MLAPP————第十四章 核方法
第十四章 核方法
14.1 简介
到目前为止,我们书上提到的各种方法,包括分类,聚类或者是其它的一些处理手段,我们的特征都是固定大小的一个向量,一般具有如下的形式,![]() 。然而,对于某些类型的对象,如何最好地将其表示为固定大小的特征向量尚不清楚。例如,我们如何表示长度可变的文本文档或蛋白质序列?或者分子结构,具有复杂的三维几何?或者是进化树,它的大小和形状都是可变的。
。然而,对于某些类型的对象,如何最好地将其表示为固定大小的特征向量尚不清楚。例如,我们如何表示长度可变的文本文档或蛋白质序列?或者分子结构,具有复杂的三维几何?或者是进化树,它的大小和形状都是可变的。
解决这类问题的一种方法是为数据定义生成模型,并使用推断出的潜在表示和/或模型的参数作为特征,然后将这些特征插入到标准方法中。比如后面的深度学习,其实从某种程度上就是进行特征的学习。
另一种方法是假设我们有某种方法来测量对象之间的相似性,而不需要将它们预处理成特征向量格式(目前还不太理解)。例如,在比较字符串时,我们可以计算它们之间的edit距离。令![]() 是测量目标
是测量目标![]() 之间的相似性,其中
之间的相似性,其中![]() 是某个抽象的空间。我们就叫
是某个抽象的空间。我们就叫![]() 核函数。
核函数。
在本章中,我们将讨论几种核函数。然后我们描述了一些算法,这些算法可以完全用核函数计算来编写。当我们无法访问(或选择不查看)正在处理的对象x的内部时,可以使用这些方法。
其实读到这里只是大概知道核函数有什么用,不过具体的还没明白是什么个意思。核函数能够从比较原始的数据中,获得一些结构信息,得到一些潜在的表示作为特征
14.2 核函数
我们将核函数定义为两个参数的实值函数,即![]() ,对任何的
,对任何的![]() 。一般来说这个函数是对称以及非负的,即
。一般来说这个函数是对称以及非负的,即![]() 和
和![]() 。所以它可以用来看
。所以它可以用来看![]() 的相似性,但是这个要求也不是必须的。下面我们将给几个具体的例子:
的相似性,但是这个要求也不是必须的。下面我们将给几个具体的例子:
14.2.1 RBF 核函数
平方指数核或者高斯核的定义如下:
![]()
如果![]() 是对角阵,那么可以进一步被简化为:
是对角阵,那么可以进一步被简化为:

那么这里![]() 就是定义第j个维度的特征的重要性的一个尺度。如果
就是定义第j个维度的特征的重要性的一个尺度。如果![]() ,那么相应的维度就可以被忽略,因此这个就被称作ARD核。如果
,那么相应的维度就可以被忽略,因此这个就被称作ARD核。如果![]() 是各向同性的,那么我们就会得到各向同性的核,即:
是各向同性的,那么我们就会得到各向同性的核,即:
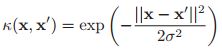
这里![]() 称之为带宽。上面的式子是径向基函数(radial basis function, RBF)的一个例子,因为它只是
称之为带宽。上面的式子是径向基函数(radial basis function, RBF)的一个例子,因为它只是![]() 的一个函数。
的一个函数。
14.2.2 比较文档的内核
当我们进行文档的分类或者是检索时,那么我们常常要去比较两个文档![]() 的相似性。如果我们使用词袋模型来表示,即
的相似性。如果我们使用词袋模型来表示,即![]() 表示第j个单词在文档i里面出现的次数。那么基于此,我们可以使用cosine 相似性,即:
表示第j个单词在文档i里面出现的次数。那么基于此,我们可以使用cosine 相似性,即:
![]()
这个其实就是计算向量![]() 之间夹角的cosine值,由于在这里是进行计数,所以说每一个数都是非负的,所以cosine相似性的结果都是介于[0,1]之间的。
之间夹角的cosine值,由于在这里是进行计数,所以说每一个数都是非负的,所以cosine相似性的结果都是介于[0,1]之间的。
但是这样的简单的方法呢并不能工作的很好,主要有两个原因:第一就是由于文章中会有很多流形的单词,比如“the”,“and”等,这些单词会使得![]() 计算出来非常相似,但是实际上并不是这样的。第二就是有很多单词只要出现了一次,可能它就会反复的出现,所以其实这个东西是有点不靠谱的。
计算出来非常相似,但是实际上并不是这样的。第二就是有很多单词只要出现了一次,可能它就会反复的出现,所以其实这个东西是有点不靠谱的。
幸运的是,我们可以使用一些简单的预处理来显著提高性能。其思想是用一种称为TF-IDF表示的新特征向量替换单词计数向量,TF-IDF表示术语频率-逆文档频率(term frequency - inverse document frequency)。
首先,术语频率被定义为计数的对数转换:
![]()
这减少了在一个文档中多次出现的单词的影响。其次,逆文档频率定义为:
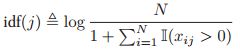
其中N是文档的总的数目,分母的话就表示包含术语j的文档有多少个。最终我们定义:
![]()
定义tf和idf术语还有其他几种方法,参见(Manning et al. 2008)了解详细信息。
然后我们把这个应用到cosine 相似性的测量里面去。这样,我们新的核函数就会具有如下形式:
![]()
其中![]() ,这为信息检索提供了良好的结果(Manning et al. 2008)。(Elkan 2005)给出了tf-idf核的概率解释。
,这为信息检索提供了良好的结果(Manning et al. 2008)。(Elkan 2005)给出了tf-idf核的概率解释。
14.2.3 Mercer(正定)核函数
我们有一些研究的方法需要我们的核函数满足如下的特性,即:
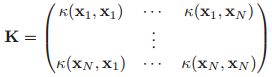
我们称这个矩阵叫做Gram matrix,这个矩阵对于任何的输入![]() ,都要是正定的。我们称这样的核函数就是Mercer核函数或者是正定核函数。有文章证明了,其实高斯核函数以及cosine 相似性核函数都是Mercer核函数。
,都要是正定的。我们称这样的核函数就是Mercer核函数或者是正定核函数。有文章证明了,其实高斯核函数以及cosine 相似性核函数都是Mercer核函数。
为什么说Mercer核函数比较重要呢,因为我们有一个叫做Mercer定理的东西。如果Gram matrix是正定的,那么我们就可以对其进行特征分解,即:![]() ,那么对于
,那么对于![]() 中的任何一个元素,我们都有:
中的任何一个元素,我们都有:![]() ,如果我们定义:
,如果我们定义:![]() ,那么可以简化为:
,那么可以简化为:![]() 。因此,我们看到核矩阵中的项可以通过执行特征向量的内积来计算,这些特征向量是由
。因此,我们看到核矩阵中的项可以通过执行特征向量的内积来计算,这些特征向量是由![]() 隐式定义的。总的来说就是,如果核函数是Mercer,那么就会存在一个函数
隐式定义的。总的来说就是,如果核函数是Mercer,那么就会存在一个函数![]() ,使得
,使得![]() ,其中
,其中![]() 取决于
取决于![]() 的特征函数。
