超级简单易懂的决策树介绍:什么是决策树,如何构建决策树
这个笔记是根据我看这个视频来记的:https://www.youtube.com/watch?v=7VeUPuFGJHk&t=0s&list=PLyeGvkJQKy7nDT5kH9S99_p51DcDRQEIR&index=3
所有图片都来自于该视频。
什么是决策树
在介绍决策树之前,先解释一下如下几个概念:

根结点:如图所示只有子节点,没有父节点的节点,叫做根节点。
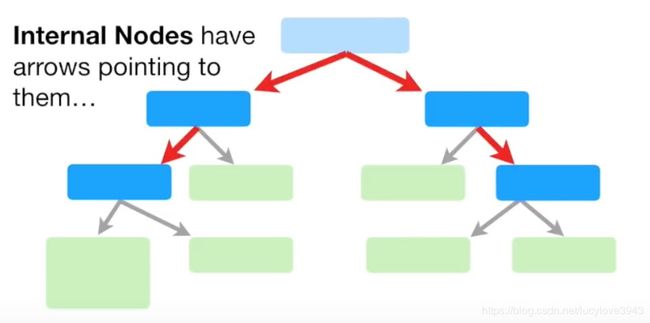
内部节点(节点):如图所示既有父节点,也有子节点的节点。它也被称为节点。
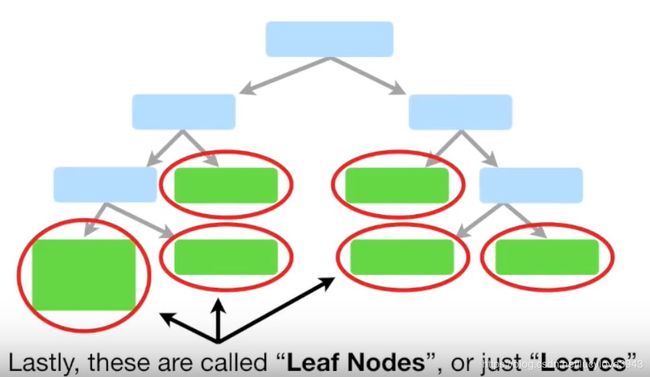
叶子结点:如图所示仅仅只有父节点的节点叫做叶子结点。
那么决策树是什么呢?
简单来说决策树就是一棵树,其中跟节点和内部节点是输入特征的判定条件,叶子结点就是最终结果。
可以看看下面这个例子,这是一个判断是否应该做运动的决策树:

这是一个相对比较复杂的决策树。根据年龄,静止心率,还有是否吃甜甜圈来判断一个人是否应该做运动。每一个绿色的叶子结点代表了一个结果。值得注意的是:
- 并不是每一层的内部节点内容都一样,比如第二层左边是静止心率的判断,右边是是否吃甜甜圈的判断
- 对于同一个特征,判断标准也不一定,比如说左边子树判断心率是和100bpm比较,但是右子树判断心率是和120bpm比较
- 左右子树对于特征判断的顺序也不一定一样,比如左子树是先判断心率再判断是否吃甜甜圈,但是右子树是先判断吃甜甜圈,再判断心率
如何构造决策树
如下图所示,训练数据的输入一共有三个特征:是否胸痛,血液循环状况是否良好,动脉血管是否有阻塞,输出是是否有心脏病。目的是根据这些训练数据来建立一个决策树。

第一步:选择根节点
建立决策树的第一步,就是要选择合适的特征座位跟节点。那么选择的依据是什么呢?
选择依据:选择能够尽可能最好分类是否患有心脏病的特征作为根节点。
(在这里我们不考虑缺失数据,也就是第四组数据那种情况。第四组数据没有动脉血管阻塞信息,我们就跳过那个数据)
首先来看第一个特征,是否胸痛对最终结果的影响:

左边代表的是,对于有胸痛的患者,一共有105个人有心脏病,39个人没有心脏病。
同样的,右边表示了:对于没有胸痛的患者,一共有34个人有心脏病,125个人没有。
相似的,作者整合了对于另外两个特征的情况:


下一步,就是看每个特征,对于是否有心脏病的分类效果如何了。
但是如何定量来判断一个特征的分类效果呢?这里介绍的指标是Gini指数,他是用来衡量一组数据的不纯度。
可以这样来理解不纯度:当我们用胸口疼分类的时候,并不是所有胸口疼的人都有心脏病,也不是所有胸口不疼的人都没有心脏病,我们可以把这种情况理解为不纯粹。Gini指数就是用来定量的衡量不纯粹的程度。
对于胸口疼这个特征左子树的Gini指数计算方法如下:

