
在了解Fork-Join之前,我们得先了解什么是并行计算。
并行计算
相对于串行计算,并行计算可以划分成时间并行和空间并行。时间并行即指令流水化,也就是流水线技术。比如说生产一辆小汽车,有特定的轮子车间/发动机车间,同时进行各自的生产。空间并行是指使用多个处理器执行并发计算。
以程序和算法设计人员的角度看,并行计算又可分为数据并行和任务并行。数据并行把大的任务化解成若干个相同的子任务,任务并行是指每一个线程执行一个分配到的任务,而这些线程则被分配(通常是操作系统内核)到该并行计算体系的各个计算节点中去。
简单来说,并行计算是通过把大问题划分为小问题,运用计算机资源并行的处理子问题,当需要得到大问题的结果时,将小问题的结果按顺序合并起来得到最终结果。这种思想就是分治思想,小到归并排序,大到大数据计算...
Fork-Join
Fork-Join框架是Doug Lea 大神在JDK7引入的。Fork就是把大问题拆分成小问题,也就是大任务拆成多个子任务,并行执行子任务。Join就是把任务的结果按顺序合并起来。
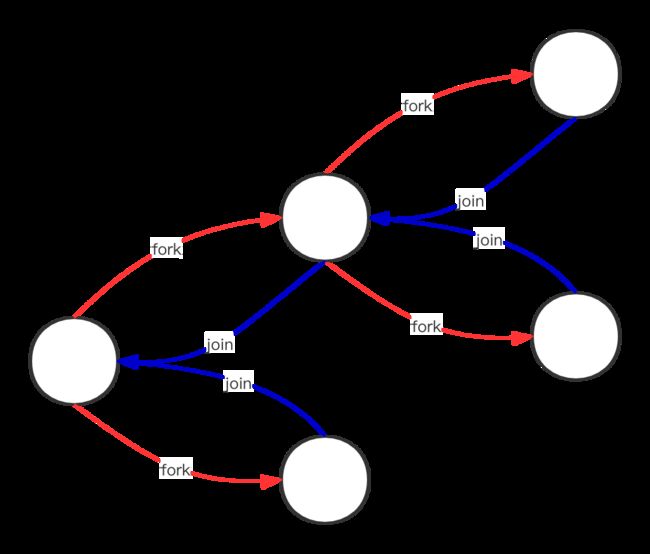
假设我们需要求从 1-1亿之间的数字和,按照Fork-Join的思想,可分为以下三步:
1.定义拆分子任务和合并子任务的规则
- 划分子任务的规则
首先将任务拆为 1-5千万 和 5千万01 - 1亿两个子任务,直到每个子任务计算的数字范围在1万以内的时候,我们才计算这个任务的和。
- 合并子任务的规则
同一父任务的所有子任务的结果再相加,就是这一父任务的结果。
2.充分利用计算机资源,最大并行的执行子任务
3.充分利用计算机资源,执行合并所有子任务,获得最终的结果
显然一般人做不了后两步,我们只需要把 怎么拆,怎么和 告诉Fork-Join框架,Fork-Join框架就帮我们做好 如何最大并行执行子任务 和 如何最有效合并子任务。
设计原理
如何充分利用计算机资源,最大并行执行子任务?一般小伙伴应该可以想到使用多线程,让线程数等于CPU核数。此时可以充分利用CPU的计算资源。
我们来看一下JDK普通线程池是咋玩的。(不要说你不懂为啥池化 :)
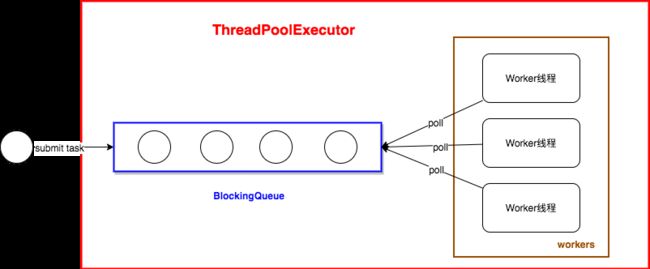
任务都是丢到一个同步队列BlockingQueue中的。如果你了解JDK BlockingQueue的实现,就知道有界的同步队列都是用锁阻塞的,有些push/poll操作还共用一把锁。
问题1:并行的任务有必要共用一个阻塞队列吗?