的特征函数。
我们考虑一个多项式的核函数,![]() ,其中
,其中![]() 。在这个情况下,对应的特征向量
。在这个情况下,对应的特征向量![]() 将会包含一直到M阶的任何项。举个例子,如果
将会包含一直到M阶的任何项。举个例子,如果![]() ,以及
,以及![]() ,我们有:
,我们有:
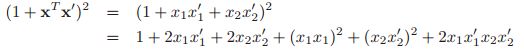
这个可以被改写为![]() 这样的形式,其中:
这样的形式,其中:
![]()
所以使用这个核就相当于在一个6维的特征空间中工作。在高斯核的情况下,特征映射存在于无限维空间中。在这种情况下,明确表示特征向量显然是不可行的。
关于不是Mercer 核函数的一个例子就是sigmoid核函数,定义如下:
![]()
(注意这里虽然叫做sigmoid核函数,但是实际上用的tanh函数),这个核函数的出现是由于多层感知器激发的(在16.5中有),但是其实并没有什么直接的理由。(关于真实的神经网络核函数,在15.4.5中会有一个正定的)。
一般来说,直接建立一个Mercer核函数是困难的,需要函数分析的技术。但是,可以通过使用一组标准规则从简单的Mercer核函数构建新的Mercer核函数。例如,如果![]() 都是Mercer核函数,那么
都是Mercer核函数,那么![]() 也是Mercer核函数。
也是Mercer核函数。
14.2.4 线性核函数
从核函数中推导出特征向量一般来说是比较困难的,可能仅仅在核是Mercer的情况下有用,但是呢从特征向量去得到核函数却是非常简单的,因为我们只需要计算:![]() 。
。
如果![]() ,我们可以得到线性的核函数,定义如下:
,我们可以得到线性的核函数,定义如下:![]() 。
。
这个一般适用于原始的数据已经具有很高的维度了,这样的话很有可能原始数据之间相互的信息就是独立的,在这种情况下,决策边界很可能是原始特征的线性组合,因此不需要在其他特征空间中工作。
当然不是说所有的特征维度很高的数据都适用,因为有可能维度很高,但是信息却不独立,比如图像,这个时候往往我们就需要非线性的核函数。
14.2.5 Matern 核函数
Matern 核函数经常用于高斯过程回归当中(见15.2节中),具有如下的形式,即:
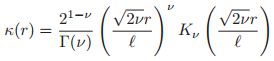
其中![]() ,
,![]() ,
,![]() 是修正的贝塞尔函数。当
是修正的贝塞尔函数。当![]() ,这个方法接近于SE核函数(高斯核函数)。当
,这个方法接近于SE核函数(高斯核函数)。当![]() ,核函数简化为:
,核函数简化为:
![]()
如果D = 1,我们用这个核函数来定义一个高斯过程(见第15章),那么我们会得到奥恩斯坦-乌伦贝克过程,它描述了一个粒子经历布朗运动的速度。
14.2.6 字符串核函数
如果我们的输入是结构化的对象时,那么我们的核函数的威力就能够真正的展现出来了。下面举个例子,我们现在描述一种使用字符串核函数比较两个可变长度字符串的方法。
考虑两个字符串![]() 和
和![]() ,它们的长度分别是
,它们的长度分别是![]() 和
和![]() ,每个都是从一个字母表
,每个都是从一个字母表![]() 中定义的。例如,考虑两个氨基酸序列,是从一个有20个字母的字母表中定义的,即:
中定义的。例如,考虑两个氨基酸序列,是从一个有20个字母的字母表中定义的,即:![]()
![]() 。
。![]() 是一个长度为110的序列,如下:
是一个长度为110的序列,如下:
![]()
![]() 是一个长度为153的序列:
是一个长度为153的序列:

这些字符串都有子字符串LQE。我们可以将两个字符串的相似性定义为它们共有的子字符串的数量。
更正式的,我们定义对于一个字符串![]() ,如果说
,如果说![]() 是
是![]() 的子字符串,那么就意味着
的子字符串,那么就意味着![]() 可以写为
可以写为![]() (当然可能有部分是空的)。现在我们令
(当然可能有部分是空的)。现在我们令![]() 表明子字符串
表明子字符串![]() 出现在字符串
出现在字符串![]() 中的次数,那么我们定义
中的次数,那么我们定义![]() 之间的核函数为:
之间的核函数为:![]() 。
。
其中![]() ,
,![]() 表明字母表
表明字母表![]() 所可能构成的所有的子串。这个核函数是一个Mercer核函数,使用suffix trees方法,可以在
所可能构成的所有的子串。这个核函数是一个Mercer核函数,使用suffix trees方法,可以在![]() 时间内计算得到(具体参考文献可以看书)。
时间内计算得到(具体参考文献可以看书)。
这个有很多很有意思的例子。如果对于![]() ,我都设定
,我都设定![]() ,那么我们就会得到一个bag-of-characters核函数。这种情况下,就会变成计算
,那么我们就会得到一个bag-of-characters核函数。这种情况下,就会变成计算![]() 中每个字母在
中每个字母在![]() 中出现的次数。如果我们要求
中出现的次数。如果我们要求![]() 的周边只能是白色的边界(
的周边只能是白色的边界(![]() 是一个独立完整的单词),那么我们就得到了一个词袋模型的核函数,
是一个独立完整的单词),那么我们就得到了一个词袋模型的核函数,![]() 就变成了数每一个单词出现的次数了。注意这是一个非常稀疏的向量,因为大部分的单词其实都不会出现。如果我们只考虑固定长度的string,比如固定为k,那么我们就得到了k-spectrum内核函数。这已经被用于将蛋白质分类为SCOP超家族。书中还给出了很多其它的情况的这样一个文献的参考,具体可以参照书。
就变成了数每一个单词出现的次数了。注意这是一个非常稀疏的向量,因为大部分的单词其实都不会出现。如果我们只考虑固定长度的string,比如固定为k,那么我们就得到了k-spectrum内核函数。这已经被用于将蛋白质分类为SCOP超家族。书中还给出了很多其它的情况的这样一个文献的参考,具体可以参照书。
14.2.7 层次匹配核函数
在计算机视觉中,我们经常通过计算图像中多个点的特征向量来创建图像的词袋表示,一般来说,我们会使用一个叫做兴趣点探测器的东西。然后将选定位置的特征向量进行量化,最终建立一堆离散的符号。
比较这两个大小可变的袋子的方法就是使用层次匹配核函数。这里的话,我们先看下面的图:
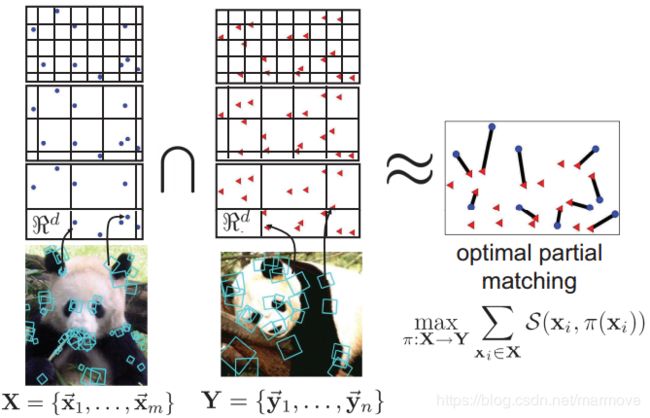
这里呢,每一幅图我们都会选一些特征明显的位置,这样其实所计算出来的特征向量是固定的,但是我们会用不同分辨率的直方图来进行刻画这个特征向量,这就是上面所说的对特征向量进行量化。然后对直方图进行相交,然后做一些操作,整体来说,这个方法很快,鲁棒性也很强,具体的细节就不详细说了。这也是一个Mercer核函数。
14.2.8 从概率生成模型中推导核函数
假设我们已经有了特征向量的概率生成模型,即![]() 。有一些方法可以根据这个区定义一些核函数,然后利用使得这个模型适用于判别的任务(虽然从概率模型上来讲,生成模型是更加广阔的,但是从判别任务上来讲,我觉得并不是这样,因为其实你即使有了生成概率模型,那么如何做好的决策也是仍需要考虑的,这里我只是觉得,很有可能我这个理解的不对)
