论文太多看不过来?快让人工智能帮你阅读分析
人工智能目前不能替代你做文献回顾,但它可以帮助你显著提升效率。
 Photo by Brett Jordan on Unsplash
Photo by Brett Jordan on Unsplash
疑惑
在公众号,我介绍过的主题很多,其中比较成体系的,至少包括以下几种:
数据科学与人工智能
研究方法
效率工具
文章写得多了,就有许多老读者,是一直在看。
看着看着,疑惑就来了:
王老师,你一边介绍人工智能与自然语言处理技术有多么厉害,一边教我用手动方式阅读、分析文献和整理笔记。难道「人工智能」不能自动帮我提高读论文的效率吗?
这是个好问题。
进展
诚然,我们已经看到,人工智能不像当年的「土耳其机器人」那样蒙人,而是确实有实际的用处。

例如说,确实围棋下赢了国手,Jeopardy 打败了冠军,自动驾驶比人开得还稳当。

若是这些看似离你远了一些,那你可以拿出手机,尝试一下语音输入,识别率也是挺高的。
特别是,最近我看到这样一则视频,展示人工智能如何帮助普通人了解 COVID 19 的相关知识。
通过自然语言的对话,人们就可以获得相应的讯息。整个儿过程自然流畅。
这种应用,功德无量。
可是在学术论文的阅读、分析和创作方面,目前人工智能确实还无法替代人。
如果你今后打算选择学术作为职业,这不算坏事儿。假使一旦你可以被机器轻易替代,那饭碗多半就不保了。
自然语言处理的演进,特别是深度学习巨量模型的发展,又确实让自然语言处理任务的榜单时常被刷新。
你看这张图,演示了目前模型参数的增长趋势。
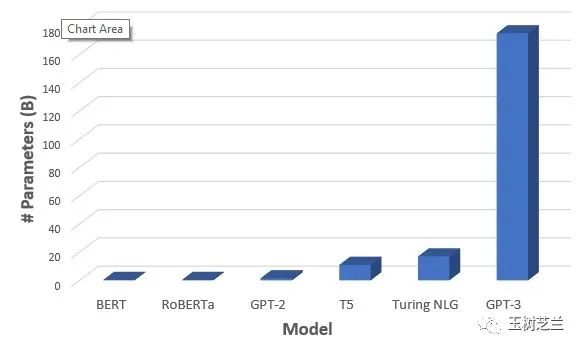
而相应地,文本分类、阅读理解、文本生成、机器翻译、自动问答、文本总结等任务上,机器好像越来越厉害。
既然这些技术,很多都是跟论文读写相关的,为什么不能直接应用,帮助咱们快速高效处理文献分析呢?
困难
这里,至少有两个瓶颈:
首先是数据。目前学术界生产论文的速度着实恐怖。别说人读不过来,机器也费劲。不光是分析困难,下载都是个大麻烦。
当年就是因为试图把论文都下载下来,开源给所有人,Aaron Swartz 这样高技术人才被判刑,直至造成他自杀的悲剧。

现在论文比那时还要多得多,普通人即便有了模型代码,也困于数据不足,没有办法加以有效应用。
其次是背景知识。现在的深度学习模型,虽然能霸榜,但它只是通过大量数据输入,对某一特定领域的文本有了「感觉」,不能够形成真正的知识结构,甚至做语义级别的理解与演绎推理。正因如此,人工智能的另一个分支「知识图谱」才会看不上「深度学习」这种玩儿概率的方式。
但是这并不意味着问题无解。虽然机器目前没法替我们做研究或者写综述,但是它确实可以有效帮我们处理其中很多枯燥、机械和重复的环节。
一篇文章可能写得很冗长。但是做领域扫描时,你其实只是想了解其中的重点。
在《如何高效读论文?》一文中,我给你讲过,怎么进行非线性阅读,快速抓住论文的重点。

但是那毕竟是手工的方式。如果机器经过海量论文数据的学习和训练,自动找到并且归纳总结这些重点部分,一次性呈现给你,岂不是更妙?
这其实就是若干个自然语言处理简单任务的综合,难度其实并不算高。
但是正如咱们前面所说,得有数据。
没有海量的论文库和足够的计算资源,你就没有办法进行这样的训练。
所以,我暂时放弃了自己利用开源工具处理论文的思路,开始寻找一款现成的工具或服务,帮助我进行论文的自动阅读、分析和梳理,成为我提升效率、减少低效劳动的帮手。
发现
功夫不负有心人,还真让我找到了。
这款工具,具有以下特点:
一键分析论文。自动形成重点摘要。
以客观形式,总结归纳全文及各部分的主要内容和贡献。如果你常做文献回顾,你应该知道这意味着什么。
自动抽取论文图表。将表格数据直接导出成 Excel 格式,便于分析、对比和二次利用。如果你经常要比较结果数值,这会帮你省下很多精力和时间。
汇总全部数据和代码链接。让你直达代码仓库和下载数据。
一键导出所有参考文献列表到 Bibtex 或者 RIS 格式。
对所有参考文献,提供快速分析和展现功能。让你快速判定是否有延伸阅读的必要性。
不仅如此,它还和好几种不同的文献分析工具整合,使得你可以把其他工具的结果直接汇总起来。例如可以轻易看见论文被提及、支持或反对的数量等。
你可能会疑惑:
有了这样的工具,还需要自己读论文吗?
当然需要。特别是精读,还是要自己做的。
但是初筛的泛读和领域扫描阶段,这款工具可以帮你省下大量的力气。
不但如此,它还会自动抽取文中出现的术语,帮你构建直达释义网站的链接。
由于这款工具的功能比较丰富,我专门为你做了个视频教程。带你一步步了解它的功能,享受它带来的便利。