问题2: 如果任务队列中的任务存在依赖,worker线程只能被阻塞着。啥意思呢?
假设任务队列中存在两个任务task1和task2,task1的执行结果依赖于task2的结果。如果worker1先拉取到task1,结果发现此时task2还没有被执行。则worker1只能阻塞等待别的worker拉取到task2,task2执行完了worker1才能继续执行task1。
如果worker1当发现task1无法继续执行下去时,能够先把它放一边,继续拉取任务执行。这样效率是比较高的。
Work−Stealing
Fork-Join框架通过Work−Stealing算法解决上面两个问题。
-
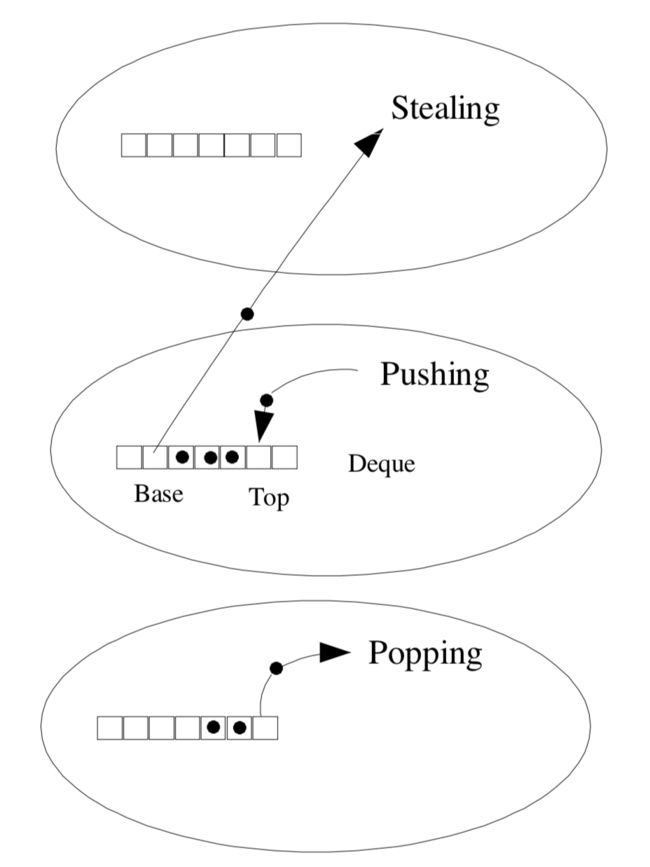
每个
线程拥有自己的任务队列,并且是双端队列。 -
线程操作
自己的任务队列是LIFO(Last in First out)模式。 -
线程还可以偷取
别的线程任务队列中的任务,模式为FIFO(First in First out)。
显然 每个线程拥有自己的任务队列可以提高获取队列的并行度,
双端任务队列将所属的自己线程的push/pop操作 和 其他线程的steal操作通过不同的模式区分开。这样只有当Base==Top-1时,pop操作和steal操作才会有冲突。
如何才能准确及时知道Base==Top-1呢,Fork-Join框架的牛逼之处也在于对任务的调度是轻量级的。
steal操作
考虑steal操作,是多个其他线程的同步操作。需要保证:偷到Base处的任务和Base++的原子性,同时Base的值一旦改变,其他线程应该能够马上可见。聪明的小伙伴是不是想到 锁和volatile 了:)
//steal操作 就是 poll()方法
final ForkJoinTask poll() {
ForkJoinTask[] a; int b; ForkJoinTask t;
//array就是双端队列,实际用数组实现。
//base是将要偷的任务下标,base是用volatile修饰的,保证可见性
//top是将要push进去的任务下标,可参考上面示意图
while ((b = base) - top < 0 && (a = array) != null) {
//说明经过while条件初步判断任务队列不为空
//获取base处的任务在任务队列中的偏移量
int j = (((a.length - 1) & b) << ASHIFT) + ABASE;
//用volatile load 语义取出base处的任务t,可以简单理解为一定是最新修改版本的任务
t = (ForkJoinTask)U.getObjectVolatile(a, j);
//再次读取base,判断此时t是否被别的线程偷走
if (base == b) {
if (t != null) {
//如果多次读判断都没啥问题,CAS修改base处的任务t为null
if (U.compareAndSwapObject(a, j, t, null)) {
//如果上面修改成功,表示这个任务被该线程偷到了
//此时就将base指针向前移一位,注意这一步是原子操作,base++就不是了
base = b + 1;
return t;
}
}
else if (b + 1 == top)
// 如果t==null && b + 1 == top,此时任务队列为空
break;
}
}
return null;
}
简单来说,有任务可偷时,通过CAS偷任务保证只有一个线程能偷成功,偷成功的这个线程接着修改volatile base指针,使得马上对其他线程可见。同时通过前面的多次读判断减少后期CAS并发的冲突概率。
没任务可偷时,通过CAS偷任务失败可以判断出来。