。有一些方法可以根据这个区定义一些核函数,然后利用使得这个模型适用于判别的任务(虽然从概率模型上来讲,生成模型是更加广阔的,但是从判别任务上来讲,我觉得并不是这样,因为其实你即使有了生成概率模型,那么如何做好的决策也是仍需要考虑的,这里我只是觉得,很有可能我这个理解的不对)
14.2.8.1 概率乘积核函数
定义核函数的一个方法如下:
![]()
其中![]() ,并且
,并且![]() 经常用
经常用![]() 来近似,其中
来近似,其中![]() 是使用一个单独的数据向量进行参数的估计。这个叫做概率乘积核函数。尽管看上去很奇怪的一点就是我们用一个数据就去拟合模型,但是实际上我们只是想去了解
是使用一个单独的数据向量进行参数的估计。这个叫做概率乘积核函数。尽管看上去很奇怪的一点就是我们用一个数据就去拟合模型,但是实际上我们只是想去了解![]() 和
和![]() 之间的相似性。例如,假设
之间的相似性。例如,假设![]() ,其中
,其中![]() 是固定的。如果
是固定的。如果![]() ,并且我们使用
,并且我们使用![]() 以及
以及![]() ,我们则发现:
,我们则发现:
![]()
这个就正好对照着我们之前的RBF核函数。
结果表明,对于各种各样的生成模型,我们都可以计算公式14.23,比如 HMMs,这提供了一种在可变长度序列上定义核函数的方法。
14.2.8.2 费舍尔核函数
使用生成模型定义核函数的更有效的方法是使用费舍尔核函数,具体的定义如下:![]() 。其中
。其中![]() 是log似然函数在最大似然估计点
是log似然函数在最大似然估计点![]() 的梯度,即:
的梯度,即:![]() 。
。![]() 是费舍尔信息矩阵,本质上是汉森矩阵:
是费舍尔信息矩阵,本质上是汉森矩阵:![]() ,这里我们要注意的是
,这里我们要注意的是![]() 是基于所有的数据的估计器,是所有数据的结果,所以其实我们在计算
是基于所有的数据的估计器,是所有数据的结果,所以其实我们在计算![]() 的时候是基于所有的数据背景下的。
的时候是基于所有的数据背景下的。
隐藏在费舍尔核函数后面的比较直觉上的解释是:因为![]() 是梯度,所以说它的方向就是基于参数
是梯度,所以说它的方向就是基于参数![]() 下,使得它自己的似然最大的那个方向。那么我们说如果
下,使得它自己的似然最大的那个方向。那么我们说如果![]() 基于似然的曲率编码的几何图形(这个其实我不懂,但反正就是基于曲率一些信息)下,梯度的方向是非常的接近的,那么我们就可以认为
基于似然的曲率编码的几何图形(这个其实我不懂,但反正就是基于曲率一些信息)下,梯度的方向是非常的接近的,那么我们就可以认为![]() 是非常相似的。
是非常相似的。
非常有趣的就是其实就是费舍尔核函数在某些条件下会和字符串核函数,TF-IDF内积的核函数有很多的相似性,这里就不细说了。
14.3 在GLMs中使用核函数方法
在这一节中,我们将讨论一些简单的方法来使用核函数进行分类或者是回归。
14.3.1 核函数机器
我们定义的这个核函数机器是一个广义线性模型,我们的输入特征具有这样的形式(进行了非线性化):
![]()
其中![]() ,是K个中心点的集合,如果说
,是K个中心点的集合,如果说![]() 是一个RBF核函数,那么这个就叫做一个RBF网络。下面我们将讨论一些方法怎么样来选择参数
是一个RBF核函数,那么这个就叫做一个RBF网络。下面我们将讨论一些方法怎么样来选择参数![]() 。我们将上面这个式子称作核函数化的特征向量。注意,在我们这个方法下,我们的核函数不需要是Mercer 核函数。
。我们将上面这个式子称作核函数化的特征向量。注意,在我们这个方法下,我们的核函数不需要是Mercer 核函数。
比如说,我们将这个核化的特征向量运用到logistic回归当中的话,即:![]()
![]() 。这就提供了一个定义非线性决策边界的一个简单的方法。举一个例子,假设我们的数据是来自于异或的函数。具体我们先放图:
。这就提供了一个定义非线性决策边界的一个简单的方法。举一个例子,假设我们的数据是来自于异或的函数。具体我们先放图:

左边就是数据,我们的输入是0-1的1bit的数,输出同样是如此。由于这些个数据是重合的,所以我们在展示的时候采用了jittering的方法,就是加了一些加性噪声,我们可以看到在上面的图b中,我们用多项式来拟合(10维的),拟合的效果并不好(根本没有办法进行拟合),但是在(c)图中,我们用RBF核函数来拟合,效果却是出奇的好(其中,我们的四个中心点选得就是图中黑色的点)。
同样,我们也可以把核化的特征向量运用到线性模型当中去,即:![]() 。下图展示了RBF核函数中K=10,以及中心点均匀分布的这样一个情况。但是这个带宽是不一样的,从上到下,带宽依次变大:
。下图展示了RBF核函数中K=10,以及中心点均匀分布的这样一个情况。但是这个带宽是不一样的,从上到下,带宽依次变大:
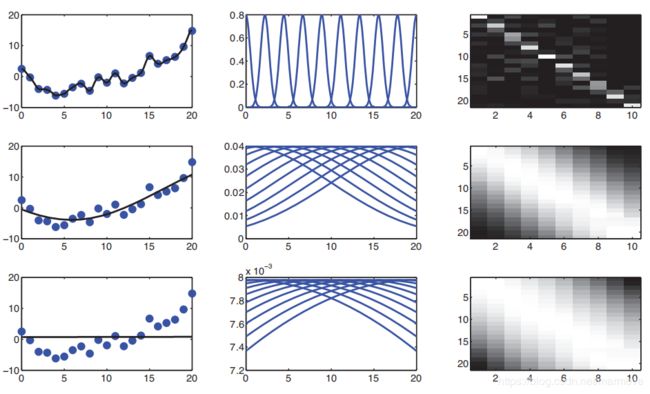
我们可以看到,带宽很小的时候,是非常的抖的,会对数据非常的敏感,这就是过拟合,带宽很大的时候,就是一条直线,这就是欠拟合,中间的带宽则刚刚好。
14.3.2 LIVMs,RVMs,和其它的稀疏向量机
关于核函数机器的一个最主要的问题就是:我们怎么去选择这样一个中心![]() ?如果我们的数据是处于一个低维的欧几里得空间的话,这样我们就可以在这个空间里面均匀的去选择这样的一个中心点(比如上面的logistc回归的例子)。但是呢,如果对于一个非常高维的空间的话,因为我们之前提到过一个叫做维度诅咒,这个方法有很大的问题。
?如果我们的数据是处于一个低维的欧几里得空间的话,这样我们就可以在这个空间里面均匀的去选择这样的一个中心点(比如上面的logistc回归的例子)。但是呢,如果对于一个非常高维的空间的话,因为我们之前提到过一个叫做维度诅咒,这个方法有很大的问题。
另一种方法是在数据中查找集群,然后为每个集群中心分配一个中心点(许多集群算法只需要一个相似性度量作为输入)。但是呢,每一个集群的高密度的点并不一定是用来计算输出的最好的中心点,因为很多时候做聚类和预测其实并不是非常的契合的。而且在聚类算法中,我们也要考虑到底要用多少个集群。
一个更加简单的方法就是让每一个原来的输入样本点作为中心(标准),即:
![]()
这样![]() ,所以这样,我们的参数就和我们的数据量一样多。但是我们可以用13章里面提到的一些促进稀疏的方法,给
,所以这样,我们的参数就和我们的数据量一样多。但是我们可以用13章里面提到的一些促进稀疏的方法,给![]() 一些稀疏的先验,我们叫这个方法为稀疏向量机器(sparse vector machine)。最长用的呢,就是使用
一些稀疏的先验,我们叫这个方法为稀疏向量机器(sparse vector machine)。最长用的呢,就是使用![]() 正则化(当然对于多类别的情况,可以用group lasso),我们称这个叫做L1VMs。当然也有L2VMs,不过这个并不是稀疏的。当然我们也可以用稀疏贝叶斯学习的方法(SBL/ARD),这样的话,我们的结果会更加的稀疏,这个方法就叫做关联向量机(relevance vector machine,RVM)
