学习笔记------Actional-Structural Graph Convolutional Networks for Skeleton-based Action Recognition
Actional-Structural Graph Convolutional Networks for Skeleton-based Action Recognition
基于骨架信息使用 动作-结构 图卷积网络进行行为识别
投稿:
上海交通大学合作媒体网络创新中心
三菱电机研究所
华为诺亚方舟研究室
收录:CVPR2019
Abstract
基于骨架信息的行为识别近些年来在计算机视觉领域收到了广泛关注。之前的研究大多数都是基于固定骨架图,仅仅捕捉了本身具有物理依赖性作用的节点之间的信息,这种做法可能会失去节点之间的相关性信息(joint correlations)。为了捕捉更加丰富的依赖信息,我们引入了一个编码器结构,叫做A-link推理模块,去捕捉特定动作的潜在依赖关系,即直接来自动作的actional links。我们也扩展了现存的骨架图来表达高阶的依赖性,即structural links。将两种类型的link模块结合成一个广义骨架图,我们也进一步提出了行为-结构图卷及网络,即AS-GCN,AS-GCN将行为-动作图卷积和时序卷积堆叠在一起生成一个基础构建模块,从而学习空间和时序特征进行行为识别。并行添加A future pose prediction head和the recognition head,来帮助通过自监督捕获更详细的行为模式。我们在验证验证AS-GCN在行为识别上的效果时使用了两种骨架数据集,NTU-RGB+D和Kinetics. 我们提出来的AS-GCN和现有的效果比较好的方法相比有很大的提升。作为一个边缘产品,AS-GCN在未来姿态预测方面也达到了预期的效果. 我们的可用代码放在:https://github.com/limaosen0/AS-GCN
Introduction
人体行为识别广泛适用于视频监视,人机交互和虚拟现实方面,最近在计算机视觉领域受到了很多关注.通过动态3D关节位置表示的骨架信息已经被证明在动作表示方面是有效的,在传感器噪声方面具有鲁棒性,并且都可以进行计算和存储.骨骼数据通常通过使用深度传感器定位关节点的2D或3D空间坐标或使用姿态估计来获得.
最早的骨架动作识别尝试将每个视频帧中的所有身体关节位置编码为特征向量以进行模式学习. 这样建立的模型很难关注到身体各个关节点之间具有的依赖性,从而会丢失大量的动作信息.为了捕获关节点之间的依赖关系,最近有人设计出了人体的骨架图,在骨架图中,顶点代表的是关节点,边代表的是骨骼,并且应用了图卷积网络来提取相关特征.The spatio-temporal GCN(ST-GCN)被进一步用来同时学习时间特征和空间特征.尽管ST-GCN提取了通过骨骼直接连接的关节的特征,但在结构伤较远得关节在很大程度上会被忽略.例如,在走路时,手和脚紧密相关.虽然ST-GCN尝试将较宽范围的特征与分层GCN进行聚合,但在长时间扩散过程中节点特征可能会减弱.
我们尝试构造广义骨架图来捕获关节之间更丰富的依赖性.特别是,我们以数据驱动方式推断action-link(A-link)来捕获关节点之间潜在的依赖关系.类似于参考文献[16]中提出了一种具有编码器-解码器结构的A-link推理模块(AIM).我们还扩展了骨架图,以将更高阶的关系表示为结构链接(S-link).基于带有A-links和S-links的广义图,我们提出了一种actional-structural图卷积以捕捉空间特征.我们进一步提出了Action-Structural 图卷积网络(AS-GCN),该网络堆叠了多个Actional-Structural卷积和时间卷积.作为一个利用骨架来进行识别的网络,AS-GCN能够适用于各种环境.这里我们将行为识别作为主要任务,将未来姿态预测作为次要任务,the prediction head通过保留细节特征来促进自监督学习和提升识别精度.
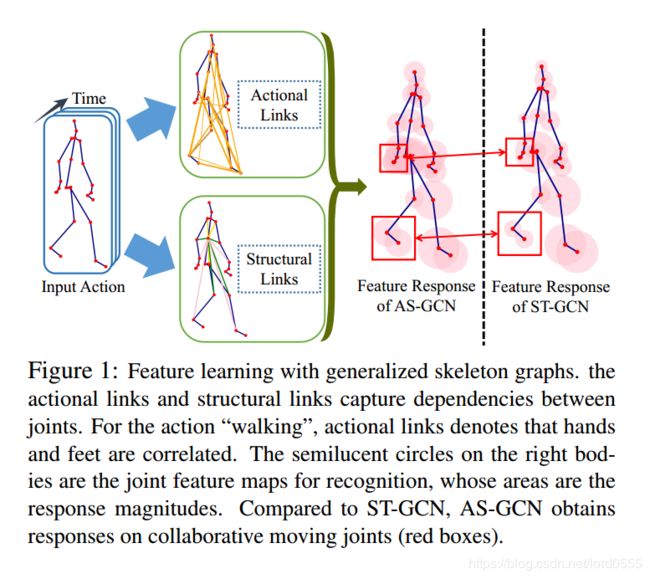
上图表示了本文提出的AS-GCN模型的特征,我们通过学习 actional-link, 扩展structural links 来进行行为识别.上面的特征映射表示,与仅使用骨架图对局部关系建模的ST-GCN相比,我们能够抓取更加全面的信息.
为了验证AS-GCN的有效性,我们在两个不同的大型数据集上进行了广泛的实验,这两个数据集是NTU-RGB+D和Kinetics.这个实验已经证明了AS-GCN在行为识别方面由于现在工人比较先进的方法.除此之外,AS-GCN能够准确的预测未来的帧,表明已经捕获了详细的细节信息.本篇文章主要的贡献主要有如下几点:
1. 我们提出了一个A-link推理模型(AIM)来推测可捕获特定动作的潜在关系的actional-links.the actional link 和structural links结合成为广义骨架图.细节见Figure 1
2. 我们提出了动作-结构图卷积网络(AS-GCN)基于多个图来提取有用的空间和时间信息;详细信息参见Figure 2
3. 我们引入了一个额外的未来姿态预测头来预测未来的姿态,这个预测头通过提取更多的细节行为模式来提高识别的效果.
4. 本文提出的AS-GCN在两个大型数据集的表现优于很多现在比较先进的方法;在另一方面,AS-GCN也能够精确地进行未来姿态的预测;

2. Related Works
骨架数据被广泛用于行为识别.基于手工制作和基于深度学习的方法开发出了很多算法.第一种方法设计出来的算法基于物理直觉来抓取行为模式,例如局部占用特征,时间协方差和Lie group curves. 另一方面,基于深度学习的方法从数据中自动学习行为特征.一些基于RNN的模型在连续帧之间抓取时序依赖性,例如bi-RNN,deep LSTMS, 和基于注意力的模型. CNN也达到了不错的效果,例如residual temporal CNN, information enhancement model和关于动作表示的CNN. 近期,随着能够对身体关节点关系的灵活运用,基于图的方法吸引了很多关注.在我们的工作中,我们将基于图的方法应用于行为识别.从很多之前不同的方法中,我们从数据中自适应的学习图, 从而在行为中捕获有用的非本地信息.
3. Background
在这一部分,我们介绍了本文其余部分所需的背景材料.