请小伙伴一句句看上面的代码,阿姨都注释出来了。虽然上面并没有锁,,但是小伙伴想想锁其实是悲观控制并发的思想,是不是可以拆成多次读判断 + CAS原子修改的乐观思想来控制并发。只要最终保证只有一个能修改成功就可以了。
push操作
考虑push操作,是任务队列所属的线程才能操作,天生线程安全:
不需要通过CAS或锁来保证同步,只需要原子的修改top处任务 和 top向前移一位 就可以了。
同理,top也不需要用volatile修饰。
final void push(ForkJoinTask task) {
ForkJoinTask[] a; ForkJoinPool p;
int b = base, s = top, n;
if ((a = array) != null) { // ignore if queue removed
int m = a.length - 1; // fenced write for task visibility
//更新双端队列array的top处任务为task,直接原子更新,非CAS操作
//因为这个方法只会被array所属的线程调用,所以这里是线程安全的
U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task);
//top指针向前移一位
U.putOrderedInt(this, QTOP, s + 1);
if ((n = s - b) <= 1) {
//说明未push前队列中最多有一个任务
if ((p = pool) != null)
//此时唤醒其他等待的线程,表示整体pool中有事情可以做了。。
p.signalWork(p.workQueues, this);
}
else if (n >= m)
//队列扩容
growArray();
}
}
小伙伴思考下,这里Base和Top指针会存在任务冲突吗?其实不会哦,因为两个指针都在往前冲,Base永远追赶不上Top。这个方法额外需要做的事情 是 唤醒空闲线程 表示有任务进来了, 判断队列是否需要扩容就好。
pop操作
考虑pop操作,虽然任务队列所属的线程才能操作,但是当任务队列只有一个任务时,存在steal操作和pop操作的任务竞争。原理就和steal操作一致了,当CAS修改top-1处任务为空 成功时,再更新top值为top-1。
final ForkJoinTask pop() {
ForkJoinTask[] a; ForkJoinTask t; int m;
if ((a = array) != null && (m = a.length - 1) >= 0) {
for (int s; (s = top - 1) - base >= 0;) {
long j = ((m & s) << ASHIFT) + ABASE;
if ((t = (ForkJoinTask)U.getObject(a, j)) == null)
break;
if (U.compareAndSwapObject(a, j, t, null)) {
U.putOrderedInt(this, QTOP, s);
return t;
}
}
}
return null;
}
注意这个pop操作并没有steal操作那么多次预读避免并发竞争,小姐姐yy是因为pop操作只有在任务队列中只有一个任务时,才会存在和Steal操作的竞争问题。而Steal操作也时时可能存在多个其他线程的竞争问题的。
通过上面三个任务调度方法的分析,你有没有感受到一丝丝FJ的调度轻量级呢?
总结一下:Fork-Join框架通过将共享的任务队列拆分成线程独有的双端任务队列,多线程steal操作通过多次读和CAS保证同步,steal操作和pop操作 通过CAS 保证同步,push操作线程安全,不需要同步。
问题是什么时候线程消费自己的任务队列中的任务,什么时候会去偷别的线程的任务,一个任务在Fork-Join框架中的生命周期是怎样的,又是怎么流转的?