正则化(当然对于多类别的情况,可以用group lasso),我们称这个叫做L1VMs。当然也有L2VMs,不过这个并不是稀疏的。当然我们也可以用稀疏贝叶斯学习的方法(SBL/ARD),这样的话,我们的结果会更加的稀疏,这个方法就叫做关联向量机(relevance vector machine,RVM)
另一个来建立稀疏核函数机器的非常流行的方法叫做支持向量机(support vector machine or SVM),这在后面的第14.5中我们将会详细的讨论。与之前不同的是,这个并不是使用一个稀疏的先验,而是把似然进行了一些修正,这一点从贝叶斯的角度来说其实是非常不自然的,但是不管怎说,它的作用是相似的。
我们看下面一张图:
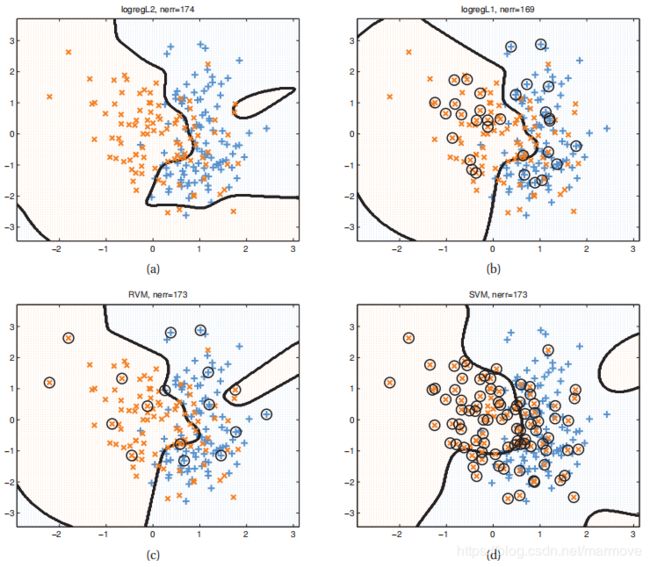
上面的图示一二维下的二元分类的一个例子,我们分别使用了四个算法L2VM,L1VM,RVM以及SVM,我们都使用了相同的RBF核函数。为了简单起见L2VM和L1VM中的![]() 都是人工选的。对于RVMs,参数是通过经验贝叶斯来估计的。而对于SVM来说呢,我们是使用CV来确定的参数,因为SVM对于参数的选择还是比较的敏感的。我们可以看到上述的算法的最终性能都是差不了太多的,我们可以看到RVM是最稀疏的,所以无论是训练还是说测试,其实都是最快的。
都是人工选的。对于RVMs,参数是通过经验贝叶斯来估计的。而对于SVM来说呢,我们是使用CV来确定的参数,因为SVM对于参数的选择还是比较的敏感的。我们可以看到上述的算法的最终性能都是差不了太多的,我们可以看到RVM是最稀疏的,所以无论是训练还是说测试,其实都是最快的。
我们再看下面的另一幅图:
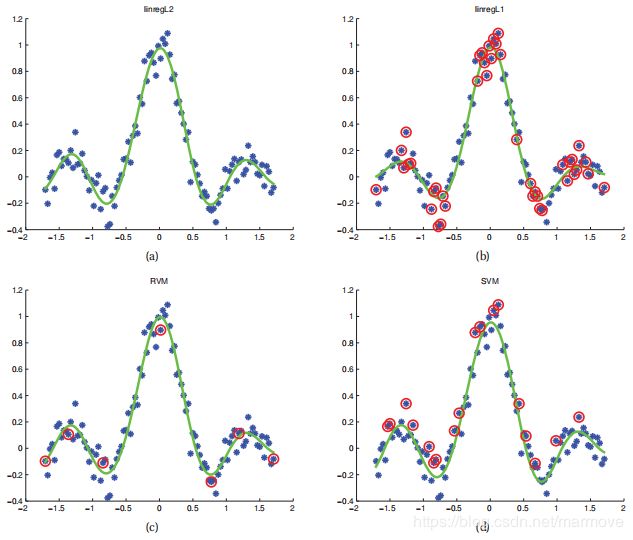
这个呢,我们是将上面说的那四个算法运用到了一维的线性回归当中去,其最终的分析与上面的结果其实是类似的。
14.4 核函数的技巧
与其说我们利用核函数的方法定义特征向量,即:![]() ,我们可以换一种方式,我们还是用原始的数据,但是我们对于算法进行一些改进,我们把算法里面的所有的内积
,我们可以换一种方式,我们还是用原始的数据,但是我们对于算法进行一些改进,我们把算法里面的所有的内积![]() 利用一个核函数
利用一个核函数![]() 来定义,这个叫做核函数的技巧。结果表明很多的算法都可以通过这样的方式被核化。下面我们给出一些例子。注意我们需要我们的核函数是Mercer核函数。
来定义,这个叫做核函数的技巧。结果表明很多的算法都可以通过这样的方式被核化。下面我们给出一些例子。注意我们需要我们的核函数是Mercer核函数。
14.4.1 核化的最邻近分类器
回顾我们在前面提到的1NN的分类器,我们只需要将测试的向量跟所有其余的向量计算一下它们的欧几里得距离,然后找到最近的那个然后看一下它的label,这就是对应于我们测试的数据的label。这个可以被进行如下的核化:
![]()
这允许我们对结构化数据对象应用最近邻分类器。
14.4.2 核化的K中心的聚类
K-means聚类器使用欧几里得距离来测量这个差异性,但是对于结构化的目标,其实一般来说是不太合适的。现在我们来考虑一下怎么去定义一个核化的版本。
首先第一步,我们要将K-means的算法替换成K-medoids算法。这个跟K-means非常的相似,在K-means里面,我们用这个类里面的所有的数据的均值来表示这个类,但是在K-medoids里面,我们用这个类里面所有数据的某一个数据来表示这个类。因此,我们总是处理整数索引,而不是数据对象。我们像以前一样把物体分配到最近的质心。当我们更新质心时,我们查看属于集群的每个对象,并测量它到同一集群中所有其他对象的距离之和;然后我们选择这个和最小的那个:
![]()
其中:
![]()
所以对于每一个集群,我们所需要的时间是![]() ,但是在K-means算法里面,对于每一个集群所需要的时间是
,但是在K-means算法里面,对于每一个集群所需要的时间是![]() 。具体的伪代码见如下的算法:
。具体的伪代码见如下的算法:

这个方法也可以被修改成一个分类器的方法,分到最近的那个中心点里面的位置去。即称之为nearest medoid classification。这个方法同样可以被核化,我们通过书上的公式14.30可以将距离的计算![]() 替换掉。
替换掉。
14.4.3 核化的ridge回归
将核技巧运用到基于距离的方法中是非常直接的。下面我们就要讲怎么把这个方法运用到参数的方法,例如ridge回归当中去,这为我们后面讲支持向量机开了一个好头。
14.4.3.1 原始的问题
令![]() 是某些特征向量,
是某些特征向量,![]() 是对应的
是对应的![]() 的设计矩阵,我们希望去最小化:
的设计矩阵,我们希望去最小化:![]() ,最终的优化的解是:
,最终的优化的解是:![]() 。
。
14.4.3.2 对偶问题
书上的公式14.34并不是内积的形式,因为是![]() 。但是呢,我们通过书上的公式4.107,我们可以重写ridge估计的结果:
。但是呢,我们通过书上的公式4.107,我们可以重写ridge估计的结果:
![]() ,这需要花费
,这需要花费![]() 时间来计算。对于D很大的情况下,这个是很有利的。此外,我们可以部分的对这个进行核化,通过将
时间来计算。对于D很大的情况下,这个是很有利的。此外,我们可以部分的对这个进行核化,通过将![]() 替换成Gram矩阵
替换成Gram矩阵![]() 。
。
我们定义如下的对偶变量:![]() ,那么我们的原始变量就可以重新写成如下的形式:
,那么我们的原始变量就可以重新写成如下的形式:
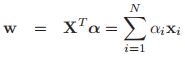
这告诉我们,其实我们的解向量就是N个训练向量的一个线性组合。在测试的时候,我们进行估计时,我么会有:
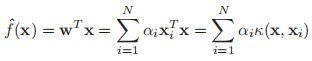
我们通过将原始的变量变为对偶变量,我们可以成功的将ridge回归进行核化。
14.4.3.3 计算的代价
我们计算对偶变量![]() 的代价是
的代价是![]() ,而计算原始的变量
,而计算原始的变量![]() 的计算复杂度是
的计算复杂度是![]() 。所以说核方法在高维的背景下可能会非常的有用。但是在预测的时候,使用对偶函数,我们需要的时间是
。所以说核方法在高维的背景下可能会非常的有用。但是在预测的时候,使用对偶函数,我们需要的时间是![]() ,但是我们使用原始的变量的话只需要
,但是我们使用原始的变量的话只需要![]() 的时间。在后面14.5我们会讲到,通过使得
的时间。在后面14.5我们会讲到,通过使得![]() 稀疏,来进一步加快这样的预测。
稀疏,来进一步加快这样的预测。
14.4.4 核函数PCA
在12.2中,我们知道如何使用PCA对数据进行线性的压缩。这需要我们对采样的协方差矩阵![]()
![]() 进行特征分解。然而我们也可以通过去求内积矩阵
进行特征分解。然而我们也可以通过去求内积矩阵![]() 的特征分解来计算PCA。这将允许我们使用内核技巧进行非线性的嵌入,我们称这个方法叫做核化的PCA。
