【MapReduce详解及源码解析(一)】——分片输入、Mapper及Map端Shuffle过程
title: 【MapReduce详解及源码解析(一)】——分片输入、Mapper及Map端Shuffle过程
date: 2018-12-03 21:12:42
tags: Hadoop
categories: 大数据
toc: true
点击查看我的博客:Josonlee’s Blog
版权声明:本文为博主原创文章,未经博主允许不得转载(https://blog.csdn.net/lzw2016/)
文章目录
- 前瞻
- MapReduce过程概览
- 一、输入数据分片并转化为键值对
- FileInputFormat类及其子类的相关源码解析
- 二、Map过程
- 三、Shuffle过程
- Map端Shuffle过程
之前在看这一部分内容时,也挺烦的,细读一遍《Hadoop 海量数据处理·范东来著》书和老师给的若干Demo代码,自己再看看MapReduce的部分源码后,感触挺深的。把自己所领会的记录在这里吧,文章挺长,一次可能写不完(写不完下次再说吧)
前瞻
用户向Hadoop提交的最小单位是MR作业job,MR计算的最小单位是任务task。job分为多个task,task又分map任务,reduce任务
在Hadoop1.0版本,客户端向Hadoop提交作业,JobTracker会将该作业拆分为多个任务,并根据心跳信息交由空闲的TaskTracker 启动。一个TaskTracker能够启动的任务数量是由TaskTracker 配置的任务槽(slot) 决定。槽是Hadoop的计算资源的表示模型,Hadoop将各个节点上的多维度资源(CPU、内存等)抽象成一维度的槽,这样就将多维度资源分配问题转换成维度的槽 分配的问题。在实际情况中, Map任务和Reduce任务需要的计算资源不尽相同,Hadoop又将槽分成Map槽和Reduce槽,并且Map任务只能使用Map槽,Reduce任务只能使用Reduce槽。
这样做性能会很低,所以在Hadoop2.0版本,资源管理调度框架改为了Yarn,但MR任然作为计算框架存在
MapReduce过程概览
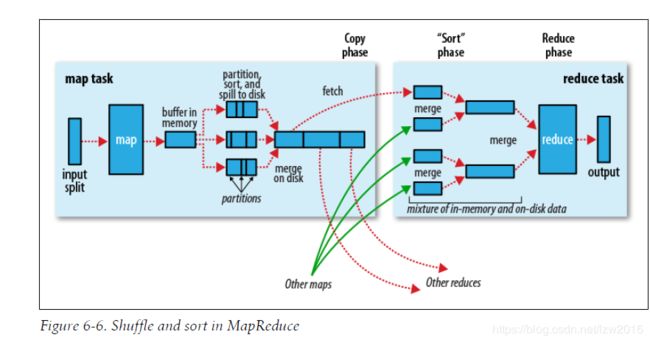
这张图出处不知,我也就随便用了
一、输入数据分片并转化为键值对
在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split), 每个输入分片(InputSplit)针对一个map任务, 输入分片(input split)存储的并非数据本身, 而是逻辑上一个分片长度和一个记录数据的位置的数组。 默认分片等同于块大小,分片大小对MR性能影响很大,尽量和block大小相近可以提供map任务计算的数据本地性
可以设置一个map任务的参考个数值,见参数mapred.map.tasks,只是参考具体还是取决于分片数
下面源码中会看到分片大小具体是如何设定的
MapReduce Input Split(输入分/切片)详解,这篇文章对分片这一块总结的挺不错
看下源码中InputSplit的实现,见InputFormat数据格式转换接口

如图,左侧是实现该接口的几个格式化数据的类,右侧是该接口的两个抽象方法:getSplits是将数据切分成若干个分片,createRecordReader是将输入的分片解析成键值对(key-value),键是偏移量,值是该行的内容
FileInputFormat类及其子类的相关源码解析
继续看下去,看下用的比较多的FileInputFormat类的源码
- 分片大小计算
// 计算分片大小
protected long computeSplitSize(long blockSize, long minSize,
long maxSize) {
return Math.max(minSize, Math.min(maxSize, blockSize));
}
代码中的minSize、maxSize定义
minSize=max{minSplitSize,mapred.min.split.size}
maxSize=mapred.max.split.size
blockSize是块大小,所以就是用设置中这三个参数而定的
- 数据分片
// 数据分片
public List<InputSplit> getSplits(JobContext job) throws IOException {
Stopwatch sw = new Stopwatch().start();
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));
long maxSize = getMaxSplitSize(job);
// 此处省略
if (isSplitable(job, path)) { //可分片
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length;