Fork-Join框架使用
要能回答上面的问题,我们先看一下如何使用Fork-Join框架。上面这三个方法并不是我们能直接调用的,这三个方法是Fork-Join自己在合适的时机自己调用的。像最开始所说,使用者只需要:
定义好拆分子任务和合并子任务的规则的大任务,并且把任务丢给ForkJoinPool就好
求 1-1亿之间的数字和
Step1.定义一个求和的任务类
- 继承
RecursiveTask类,重写其compute()方法:
RecursiveTask如其名,是一个归并任务。compute()方法是具体如何拆分,如何归并的实现。fork()方法就是在确定拆分子任务规则时调用的,该方法会把子任务push到当前线程自己的任务队列中;join()方法就是在确定合并子任务的规则时调用的,该方法会等待直到返回子任务的结果。
public class SumTask extends RecursiveTask {
private long[] numbers;
private int from;
private int to;
public SumTask(long[] numbers, int from, int to) {
this.numbers = numbers;
this.from = from;
this.to = to;
}
@Override
protected Long compute() {
//拆分子任务的规则:
// 1.当需要计算的数字小于6时,直接计算结果
if (to - from < 6) {
long total = 0;
for (int i = from; i <= to; i++) {
total += numbers[i];
}
return total;
// 2.否则,把任务一分为二,递归计算
} else {
int middle = (from + to) / 2;
//构造子任务
SumTask taskLeft = new SumTask(numbers, from, middle);
SumTask taskRight = new SumTask(numbers, middle+1, to);
//将子任务添加到任务队列,这一步我们还是要做了
taskLeft.fork();
taskRight.fork();
//合并所有子任务的规则:所有子任务的结果相加
return taskLeft.join() + taskRight.join();
}
}
}
在等待子任务结果的时候,线程被阻塞了吗?
(当然没有,这段时间其实就会偷任务来做。后面我们再分析:)
Step2.构造一个Fork-Join线程池,把上面的求和大任务SumTask丢进去
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool();
SumTask sumTask = new SumTask(numbers, 0, numbers.length-1)
long result = pool.invoke(sumTask);
System.out.println(result);
}
从这里,我们可以看到任务丢进线程池是调用的pool.invoke(sumTask)
( 熟悉JDK线程池实现的小伙伴可以结合上面ForkJoin框架的原理想想任务该如何流转。小姐姐开始了:)
一个归并任务的流转
Step1.任务提交到任务队列