的特征分解来计算PCA。这将允许我们使用内核技巧进行非线性的嵌入,我们称这个方法叫做核化的PCA。
首先我们令![]() 对应的特征向量会构成一个矩阵,即
对应的特征向量会构成一个矩阵,即![]() 是一个正交矩阵,其每一列对应的是
是一个正交矩阵,其每一列对应的是![]() 的特征向量,
的特征向量,![]() 每一个特征向量对应的特征值构成的对角矩阵。根据上面的定义,我们有
每一个特征向量对应的特征值构成的对角矩阵。根据上面的定义,我们有![]() ,我们在前面乘以一个
,我们在前面乘以一个![]() ,就可以得到:
,就可以得到:
![]()
从这个我们可以看出,![]() 对应的特征向量是
对应的特征向量是![]() ,相应的对应的特征值就是
,相应的对应的特征值就是![]() ,但是呢,这些特征向量是没有被归一化的,即:
,但是呢,这些特征向量是没有被归一化的,即:![]()
![]() 。所以归一化的特征向量是
。所以归一化的特征向量是![]() 。如果
。如果![]() ,在正常的PCA中,这是一个很常用的trick,因为
,在正常的PCA中,这是一个很常用的trick,因为![]() 的维度是
的维度是![]() ,而
,而![]() 是
是![]() ,同时我们还能在这个上面使用核函数技巧。
,同时我们还能在这个上面使用核函数技巧。
关于上面我们解释一下,在PCA中,其实我们是需要计算![]() 的特征向量,所以是对这个进行特征分解,然后找最大的那几个特征向量,但是这里我们先计算的是
的特征向量,所以是对这个进行特征分解,然后找最大的那几个特征向量,但是这里我们先计算的是![]() ,然后通过上面的手段进行相应的操作,得到
,然后通过上面的手段进行相应的操作,得到![]() 的特征分解,为什么这么做,从两个层面考虑,一方面是如果D>N的话,那么
的特征分解,为什么这么做,从两个层面考虑,一方面是如果D>N的话,那么![]() 进行特征分解的话,计算复杂度更高,所以选用后者。另一个方面就是出于核函数的考虑,在核函数里面我们有
进行特征分解的话,计算复杂度更高,所以选用后者。另一个方面就是出于核函数的考虑,在核函数里面我们有![]() ,而这个其实是不好算的,我们只有核函数是好算的,这就必须要用到gram矩阵,即
,而这个其实是不好算的,我们只有核函数是好算的,这就必须要用到gram矩阵,即![]() (这个是好算的)。
(这个是好算的)。
具体如下:
令![]() 是gram 矩阵,回想我们之前说过的mercer‘s 理论,我们之所以用核函数,是因为数据下面往往会有很多的结构特征,所以我们用
是gram 矩阵,回想我们之前说过的mercer‘s 理论,我们之所以用核函数,是因为数据下面往往会有很多的结构特征,所以我们用![]() 去替换
去替换![]() 。令
。令![]() 是对应的设计矩阵,所以
是对应的设计矩阵,所以![]() 是在对应的特征空间下的协方差矩阵。那么我们的特征的向量就是
是在对应的特征空间下的协方差矩阵。那么我们的特征的向量就是![]() (从
(从![]() 得到
得到![]() 的特征分解结果,当然这里是核化了的),其中
的特征分解结果,当然这里是核化了的),其中![]() 在上面已经有了定义。当然,我们不能直接计算
在上面已经有了定义。当然,我们不能直接计算![]() ,因为
,因为![]() 有可能是无限维度的。但是呢,我们可以计算测试向量
有可能是无限维度的。但是呢,我们可以计算测试向量![]() 在特征空间上的投影(这里其实我们就是要算怎么压缩,所以其实左边就是原来的数据,当然是核化了的,右边就是压缩矩阵,也是核化了的,所以这个的结果就是z,对应于前面的PCA):
在特征空间上的投影(这里其实我们就是要算怎么压缩,所以其实左边就是原来的数据,当然是核化了的,右边就是压缩矩阵,也是核化了的,所以这个的结果就是z,对应于前面的PCA):
![]()
其中![]() 。
。
我们所需要担心的还有最后一个细节,到目前为止,我们都是假设我们的投影数据的均值是0,但是这并不是一般的情况。在特征空间里面,我们并不能简单的抽掉这个均值。然而我们可以使用一个技巧,我们定义中心的特征向量为:![]() ,所以中心化的特征向量的Gram 矩阵如下:
,所以中心化的特征向量的Gram 矩阵如下:
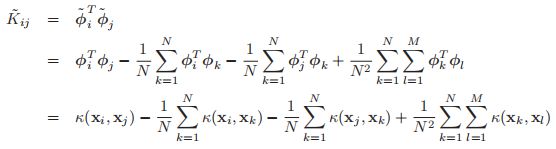
用矩阵的形式来表示,就是如下:![]() ,其中
,其中![]() 是中心矩阵。具体的伪代码如下(代码中一个是训练数据,训练数据用来生成压缩矩阵,另一个则是测试数据):
是中心矩阵。具体的伪代码如下(代码中一个是训练数据,训练数据用来生成压缩矩阵,另一个则是测试数据):

在线性PCA里面,我们会有限制,即压缩必须是![]() ,但是在kPCA中,我们可以是N个部分,因为我们的
,但是在kPCA中,我们可以是N个部分,因为我们的![]() 是
是![]() ,而且
,而且![]() 可能会非常的大,甚至会趋于无穷。关于kPCA,其实它的投影是非常的不自然的,在15.5中,我们将会讨论kPPCA。
可能会非常的大,甚至会趋于无穷。关于kPCA,其实它的投影是非常的不自然的,在15.5中,我们将会讨论kPPCA。
14.5 支持向量机(support vector machines,SVMs)
在14.3.2中,我们得到了一些推导稀疏的核函数机器的一些方法,主要是利用加入一些促进稀疏的先验进去。另一个方法呢,就是改变目标函数,我们把NLL替换成其它的损失函数,正如我们在6.5.5中讨论的那样。特别的,假设我们使用![]() 正则化的经验风险函数:
正则化的经验风险函数:

其中![]() (那么这个呢,其实是在原始的特征空间中的,后面我们也会讲到核化的版本),如果说
(那么这个呢,其实是在原始的特征空间中的,后面我们也会讲到核化的版本),如果说![]() 是二次的回归,那么这个就等价于ridge 回归。如果L是由公式6.73定义的log-loss函数的化,这就等价于logistic回归了。
是二次的回归,那么这个就等价于ridge 回归。如果L是由公式6.73定义的log-loss函数的化,这就等价于logistic回归了。
在ridge回归的例子中,我们的解是具有闭式表达式的,且具有如下的形式:![]()
![]() ,然后我们利用这个进行预测,即
,然后我们利用这个进行预测,即![]() 。我们在14.4.3中提到过,我们可以对这个进行重写,这样的话我们就可以对其进行核化,但是呢,这并不会导致结果的稀疏性。如果我们把这个损失函数替换成其它的一些损失函数,我们下面将会讲到,那么我们就可以确保我们的解是稀疏的,我们的数据只取决于训练数据的一部分,叫做支持向量。所以我们将修改过的损失函数和核函数技巧整合在一起,就叫做支持向量机(support vector machine,SVM)。这个方法的设计最一开始是为了二元分类的,但是后来其实也可以运用到回归或者是多元分类当中去。
