Flink 数据 保存 Redis(自定义Redis Sink)
本文开头附:Flink 学习路线系列 ^ _ ^
本文主要来介绍 Flink 读取 Kafka数据,并实时下沉(Sink)数据到 Redis 的过程。
通过如下链接:Flink官方文档,我们知道数据保存到 Redis 的容错机制是 at least once。所以我们通过幂等操作,使用新数据覆盖旧数据的方式,以此来实现 exactly-once 。
1.代码部分
1.1 config.properties配置文件
bootstrap.server=192.168.204.210:9092,192.168.204.211:9092,192.168.204.212:9092
group.id=testGroup
auto.offset.reset=earliest
enable.auto.commit=false
topics=words
redis.host=192.168.204.210
redis.port=6379
redis.password=123456
redis.timeout=5000
redis.db=0
1.2 RedisUtils工具类
/**
* TODO FlinkUtils工具类(持续更新编写)
*
* @author liuzebiao
* @Date 2020-2-18 9:11
*/
public class FlinkUtils {
private static StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
/**
* 返回 Flink流式环境
* @return
*/
public static StreamExecutionEnvironment getEnv(){
return env;
}
/**
* Flink 从 Kafka 中读取数据(满足Exactly-Once)
* @param parameters
* @param clazz
* @param
* @return
* @throws IllegalAccessException
* @throws InstantiationException
*/
public static <T> DataStream<T> createKafkaStream(ParameterTool parameters, Class<? extends DeserializationSchema> clazz) throws IllegalAccessException, InstantiationException {
//设置全局参数
env.getConfig().setGlobalJobParameters(parameters);
//1.只有开启了CheckPointing,才会有重启策略
//设置Checkpoint模式(与Kafka整合,一定要设置Checkpoint模式为Exactly_Once)
env.enableCheckpointing(parameters.getLong("checkpoint.interval",5000L),CheckpointingMode.EXACTLY_ONCE);
//2.默认的重启策略是:固定延迟无限重启
//此处设置重启策略为:出现异常重启3次,隔5秒一次(你也可以在flink-conf.yaml配置文件中写死。此处配置会覆盖配置文件中的)
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(10, Time.seconds(20)));
//系统异常退出或人为 Cancel 掉,不删除checkpoint数据
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
/**2.Source:读取 Kafka 中的消息**/
//Kafka props
Properties properties = new Properties();
//指定Kafka的Broker地址
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, parameters.getRequired("bootstrap.server"));
//指定组ID
properties.put(ConsumerConfig.GROUP_ID_CONFIG, parameters.getRequired("group.id"));
//如果没有记录偏移量,第一次从最开始消费
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, parameters.get("auto.offset.reset","earliest"));
//Kafka的消费者,不自动提交偏移量
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, parameters.get("enable.auto.commit","false"));
String topics = parameters.getRequired("topics");
List<String> topicList = Arrays.asList(topics.split(","));
FlinkKafkaConsumer<T> kafkaConsumer = new FlinkKafkaConsumer(topicList, clazz.newInstance(), properties);
return env.addSource(kafkaConsumer);
}
}
1.3 Flink 整合 Kafka
Flink整合 Kafka 实现 Exactly Once,本文不再过多介绍,你可以参考:Flink 整合 Kafka (实现 Exactly-Once)
1.4 自定义 Redis Sink
Flink 通过Apache Bahir 发布了用于Flink的其他流连接器(包括ActiveMQ、Flume、Redis、Akka、Netty)。官方链接如下:Flink官方 Apache Bahir Sink链接

官方为我们提供的 Redis Sink,我们用起来感觉不是很灵便,所以此处我们来自定义 Redis Sink。
/**
* TODO 自定义 Redis Sink
*
* @author liuzebiao
* @Date 2020-2-18 10:26
*/
public class MyRedisSink extends RichSinkFunction<Tuple3<String, String, Integer>> {
private transient Jedis jedis;
@Override
public void open(Configuration config) {
ParameterTool parameters = (ParameterTool)getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
String host = parameters.getRequired("redis.host");
String password = parameters.get("redis.password", "");
Integer port = parameters.getInt("redis.port", 6379);
Integer timeout = parameters.getInt("redis.timeout", 5000);
Integer db = parameters.getInt("redis.db", 0);
jedis = new Jedis(host, port, timeout);
jedis.auth(password);
jedis.select(db);
}
@Override
public void invoke(Tuple3<String, String, Integer> value, Context context) throws Exception {
if (!jedis.isConnected()) {
jedis.connect();
}
//保存
jedis.hset(value.f0, value.f1, String.valueOf(value.f2));
}
@Override
public void close() throws Exception {
jedis.close();
}
}
1.5 代码
/**
1. TODO 实时读取 Kafka 单词,计算并保存数据到 Redis
2. 3. @author liuzebiao
3. @Date 2020-2-18 9:50
*/
public class Test {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = FlinkUtils.getEnv();
ParameterTool parameters = ParameterTool.fromPropertiesFile("config.properties配置文件所在路径");
DataStream<String> kafkaStream = FlinkUtils.createKafkaStream(parameters, SimpleStringSchema.class);
SingleOutputStreamOperator<Tuple3<String, String, Integer>> tuple3Operator = kafkaStream.flatMap((String lines, Collector<Tuple3<String, String, Integer>> out) -> {
Arrays.stream(lines.split(" ")).forEach(word -> out.collect(Tuple3.of("WordCount",word, 1)));
}).returns(Types.TUPLE(Types.STRING, Types.STRING,Types.INT));
SingleOutputStreamOperator<Tuple3<String, String, Integer>> sum = tuple3Operator.keyBy(1).sum(2);
sum.addSink(new MyRedisSink());
env.execute("Test");
}
}
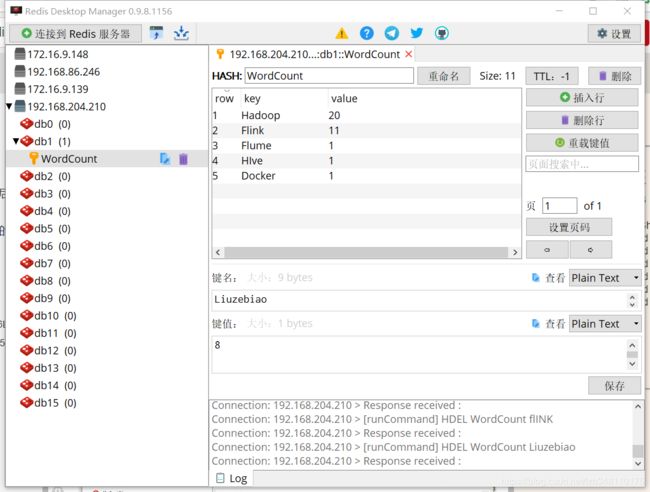
2.测试结果
- 从 Kafka 中读取数据,并能够将计算结果实时保存到 Redis 中。
- 此时如果 Redis 服务有异常,Kafka 持续写入消息。当Redis 服务重启之后,能够将异常期间数据重新计算,保证数据的不丢失。
- 将数据保存到 Redis,此处使用的就是后者覆盖前者的方式,来最大成都的保证 Exactly-Once 。
保存到 Redis 数据如下:
博主写作不易,来个关注呗
求关注、求点赞,加个关注不迷路 ヾ(◍°∇°◍)ノ゙
博主不能保证写的所有知识点都正确,但是能保证纯手敲,错误也请指出,望轻喷 Thanks♪(・ω・)ノ