包括invoke等所有任务提交方法最终都会调用ForkJoinPool.externalPush方法。
这里面需要考虑将任务提交到哪个队列?
如果提交到ForkJoinWorkerThread自己的双端任务队列中:
不管提交到头还是尾,都会和我们上面分析的三个操作发生任务冲突。
而且如何选择负载最小的线程来提交也会增加问题复杂性。
ForkJoinPool中双端任务队列是用数组(volatile WorkQueue[] workQueues)实现的,其中奇数下标存放的是可激活的任务队列,偶数下标存放的是不可激活的任务队列。激活指的是这个队列是否是某个ForkJoin线程的任务队列。

ForkJoinPool.externalPush只能将任务提交到不可激活任务队列,该方法的主要逻辑为:
当提交的任务是pool的第一个任务时,会初始化workQueues,ForkJoinWorkerThread等资源,通过hash算法选择一个偶数下标的workQueue,在TOP处放入任务。同时唤醒ForkJoinWorkerThread开始拉取任务工作。
当提交的任务不是第一个任务,此时workQueues等资源已初始化好。同样需要选择一个偶数下标的workQueue存放任务,如果选中的workQueue只有这一个任务,说明之前线程资源大概率是闲置的状态,会尝试 唤醒(signalWork方法) 一个空闲的ForkJoinWorkerThread开始拉取任务工作。
Step2.ForkJoinWorkerThread的运行
我们先看一下任务的生产和消费模式:
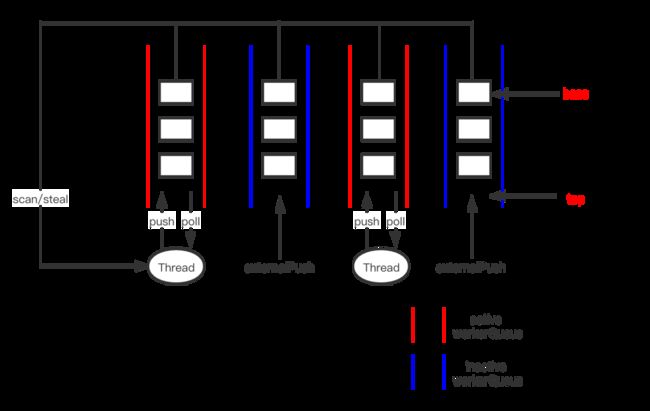
可激活的workQueue自己所属ForkJoinWorkerThread的任务模式是LIFO(Last In First Out)
不可激活的workQueue的任务模式是FIFO(First In First Out)
ForkJoinWorkerThread刚开始运行时会调用ForkJoinWorkerThread.scan方法随机选取一个队列从Base处捞取任务.捞取到任务会调用WorkQueue.runTask方法执行任务,最终对于RecursiveTask任务执行的是RecursiveTask.exec方法。
protected final boolean exec() {
//我们一开始定义SumTask的实现方法:compute
result = compute();
return true;
}
里面调用的就是我们一开始定义SumTask的实现方法:compute方法。
fork所做的事情就是将我们切分的子任务添加到当前ForkJoinWorkerThread自己的workQueue中
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
join所做的事情就是等待子任务的返回结果
public final V join() {
int s;
//doJoin会返回执行结果
if ((s = doJoin() & DONE_MASK) != NORMAL)
//结果有异常,抛出异常信息
reportException(s);
//结果无异常,返回正常结果
return getRawResult();
}
讲原理的时候我们提到了当调用join获取任务结果时,ForkJoinWorkerThread会根据当前任务的情况,做出最正确的执行判断,而不是单纯的阻塞等待结果。