。我们在14.4.3中提到过,我们可以对这个进行重写,这样的话我们就可以对其进行核化,但是呢,这并不会导致结果的稀疏性。如果我们把这个损失函数替换成其它的一些损失函数,我们下面将会讲到,那么我们就可以确保我们的解是稀疏的,我们的数据只取决于训练数据的一部分,叫做支持向量。所以我们将修改过的损失函数和核函数技巧整合在一起,就叫做支持向量机(support vector machine,SVM)。这个方法的设计最一开始是为了二元分类的,但是后来其实也可以运用到回归或者是多元分类当中去。
请注意,从概率的角度来看,SVMs是非自然的。首先,它们在损失函数中耦合稀疏性,而不是在先验函数中耦合稀疏性。其次,它们使用的是一个算法的技巧,而不是作为模型的显式部分。最后,支持向量机不产生概率输出,这造成了各种困难,尤其是在多类分类设置中。
其实,我们可以获得稀疏的,基于概率的,基于核方法的,多类别的分类器,其实他们的作用可能比SVMs要更好,比如说我们在14.3.2中提到的L1VM或者RVM方法。那么为什么SVMs是非概率的不自然的模型,我们还是要去讨论它呢,因为基于以下的两点考虑:
第一点:它们是非常流行并且广泛使用的,所以所有的学习机器学习的学生应该去了解它。
第二点:跟其它很多概率模型上的方法相比,它在计算上有很多的优势。
14.5.1 回归的SVMs
关于核化的ridge回归其实存在一个问题就是它的这样一个解![]() 是依赖于所有的训练样本的。
是依赖于所有的训练样本的。
(Vapnik et al. 1997)提出了一个关于Huber 损失函数的变体,叫做epsilon insensitive loss function,定义如下:
![]()
这意味着估计点真实点如果很靠近,大概在![]() 这个级别的话,那么我们就不去进行惩罚。对应的目标函数通常就会写成如下的形式:
这个级别的话,那么我们就不去进行惩罚。对应的目标函数通常就会写成如下的形式:

其中![]() 以及
以及![]() 是一个正则化常数。我们这个目标呢,是凸的,没有约束的,但是是不可以微分的,因为里面包含了一个绝对值函数。那么怎么去解这个问题呢,一个比较流行的方法就是把这个问题变成带约束的优化问题。我们利用增加松弛变量的方法,即:
是一个正则化常数。我们这个目标呢,是凸的,没有约束的,但是是不可以微分的,因为里面包含了一个绝对值函数。那么怎么去解这个问题呢,一个比较流行的方法就是把这个问题变成带约束的优化问题。我们利用增加松弛变量的方法,即:
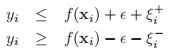
以及:
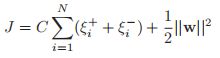
这个其实也不难理解,就是对绝对值那一块,加一个限制变量,并且最终的等号都是一定可以取到的,其中![]() 。
。
关于这个的求解,在Schoelkopf and Smola 2002中表明最终的结果就是![]() ,其中
,其中![]() 。结果进一步表明
。结果进一步表明![]() 向量是稀疏的,因为我们并不在意误差小于
向量是稀疏的,因为我们并不在意误差小于![]() 。对于
。对于![]() 的那些
的那些![]() 来说,就称之为支持向量。一旦模型被训练出来,我们就可以使用如下的模型进行预测:
来说,就称之为支持向量。一旦模型被训练出来,我们就可以使用如下的模型进行预测:![]() ,同时也是:
,同时也是:![]() ,此外我们也可也用核
,此外我们也可也用核![]() 来替代
来替代![]() ,那么我们就得到了核化的解:
,那么我们就得到了核化的解:![]() 。
。
14.5.2 SVMs应用到分类上
现在我们讨论怎么把SVMs应用到分类问题上。我们先考虑二元分类的问题,最后在讨论多元分类的问题。
14.5.2.1 Hinge loss
在6.5.5中,我们表明logistic回归模型的NLL如下:![]() (详细看6.5.5)。在我们这一节当中,我们将使用另一个损失函数叫做hinge loss,其定义如下:
(详细看6.5.5)。在我们这一节当中,我们将使用另一个损失函数叫做hinge loss,其定义如下:
![]()
这里![]() 表明的是我们选择
表明的是我们选择![]() 这个标签的信心。书上前面的图6.7给出了具体的图,就像个门铰链一样。所以整体的目标函数就具有如下的形式:
这个标签的信心。书上前面的图6.7给出了具体的图,就像个门铰链一样。所以整体的目标函数就具有如下的形式:
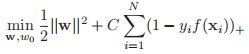
同样的,这个又是不可微分的,因为它里面含有max这一项。当然我们通过引入松弛变量,这个问题等价于求解(很多非可微的可以做增加松弛变量来求解):
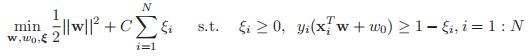
关于这个的具体的求解暂时我们先不做过多的讨论,后面有时间我再来思考整合,有人可以得出我们最终的解的形式是:![]() ,其中
,其中![]() 是稀疏的。同样的对于
是稀疏的。同样的对于![]() 的那些向量
的那些向量![]() ,我们称之为支持向量。那么在测试的时候,我们就可以进行如下的估计:
,我们称之为支持向量。那么在测试的时候,我们就可以进行如下的估计:
![]() ,利用上面推导的结果以及核函数的技巧,我们会有:
,利用上面推导的结果以及核函数的技巧,我们会有:
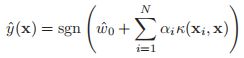
14.5.2.2 大的边缘空白原则(large margin principle)
这一节中,我们将从一个完全不同的角度,来得到书上的公式14.58。回想我们之前的目标就是推导一个判别函数![]() (在核函数所表示的特征空间中是线性的),在这样的一个空间中,我们看下图:
(在核函数所表示的特征空间中是线性的),在这样的一个空间中,我们看下图:
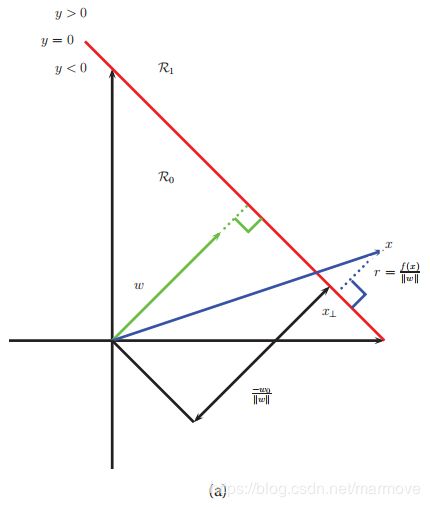
对于某个点![]() ,我们有
,我们有![]() ,其中r是
,其中r是![]() 在决策边界上的投影,
在决策边界上的投影,![]() 是点
是点![]() 在决策边界上的投影点。因此我们会有:
在决策边界上的投影点。因此我们会有:
![]()
因为我们有![]() ,所以
,所以![]() 。因此
。因此![]() 以及
以及![]() 。
。
那么在做二分类的时候,我们希望![]() 这个值越大越好,正如下面的图:
这个值越大越好,正如下面的图:
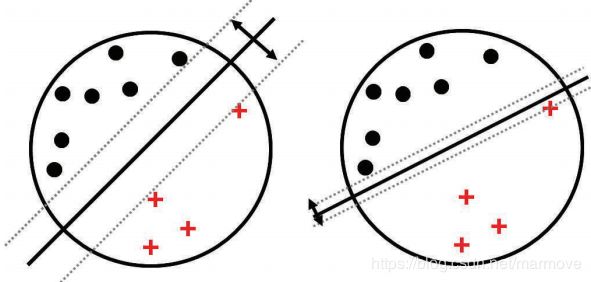
同样的数据,我们进行二分类,但是很明显我们更需要的第一种,它显然把这样一个类别分的更开。所以对于这样一类数据,单纯从分开,我们是有很多的决策边界的,但是我们要选择旁边空白(margin)最大的那种。当然在此之前,我们要确保是能够把所有的数据进行正确的分类的,所以我们希望![]() ,所以我们的目标函数就是:
,所以我们的目标函数就是:
![]()
注意,如果我们对参数进行如下的处理,即![]() ,我们根据公式,发现,其实我们的点到边界的距离其实根本没有改变,所以我们定义,对于离边界最近的那个点,我们有
,我们根据公式,发现,其实我们的点到边界的距离其实根本没有改变,所以我们定义,对于离边界最近的那个点,我们有![]() ,这样的话,我们就希望去优化:
,这样的话,我们就希望去优化:
![]()
