t 33 t 34 ] = [ τ 1 τ 2 τ 3 ] T_{34}=\left[\begin{array}{c|c}R&t\end{array}\right]=\left[\begin{array}{ccc|c}r_{11}&r_{12}&r_{13}&t_1\\r_{21}&r_{22}&r_{23}&t_2\\r_{31}&r_{32}&r_{33}&t_3\end{array}\right]=\begin{bmatrix}t_{11}&t_{12}&t_{13}&t_{14}\\t_{21}&t_{22}&t_{23}&t_{24}\\t_{31}&t_{32}&t_{33}&t_{34}\end{bmatrix} = \begin{bmatrix}\bf{\tau_1}\\ \bf{\tau_2}\\ \bf{\tau_3}\end{bmatrix} T34=[Rt]=⎣⎡r11r21r31r12r22r32r13r23r33t1t2t3⎦⎤=⎣⎡t11t21t31t12t22t32t13t23t33t14t24t34⎦⎤=⎣⎡τ1τ2τ3⎦⎤,则上式可表示为:
s [ u v 1 ] = [ t 11 t 12 t 13 t 14 t 21 t 22 t 23 t 24 t 31 t 32 t 33 t 34 ] [ x y z 1 ] = [ τ 1 τ 2 τ 3 ] P s\begin{bmatrix} u \\ v \\ 1 \\ \end{bmatrix} =\begin{bmatrix}t_{11}&t_{12}&t_{13}&t_{14}\\t_{21}&t_{22}&t_{23}&t_{24}\\t_{31}&t_{32}&t_{33}&t_{34}\end{bmatrix}\begin{bmatrix}x\\y\\z\\1\end{bmatrix} = \begin{bmatrix}\bf{\tau_1}\\ \bf{\tau_2}\\ \bf{\tau_3}\end{bmatrix}P s⎣⎡uv1⎦⎤=⎣⎡t11t21t31t12t22t32t13t23t33t14t24t34⎦⎤⎣⎢⎢⎡xyz1⎦⎥⎥⎤=⎣⎡τ1τ2τ3⎦⎤P
用最后一行把 s s s 消去( s = τ 3 P s={\bf\tau_3}P s=τ3P),得到两个约束:
u = τ 1 P τ 3 P , v = τ 2 P τ 3 P u=\frac{{\bf\tau_1}P}{{\bf\tau_3}P} \quad,v=\frac{{\bf\tau_2}P}{{\bf\tau_3}P} \quad u=τ3Pτ1P,v=τ3Pτ2P
于是有:
(12) { τ 1 P − τ 3 P u = 0 , τ 2 P − τ 3 P v = 0. \begin{cases} {\bf\tau_1}P-{\bf\tau_3}P\,u=0, \\ {\bf\tau_2}P-{\bf\tau_3}P\,v=0. \end{cases}\tag{12} {τ1P−τ3Pu=0,τ2P−τ3Pv=0.(12)
可以看到,每个特征点提供了两个关于 T 34 T_{34} T34 的线性约束,而 T 34 T_{34} T34 中有12个未知数,所以理论上至少需要6对匹配点就可以求出 T 34 T_{34} T34 。
四、ICP问题
ICP(Iterative Closest Point)是根据前后两帧图像中匹配好的特征点在相机坐标系下的三维坐标,求解相机帧间运动的一种算法。直观来讲,当相机在某处观察某一物体时,我们知道了相机此时与物体之间的相对位姿关系;当相机运动到另一处,我们亦知道此时相机与物体的相对位姿关系,那么,如何通过这两次相机与物体的相对位姿关系来确定相机发生了怎样的运动?这正是ICP要解决的问题。
在ICP问题中,图像信息仅仅用来做特征点的匹配,而并不参与视图几何的运算。也就是说,ICP问题的求解用不到相机的内参与特征点的像素坐标。

|
如图4所示,设空间中一点 P P P在相机坐标系 O L O_L OL下的坐标为 P O L = [ x l , y l , z l ] T P_{O_L}=[x_l,y_l,z_l]^{\text T} POL=[xl,yl,zl]T,在相机坐标系 O R O_R OR下的坐标为 P O R = [ x r , y r , z r ] T P_{O_R}=[x_r,y_r,z_r]^{\text T} POR=[xr,yr,zr]T, O L O_L OL经过运动 R R R、 t t t到达 O R O_R OR,则 P O L P_{O_L} POL与 P O R P_{O_R} POR之间的关系为:
(13) P O L = R P O R + t P_{O_L}=RP_{O_R}+t\tag{13} POL=RPOR+t(13)
写成齐次变换的形式:
(14) [ x l y l z l 1 ] = [ R t ] [ x r y r z r 1 ] = [ r 11 r 12 r 13 t 1 r 21 r 22 r 23 t 2 r 31 r 32 r 33 t 3 ] [ x r y r z r 1 ] \begin{bmatrix} x_l \\ y_l \\ z_l \\ 1 \\ \end{bmatrix}=\left[\begin{array}{c|c}R&t\end{array}\right]\begin{bmatrix} x_r \\ y_r \\ z_r \\ 1 \\ \end{bmatrix}=\left[\begin{array}{ccc|c}r_{11}&r_{12}&r_{13}&t_1\\r_{21}&r_{22}&r_{23}&t_2\\r_{31}&r_{32}&r_{33}&t_3\end{array}\right]\begin{bmatrix} x_r \\ y_r \\ z_r \\ 1 \\ \end{bmatrix}\tag{14} ⎣⎢⎢⎡xlylzl1⎦⎥⎥⎤=[Rt]⎣⎢⎢⎡xryrzr1⎦⎥⎥⎤=⎣⎡r11r21r31r12r22r32r13r23r33t1t2t3⎦⎤⎣⎢⎢⎡xryrzr1⎦⎥⎥⎤(14)
由此可见,每一个点 P P P可以得到3个约束,那么理论上至少需要4个点就可以求得相机的运动 R R R、 t t t。