Step3.join时执行任务的判断
结合上面求和的例子,我们来看一下求1-10之间的数字和的求和任务的可能join过程:
case1:任务未被偷
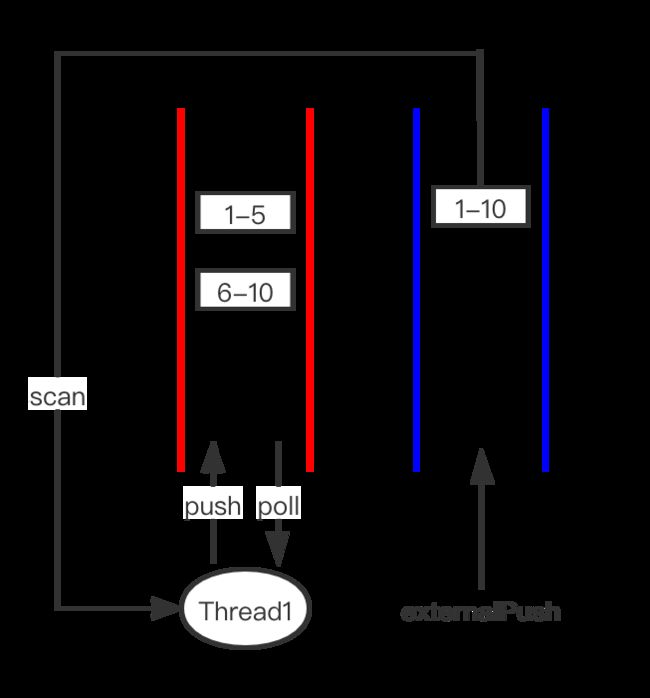
假设求和 1-10任务被Thread1执行,fork出两个子任务:1-5 和 6-10,只要Thread1能判断出来要join的任务在自己的任务队列中,那当前join哪个子任务就把它取出来执行就可以。
case2:任务被偷,此时自己的任务队列为空,可以帮助小偷执行它未完成的任务
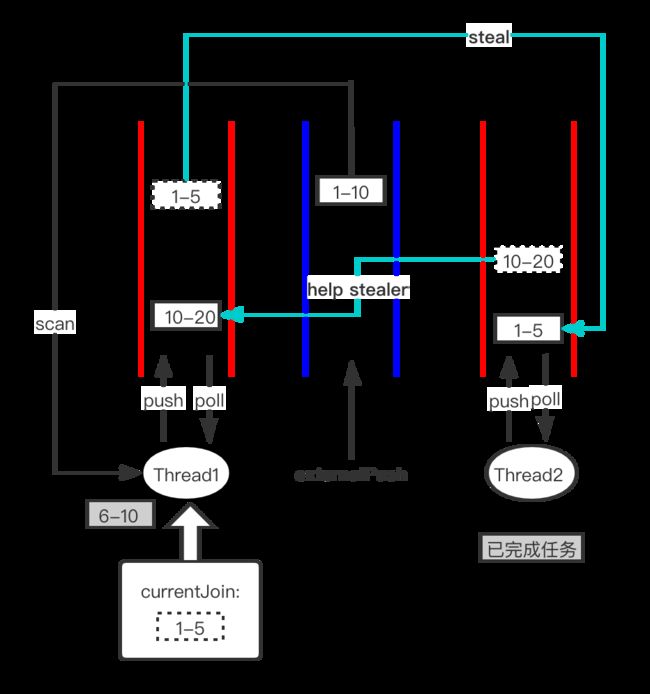
假设求和 1-10任务被Thread1执行,fork出两个子任务:1-5 和 6-10。6-10已成功执行完成,join返回了结果。但此时发现1-5被Thread2偷走了,自己的任务队列中已经没有任务可以执行了。此时Thread1可以找到小偷Thread2,并偷取Thread2的10-20任务来帮助它执行。
case3:任务被偷,此时自己的任务队列不为空
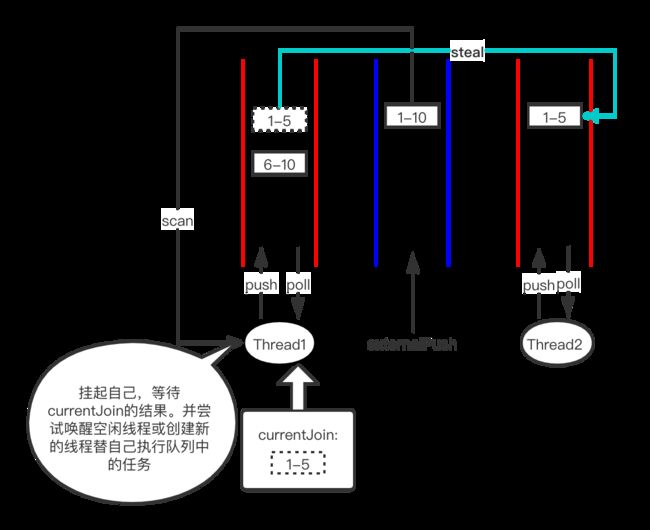
假设求和 1-10任务被Thread1执行,fork出两个子任务:1-5 和 6-10,要join 1-5时发现已经被Thread2偷走了,而自己队列中还有6-10等待join执行。不好意思帮不了小偷了。
只好尝试挂起自己等待1-5的执行结果通知,并尝试唤醒空闲线程或者创建新的线程替代自己执行任务队列中的6-10任务。
上述三种情况代码均在ForkJoinPool.awaitJoin方法中。整体思路是:
当任务还在自己的队列:
- 自己执行,获取结果。
当被别人偷走阻塞了:
- 自己又没任务执行,就帮助小偷执行任务。
- 自己有任务要执行,就尝试挂起自己等待小偷的反馈结果,同时找队友帮助自己执行。
这里任务模式有意思的是:
scan/steal操作都是从Base处获取任务,那么更容易获取到大的任务执行,从而使得整体线程的资源分配更加均衡。
任务队列所属的线程是LIFO的任务生产消费模式,刚好符合递归任务的执行顺序。
至此你有没有对ForkJoin框架的轻量级调度和Work−Stealing算法有一些了解呀:)
感谢您的阅读,文中有错误的地方还请指出,一起交流学习。我是Monica23334 || Monica2333 。立下每周写一篇原创文章flag的小姐姐,关注我并期待打脸吧~

参考资料:
[1].http://gee.cs.oswego.edu/dl/papers/fj.pdf
[2].https://juejin.im/entry/5a027e2bf265da43247fdef7
[3].https://www.jianshu.com/p/f777abb7b251
[4].http://blog.dyngr.com/blog/2016/09/15/java-forkjoinpool-internals/
[5].https://zhuanlan.zhihu.com/p/38204373
[6].https://zhuanlan.zhihu.com/p/68554017
[7].https://zh.wikipedia.org/wiki/%E5%B9%B6%E8%A1%8C%E8%AE%A1%E7%AE%97