这个1/2没有任何意义,只是为了方便。我们根据这个目标函数就很容易看出,其实我们就是在所有的点都处于正确的分类情况下,保证最小的那个距离是1,所以这也是为什么SVM是large margin classifier 的一种。
如果数据不是线性可分的(即使使用了核技巧之后),那么就没有合适的解使得对于所有的![]() 都有
都有![]() ,那么我们就引入松弛变量
,那么我们就引入松弛变量![]() ,当
,当![]() 时就表明这个数据点是处于正确的分类并离决策边界足够的远。其余的情况下,那么
时就表明这个数据点是处于正确的分类并离决策边界足够的远。其余的情况下,那么![]() 。那么在这个定义下,很明显,如果
。那么在这个定义下,很明显,如果![]() ,就表明这个点被很好的分类了,但是离决策边界不够远,而如果
,就表明这个点被很好的分类了,但是离决策边界不够远,而如果![]() ,那就表明这个点直接就分错了。所以我们的新的目标函数如下:
,那就表明这个点直接就分错了。所以我们的新的目标函数如下:
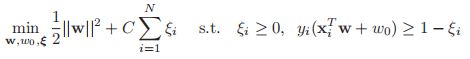
我们发现这个式子和书上的公式14.58是一模一样的。由于![]() 意味着点
意味着点![]() 是被误分类的,所以我们可以将
是被误分类的,所以我们可以将![]() 作为误分类点的上界。
作为误分类点的上界。
参数![]() 是一个正则化参数,表明我们能够容忍在训练数据中,有多少个数据会被误分类。我们经常定义
是一个正则化参数,表明我们能够容忍在训练数据中,有多少个数据会被误分类。我们经常定义![]() ,其中
,其中![]() ,这个称作
,这个称作![]() ,对于参数的选择,我们通常用CV来做。
,对于参数的选择,我们通常用CV来做。
14.5.2.3 概率的输出
对于SVM来说,我们进行的是一个硬判决,即![]() ,但是很多时候我们需要知道我们对于我们预测的一个相信(confidence)的程度。一个启发式的方法,就是假想我们的
,但是很多时候我们需要知道我们对于我们预测的一个相信(confidence)的程度。一个启发式的方法,就是假想我们的![]() 是具有如下的形式
是具有如下的形式![]() ,那么我们就可以把SVM的输出转化成概率模型:
,那么我们就可以把SVM的输出转化成概率模型:![]() (这里我其实不太明白会引入a和b两个参数),其中a,b可以通过另一个独立的验证集合,利用最大似然估计进行估计(如果直接用训练集去估计a和b的话,可能会导致严重的过拟合)。
(这里我其实不太明白会引入a和b两个参数),其中a,b可以通过另一个独立的验证集合,利用最大似然估计进行估计(如果直接用训练集去估计a和b的话,可能会导致严重的过拟合)。
但是我们最终得到的这个概率模型其实并不一定会很可靠,因为其实我们并没有办法去证明我们的SVM中的![]() 可以看作log-odds比率。
可以看作log-odds比率。
14.5.2.4 SVM应用到多类别的分类问题中
在书中的8.3.7中,我们看到我们如何将一个二元的logistic回归问题推广到多类别的情况。我们通过将sigmoid函数替换成softmax函数,将伯努利分布替换成multinomial分布。但是对于SVM来说,其实这个并不简单,因为这里的每一个输出的尺度其实是没有经过很好的归一化的。
一个比较容易看出来的方法就是使用 one-versus-the-rest 方法(也叫做 one-vs-all),在这个方法里面我们会训练C个二元分类器(其实我觉得是C-1个就好了)![]() ,其中认为类别c正的,其余的数据构成的类别统称为负的这样若干的二元分类器就会把数据分成很多类,但是这样做会导致部分区域是不知道是哪一类的,比如我们看下图:
,其中认为类别c正的,其余的数据构成的类别统称为负的这样若干的二元分类器就会把数据分成很多类,但是这样做会导致部分区域是不知道是哪一类的,比如我们看下图:
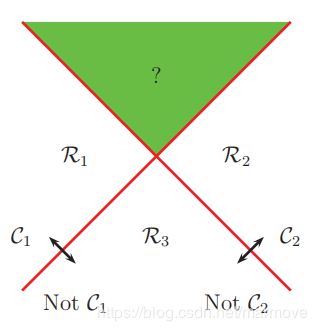
首先,我们把![]() 拿出来,整个区域被分成了两块,
拿出来,整个区域被分成了两块,![]() 以及not
以及not![]() ,再者呢,我们把
,再者呢,我们把![]() 也拿出来,整个区域变成了
也拿出来,整个区域变成了![]() 和not
和not ![]() ,这样一来,看上图,整个区域就被分成了4块,分别是
,这样一来,看上图,整个区域就被分成了4块,分别是![]() ,
,![]() ,not
,not![]() 和
和![]() (这一块区域呢,我们可以把它归为C3),还有一块区域是又是
(这一块区域呢,我们可以把它归为C3),还有一块区域是又是![]() 又是
又是![]() (这一块区域就是模糊的,我们没有办法进行很好的分类)。
(这一块区域就是模糊的,我们没有办法进行很好的分类)。
那么怎么去解决这样一个问题呢,我们去做这样的一个判定![]() ,比如说刚才上面虽然有一块区域里面的点同时都是
,比如说刚才上面虽然有一块区域里面的点同时都是![]() 以及
以及![]() ,但是其实在计算
,但是其实在计算![]() 会有大有小,所以我们就选择那个较大那个类别作为最终的选择。但是其实这个也有问题,因为这个值在尺度上会有一定的问题,它并不能够很好的平衡。可能同时进行训练的话,相比于一个一个训练,效果会更好,(Weston and Watkins 1999),但是计算复杂度上,由原来的
会有大有小,所以我们就选择那个较大那个类别作为最终的选择。但是其实这个也有问题,因为这个值在尺度上会有一定的问题,它并不能够很好的平衡。可能同时进行训练的话,相比于一个一个训练,效果会更好,(Weston and Watkins 1999),但是计算复杂度上,由原来的![]() 变成了
变成了![]() 。
。
另一个方法就是使用one-versus-one或者是OVO的方法,也称作all pairs,在这个情况下,我们要训练![]() 个分类器
个分类器![]() ,对于每个数据,我们将其分类到它所被分类的那个类别次数最多的类里面去。但是其实这也会导致模糊的区域,如下图:
,对于每个数据,我们将其分类到它所被分类的那个类别次数最多的类里面去。但是其实这也会导致模糊的区域,如下图:
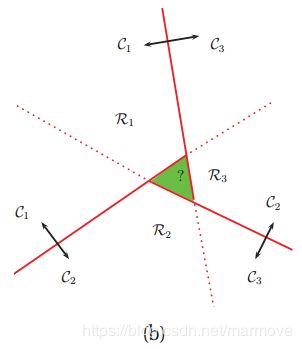
这里可能会有一些方法,具体参见书上的参考文献。
14.5.3 选择C
无论是在分类问题还是回归问题中应用SVMs,我们都需要指定核函数以及参数![]() 。我们一般使用cross-validation来进行C的选择。我们要注意的一点是,C和核参数之间的相互影响关系是很大的。我们来看个例子,假设我们使用的核函数是RBF核函数,其精度参数为:
。我们一般使用cross-validation来进行C的选择。我们要注意的一点是,C和核参数之间的相互影响关系是很大的。我们来看个例子,假设我们使用的核函数是RBF核函数,其精度参数为:![]() 。如果
。如果![]() ,对应于比较窄的核函数,那么我们就需要比较重的正则参数,因此就要选择小的
,对应于比较窄的核函数,那么我们就需要比较重的正则参数,因此就要选择小的![]() 。如果
。如果![]() ,那么我们就要使用一个更大的
,那么我们就要使用一个更大的![]() ,所以