//while循环和if判断就是将输入的数据长不断分片过程
//SPLIT_SLOP=1.1,剩余文件小于1.1*blockSize的话变开始停止切分
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, splitSize,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
// 获取逻辑上每个切片的位置,长度,包含该分片的主机列表和在内存中包含该分片的主机列表
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining);
splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkIndex].getHosts(),
blkLocations[blkIndex].getCachedHosts()));
}
}
// 此处省略
return splits;
}
2019.09.05 更新
今天和别人讨论Map端大量小文件时谈到了分片切分,一个文件129M,按默认128M分片大小能划分成几个分片?我说是两个,大佬说是一个,多出来的1M大小会合并到上一个分片中。我说不可能,毕竟早先看过源码,今天又翻了一下,果然是太年轻了,当初看的没那么仔细。
切分时有个SPLIT_SLOP参数,默认是1.1。所以剩余数据小于12.8M时会合并到上一个分片上算子一个分片的
大佬就是大佬啊~
- 解析key-value方法createRecordReader()
FileInputFormat也是个抽象类,继承自该类的也不少,主要是根据不同文件类型定义不同的解析key-value的方法
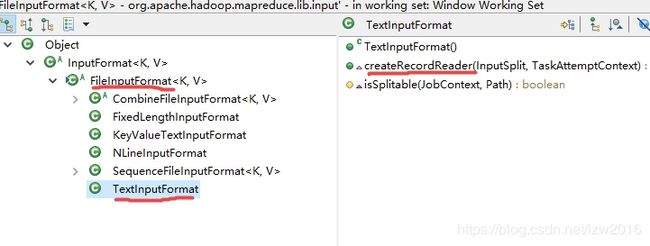
如图,最常用的也是默认的输入格式转化类TextInputFormat,针对文本文件
- TextInputFormat 读取输入InputSplit的每行内容作为一次输入,并以换行符或回车符表示本行结束
- KeyValueTextInputFormat读取输入InputSplit的每行内容作为一次输入,并以换行符或回车符表示本行结束,每行内容按分隔符 (默认是制表符 \t) 分为键和值部分。如果不存在分隔符,则键将是整行内容,并且值为空
程序中可以自定义分隔符,比如定义为逗号conf.set(“mapreduce.input.keyvaluelinerecordreader.key.value.separator”, “,”)
- NLineInputFormat可以让Mapper收到固定行数的输入,每个map进程处理的 InputSplit不再按block块去划分,而是按指定的N值,即每个InputSplit中只有N行记录
程序中指定N大小:比如1000行, conf.setInt(“mapreduce.input.lineinputformat.linespermap”, 1000)
这个N对MR性能有很大的影响,每N行是一个map task,快慢问题,所以要选取合适
-
SequenceFileInputFormat 是Hadoop的顺序文件格式,存储二进制的
-
FixedLengthInputFormat是一种用于读取包含固定长度记录的输入文件的输入格式,记录的内容不一定是文本,可以是任意的二进制数据
程序中必须设置定长,如20,conf.setInt(FixedLengthInputFormat.FIXED_RECORD_LENGTH, 20);
- CombineFileInputFormat 是一个抽象的 InputFormat,它主要是针对小文件而设计的,可以把多个文件打包到一个分片中以便每个Mapper处理更多的操作(没怎么看过这个,也不知道这怎么用)
以上大概就是Map任务输入数据分片的部分,还有就是编程时,如果使用不同的格式化类要在程序中指定输入数据格式化类
job.setInputFormatClass(Class<? extends InputFormat> cls)
// 如,job.setInputFormatClass(NLineInputFormat.class)
二、Map过程
DataNode中的数据经上文所谈到的逻辑上分片、转化后分配给每一个Map Task。有一点需要知道,Map、Reduce的输入输出都是k-v键值对。四队k-v,
从编程角度,我们做的第一个工作就是编写map函数逻辑,这个map函数就是重写类Mapper的map函数,源码如下
/**
* Called once for each key/value pair in the input split. Most applications
* should override this, but the default is the identity function.