对于左子树,是1-yes概率的平方-no概率的平方。右子树也是类似的计算方法:

总的Gini指数用加权平均来算:
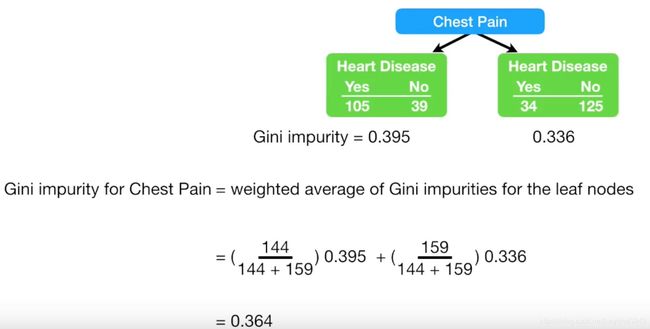
为什么是144和159?左子树的总人数是144,右子树的总人数是159.
相似的,可以算出所有特征的Gini指数:

回到一开始的问题,选择跟节点。
跟节点就是对应Gini指数最小的特征!因为Gini指数衡量的是不纯度,所以不纯度越低,说明分类效果越好。
在这里就是血液循环这个特征。
第二部:选择内部节点和叶子节点
根据前面的结果,现在我们已经选好了根结点。但是仅仅有根节点的分类是不够的,因为分类之后的结果还是不纯的,如下图所示:

所以我们要想办法,根据另外两个特征,进一步构建决策树。同样的,也是通过计算Gini指数来构建。
把前面根节点分好类的数据作为输入,计算各个子树的Gini指数:

这里动脉阻塞的Gini指数更小,我们将动脉阻塞作为左子树的第一个内部节点,结果如下图所示:

最后就是要看看,胸口疼这个特征对分类的影响:
对于左子树,根据胸口疼这个特征的进一步分类,我们可以计算出新的分类结果,如下图所示:

注意到,一开始动脉阻塞的分类结果,是24个人有心脏病,25个人没有。而引入了胸痛之后,是否有心脏病被分类的更清楚了。
现在来看看左子树下面的右子树,值得注意的是,目前是否有心脏病的比例是13/102,约等于89%的人没有心脏病。
如果我们引入胸口疼之后,结果如下:

可以看到,引入了心口疼之后,分类效果还不如不引入它。所以这里我们就不引入胸口疼了。
至此,我们就构建完了左侧的决策树。类似的,也可以构建右侧的决策树。
总结起来,就是下图:

数值类特征:如何构建决策树
前面介绍了如何构造决策树。但是针对的都是答案是yes和no的特征,如果说特征是数值类的呢。比如我们在上一个例子中引入体重,体重就不再是一个yes和no的答案了,如下图所示。
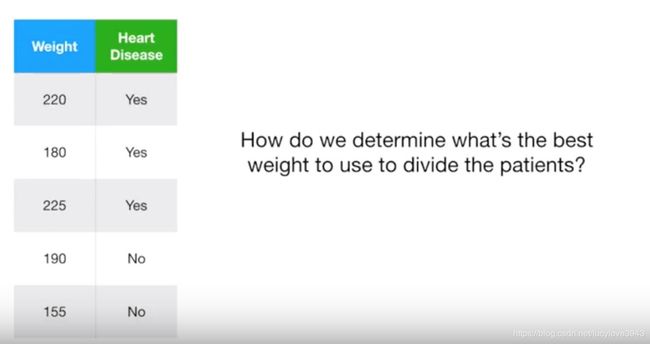
那么这种情况应该怎么办呢?
- 第一步,对体重进行排序
- 第二部,计算平均值
- 第三部,计算各个体重段的Gini指数
如下图所示:

当体重小于167.5的时候,计算出左子树的Gini指数。类似的,可以计算出右子树的Gini指数,从而得到总的Gini指数。

同样的方法,我们计算出所有的Gini指数,如下图:

选择Gini指数最小的,作为最终的Gini指数,去和其他特征比较。
所以总的来说,对于数值类型的特征,计算会更复杂一些。不过整个决策树的构造就是计算Gini指数,万变不离其宗。
类似的,除了Gini指数,还有其他衡量不纯度的指标,对应着其他不同类型的决策树。
但是其本质都是一样的,只要看懂了本文,其余也相对比较容易融会贯通。