,所以![]() 和
和![]() 是紧密的结合在一起的。
是紧密的结合在一起的。
14.5.4 关于一些关键点的总结
我们总结一下上面的讨论,我们意识到SVM分类器包含3个主要的成分:核函数技巧,稀疏性,以及大的margin原则。核函数技巧从某种程度上来说可以阻止欠拟合,核函数可以确保特征向量是足够的丰富,丰富到可以用一个线性分类器进行分类,如果我们原始的数据维度已经很高了,特征已经很丰富了,那么我们其实就使用线性核函数![]() 就可以了。
就可以了。
稀疏性和大的margin原则对于阻止过拟合是很有必要的。当然其实如果是要保证稀疏性,我们可以使用![]() 正则化,去最大化margin,我们后面会学到boosting
正则化,去最大化margin,我们后面会学到boosting
14.5.5 关于SVMs的概率论的解释
在14.3节中,我们看到如何将核函数运用到GLMs模型中,并推导了基于概率模型的分类器,比如说L1VM以及RVM。在15.3中,我们将会讨论高斯过程分类器,也使用了核函数。但是呢,所有的这些方法都是使用了logistic或者是probit似然函数,在SVM中,我们则是使用了hinge损失函数。下面我们将从概率模型的角度去解释SVM。那么我们就必须要把![]() 解释成某个NLL,其中
解释成某个NLL,其中![]() ,以及
,以及![]() 是margin。因此
是margin。因此![]() 以及
以及![]() ,从概率学的角度来看,我们应该要有:
,从概率学的角度来看,我们应该要有:![]() 是一个独立于
是一个独立于![]() 的常数(理论上应该是等于1吧)。但是事实上并非如此。
的常数(理论上应该是等于1吧)。但是事实上并非如此。
然而呢,如果我们愿意将这样一个sum-to-one的条件放松一下,建立一个叫做伪似然的的东西,我们就可以对于hinge loss推导出概率论的解释,实际上我们会有:
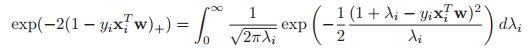
这样负的hinge loss的指数可以被表示成Gaussian scale mixture。那么基于这样的模型,我们就可以将EM算法或者是Gibbs 采样运用到SVM当中去,其中![]() 是隐变量。这样SVM就可以跟基于贝叶斯的方法打上关系。
是隐变量。这样SVM就可以跟基于贝叶斯的方法打上关系。
14.6 判别核方法的比较
到目前为止,我们已经提到了很多基于核函数的一些分类和回归的方法,具体总结如下(GP是在第十五章中会讲到的高斯过程):

每一列具有如下的意义:
optimize ![]() 一个关键的问题就是我们的目标函数
一个关键的问题就是我们的目标函数![]() 是否是凸的。比如在L2VM,L1VM以及SVMs中,这个目标函数其实就是凸的,在RVMs中则不是凸的。GPs呢是贝叶斯的方法,计算的是参数后验分布。
是否是凸的。比如在L2VM,L1VM以及SVMs中,这个目标函数其实就是凸的,在RVMs中则不是凸的。GPs呢是贝叶斯的方法,计算的是参数后验分布。
optimize 核函数:所有的方法我们都需要一个调节核函数的这样一个参数,比如说RBF核函数的带宽,以及正则化的水平。对于基于高斯分布的方法,包括L2VM,RVMs 和 GPs,我们可以先去计算边缘似然函数(因为是高斯的,所以比较容易计算),然后利用基于梯度下降的方法进行优化,然后计算相关参数。对于SVMs和L1VMs,我们则只能够使用交叉验证的方法,这样就会比较的慢。
稀疏性:L1VMs,RVMs和SVMs都是稀疏的核方法,在这些方法中,我们只会使用训练数据里面的部分数据。GPs和L2VM则并不是稀疏的:他们使用所有的训练样本。关于稀疏的核方法,他们在训练时会更加的快,另外稀疏的方法其实能提高精度。
概率性的:所有的方法除了SVMs以外都提供了概率上的输出,即![]() ,虽然说SVMs也提供了相应的方法去得到概率输出,但是其实这个概率是不太准确的(近似的并不是很好)
,虽然说SVMs也提供了相应的方法去得到概率输出,但是其实这个概率是不太准确的(近似的并不是很好)
多类别:除了SVMs之外,所有的方法都可以很自然的应用到多类别的场景中,我们只要将Bernoulli分布替换成multinoulli,但是对于SVMs则相对就比较的复杂。
Mercer 核函数:SVMs和GPs需要我们的核函数是正定的,其它的方法则不需要。
除了这些不同之外,还有一个自然的问题:哪种方法最有效?在一个小实验中,我们发现所有这些方法在对一系列问题求平均值时都具有相似的精度,前提是它们具有相同的核,并且正则化常数选择得当。
考虑到在统计学上的性能其实是大致相同的,那么在计算复杂度上面的性能呢?GPs和L2VM是最慢的,需要![]() 的时间,因为它们并没有探索数据的稀疏性。而SVMs则也需要
的时间,因为它们并没有探索数据的稀疏性。而SVMs则也需要![]() (但是其探索了数据的稀疏性),但是对于SVMs需要使用交叉验证的方法,所以SVMs是要比RVMs要慢的,L1VM是要比RVM要快的。
(但是其探索了数据的稀疏性),但是对于SVMs需要使用交叉验证的方法,所以SVMs是要比RVMs要慢的,L1VM是要比RVM要快的。
14.7 构建生成模型的核函数
还有一种不同的核函数,我们称之为平滑的核函数,可以用来创建非参数的密度估计。可以用来做非监督的密度估计![]() ,或者是对于分类回归问题创建生成模型
,或者是对于分类回归问题创建生成模型![]() 。
。
14.7.1 平滑的核函数
如果一个核函数满足以下的一些性质:
![]()
那么我们就称这个核函数为平滑的核函数。
一个简单的例子就是高斯核函数:
![]()
我们可以通过引入带宽参数![]() ,我们可以控制核函数的宽度,这样我们就有:
,我们可以控制核函数的宽度,这样我们就有:
![]()
如果我们的输入是向量的话,那么我们可以定义RBF核函数:![]() ,在高斯核函数下,具体的形式就是:
,在高斯核函数下,具体的形式就是:
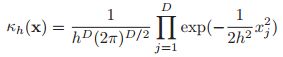
尽管高斯核函数很流行,但是它们是没有有界的支撑集的。
另一个核函数叫做Epanechnikov kernel,它具有比较紧凑的支撑集,具体的定义如下:![]() ,下图展示了不同核函数的形状:
,下图展示了不同核函数的形状:

紧凑的支撑集的好处就是计算的这个效率会更快,因为我们可以使用快速近邻法去计算密度(这个具体的实施过程还没有很了解)。不幸的是,Epanechnikov kernel在其支撑集的边界处是不可微的,所以我们还有一个核函数叫做tri-cube核函数,定义如下:
![]()
我们可以根据上图看到,这个核函数就解决了边界不可微的问题。
还有一个比较简单的核函数,叫做boxcar 核函数:![]() ,下面我们将使用该核函数。
,下面我们将使用该核函数。
14.7.2 核函数密度估计(Kernel density estimation,KDE)(先发上来,后面再把内容补上)
回顾一下我们在11.2.1中所学的高斯混合模型,这是一个关于![]() 的数据的参数密度估计器。然而,这里我们需要特别的指出
的数据的参数密度估计器。然而,这里我们需要特别的指出![]()