*/
@SuppressWarnings("unchecked")
protected void map(KEYIN key, VALUEIN value,
Context context) throws IOException, InterruptedException {
context.write((KEYOUT) key, (VALUEOUT) value);
}
你所要做的就是,把输入value转出你需要的Map输出
Mapper中还有setUp初始化,cleanup结束map task方法,以及run方法
public void run(Context context) throws IOException, InterruptedException {// 参数是Context,分片
setup(context); // 初始化一个map任务
try {
while (context.nextKeyValue()) { // 还有键值对,继续对每一对进行map方法调用
map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
cleanup(context); //结束map任务
}
}
由代码可看出,通常我们看到的一个文件中每一行都会进行一次map,这就是由run方法完成的。map输出结果不论Shuffle的话,通常是进行Combine。比如说词频统计,“hello hello you”,经过组合输出
三、Shuffle过程
Shuffle过程在Map和Reduce端都会进行,Shuffle分为分区(Partition)、排序(Sort)、分组(Group)、组合(Combine)
Map端Shuffle过程
Map任务在完成后输出的
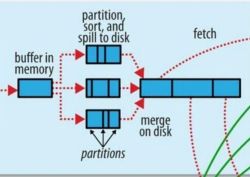
如图,缓存中的输出结果,先经过分区、排序、分组整合成不同(3个)分区,然后溢写磁盘,再次排序、分组整合成不同(3个)分区。图中并没有展示出combine的部分
- Partition 分区
分区是一种需求吧,由key值决定Mapper的输出会被哪一个Reducer处理。比如说按年份,按月份分区
@InterfaceAudience.Public
@InterfaceStability.Stable
public abstract class Partitioner<KEY, VALUE> { //抽象类Partitioner
//就一个函数,numPartitons是要分区的数量
public abstract int getPartition(KEY key, VALUE value, int numPartitions); //返回值是key所对应的分区number
// 比如说按月分区,<1,xxx>,1月对应分区number为1
}
- Sort 排序
Shuffle过程会有三次排序,其中Map阶段有两次,有上文图片也可知
Shuffle默认是对key升序排序的,你也可以指定你的排序规则。如何指定,要实现WritableComparable接口,这有个例子
* <p>Example:</p>
* <p><blockquote><pre>
* public class MyWritableComparable implements WritableComparable<MyWritableComparable> {
* // Some data
* private int counter;
* private long timestamp;
*
* public void write(DataOutput out) throws IOException { //有些复杂排序,比如二次排序,需要重写该方法
* out.writeInt(counter);
* out.writeLong(timestamp);
* }
*
* public void readFields(DataInput in) throws IOException { //有些复杂排序,需要重写该方法
* counter = in.readInt();
* timestamp = in.readLong();
* }
*
* public int compareTo(MyWritableComparable o) { //这个是你要修改的
* int thisValue = this.value;
* int thatValue = o.value;
* return (thisValue < thatValue ? -1 : (thisValue==thatValue ? 0 : 1));
* }
*
* public int hashCode() {
* final int prime = 31;
* int result = 1;
* result = prime * result + counter;
* result = prime * result + (int) (timestamp ^ (timestamp >>> 32));
* return result
* }
* }
只能说具体问题,具体分析吧
这里标记下
a.compareTo(b)按照a升序排序
b.compareTo(a) 按照a降序排序
返回负数,就是降序
- Group 分组
分组是将具有相同key的values放置在一起,这个不是分区。分区是写入不同文件,分组是聚合key相同的,我的理解
- Combine 组合
Combine很简单,就一句话,Combine做的工作和Reduce是一样的。所以他也继承Reducer类,完成reduce方法,要求输出k-v类型等于Reducer输入k-v类型
程序中通过类似job.setCombinerClass(IntSumReducer.class);来指定指定Combiner类
经常看到说Combine针对求解最小、大值,不适合求平均数。我感觉也可以,实现逻辑是靠自己,你只要保证combine输出类型和Reducer输入、出一致就可以了,然后具体如何定义结构也不难
如果已经指定Combiner且溢出写次数至少为3时,Combiner 就会在输出文件写到磁盘之前运行。如前文所述,Combiner 可以多次运行,并不影响输出结果。运行Combiner的意义在”于使map输出的中间结果更紧凑,使得写到本地磁盘和传给Reducer的数据更少。
- 写磁盘补充
map输出存储的格式是IFile,IFile格式支持行压缩。写磁盘过程,压缩map的输出能提高I/O性能,占空间小,传给reduce的数据量也减小。(默认不压缩的)
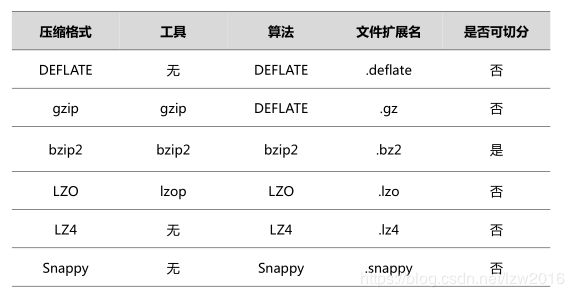
支持压缩格式有:
- bzip2 压缩效果最好,压缩/解压速度最慢
- LZO 压缩效果不如bzip2和gzip,压缩/解压速度最快
- gzip 压缩效果不如 bzip2,压缩/解压速度较快