各位小伙伴们大家好,在接下来的文章中我们将讲述一下什么是语言模型,以及语言模型上的应用,在完善之后我们将会简单的讲解一下语言模型的性能评估,这三点将是这一篇文章的主要内容.
在阅读这篇文章之前,我希望大家可以已经有以下的知识积累作为基础,像是概率论里的基本概念,比如最大似然估计,贝叶斯分类,贝叶斯决策理论等等,甚至是一些包括信息论的简单基本概念,比如信息熵等,并且如果能对简单的形式语言可以理解就更加完美了,话不多说,马上开始这一篇文章的主要内容.
1:为什么我们需要新的方法?
在前几篇我的关于形式语言的文章中,我们大致可以理解到形式语言有以下的几个缺陷:
1:比如像汉语,英语这样的大型的自然语言系统,形式语言就比较难以构造精确的文法.
2:形式语言的逻辑规则太过于复杂,实际上并不符合我们的学习语言的习惯.
3:有一些句子.比如你这句子的文法是正确的,但是实际上在我们的生活中是不可能发生的,形式语言是无法识别这些句子的.
为了解决这些问题,科学家们在研究好久了后找到了新的方向,科学家们在基于大量的研究之后,发现基于大量的语料,并且采用统计学的手段建立模型,发现可以很好地去提升语言模型的效率.
这时候我们不妨想一下为什么统计方法的出现为自然语言处理提供了方向?
首先,在应用统计方法之前,大规模的语料库的出现为自然语言统计处理方法的实现提供了可能(在我看来,这可能也是一个制约).并且语料库里的语言,相对于形式语言可以更加的符合人类的习惯,从而更加的发现语言使用的一般规律,这样一来,我们就可以使用机器学习模型来自动的获取语言的知识,这样的手段就可以更加的丰富,并且基于机器的能力,我们甚至可以发现推测未知语言的能力.[说句题外话,在现在各行各业的机器学习广泛应用的现在,很多的行业对于你本身的业务知识的要求并没有那么高,只有在数据不够充足的情况下,我们才更加的需要借助业务知识,但是只要有合适的,足够的海量数据,我们其实就可以跑起业务,直接获得合适的数学模型,从而获得智慧和知识,从而获取商业价值]
任何的一个信息的处理系统其实都是需要大量的数据和知识库的支持,在机器学习这样的以数据驱动的学科中更是如此,语料库和语言知识作为基本的资源尽管在不同的自然语言处理方向上起到了不同的作用,但是实际上却是现自然语言的基础甚至是瓶颈.
2:语言模型
语言模型在自然语言处理中占有着重要的地位,特别是在基于统计模型的语音识别,机器翻译,分词和文法分析中都是有这广泛的应用,因为我最近在学习n元语法模型,这个模型其实还是比较简单的,并且比较直观,但是如果数据缺乏的话就必须要使用平滑算法,那什么是n元语法,那什么样的平滑算法更加的好用?
1:n元语法:
一个语言模型的构造一般是字符串s的频率分布P(s),这里的P(s)是指字符串s作为一个句子出现的频率,比如你的口头禅是OK,你可能100句话中会说25句OK,那么我们就可以认为P(ok)的概率是1/4,而在”how are you”中出现的概率就为0,因为这样的句子里很少有人会掺杂上OK,在这里我们应该注意,语言模型和形式语言不同,语言模型与句子是否合乎语法是没有什么关系的,即便是一个句子完全合乎语法逻辑,但是我们可能会觉得很别扭,那么这个句子出现的概率就是接近为0.
接下来给出语言模型的定义:
对于一个由L个基元(字,词,短语)组成的句子,S=W1,W2,.....Wn,他的概率计算公式可以看作为:
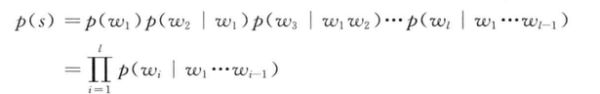
在这个句子中,产生第i个词的概率是由已经产生的前边的i-1个词来决定的,一般的我们将前边的i-1个词称为第i个词的历史.在这样的计算方法很容易就暴露出问题,如果前边的词语历史的长度不断地增加,不同的历史数目随着指数级增长,假设现在的长度是i-1,那么这样的词汇集合大小就会变成L^i-1个历史,但是在这样的情况下我们就要考虑在所有的L^i-1的情况下产生第i个词的概率.举个例子:
假设L=5000,I=3,那么这样的自由参数的数量得是L^i,也就是1250亿个,我们一看这个数据就懵逼了,怎么可能从训练数据中正确的估计出这些参数.当然我们也不可能采用这样的笨方法,科学家们为了解决这个问题,相处了方法,可以将历史(w1,w2,....wi-1)按照某一个法则映射到等价类E(w1,w2,....wi-1)中,现在假设:
这样一来,这个自由参数的数量也会大大减少,通常用的一个方法是将两个历史映射到同一个等价类,当且仅当两个历史最近的n-1的词相同时,如果E1=E2,呢么就说里边的历史是相同的.
满足上述的语言模型就是成为n元语法,但是我们在使用时n不应该选取的过大,否则等价类太多,自由参数依旧存在,这样的话其实和没有改进没有啥区别,一般情况下我发现n=3是非常合适的,当n=1时,wi是独立于历史的,当n=2时,这个wi只和wi-1有关系,这样的话就被称为一阶马尔科夫链,当n=3时,其实跟wi前边的;两个词有关,这也就是称为二阶马尔科夫链.
就按照三元文法为例:
在之前的介绍中,我们可以认为这是一个词的概率实际上只是跟前边的词有关,那么就可以有以下的方程:
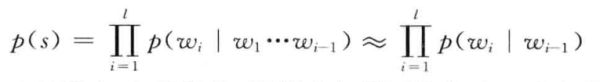
为了使p(wi|wi-1)对于i=1有意义,我们需要加一个句首标记,为了使概率之和为1,这就需要加一个EOS,这样我们的计算就是:
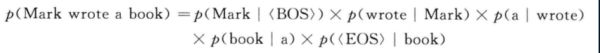
为了估计P(WI|WI-1)的条件概率,我们计算出wi-1,wi的词汇出此案的频率然后进行归一化,公式如下:
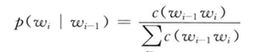
这样用于构建语言模型的文本成为训练文本,这样的n元语法模型,一般用几百万个词来训练,上边那个式子就可以称为MLE,极大似然估计.
对于n>2的n元语法模型,条件概率中药考虑前面的n-1个词的概率,为了使n>2成立,我们取:
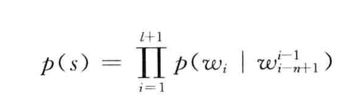
请看下面的例子,假设训练语料S由下面的三个句子组成:
1:BROWN READ HOLY BIBLE
2:MARK READ A TEXT BOOK
3:HE READ A BOOK BY DAVID
然后用最大似然估计方法来计算概率p(BROWN READ A BOOK)
结果如下:

因此结果如下:

这个句子出现的概率为0.06,这也就是n元文法的一个简单应用.
下一篇文章我们将讲述下模型的选择以及模型的性能评估.