超分综述:Deep Learning for Image Super-resolution:A Survey
instroduction
1 introduce
- 总结了几方面:problem settings、数据集、performance metrics、SR方法、特定领域应用
- 以结构组件形式,总结超分方法的优点与限制
- 讨论了存在的问题和挑战,以及未来的趋势和发展方向
整体结构:
method
Super-resolution Frameworks
灰色表示不可学习的上采样,绿色和蓝色代表可学习的上采样和下采样
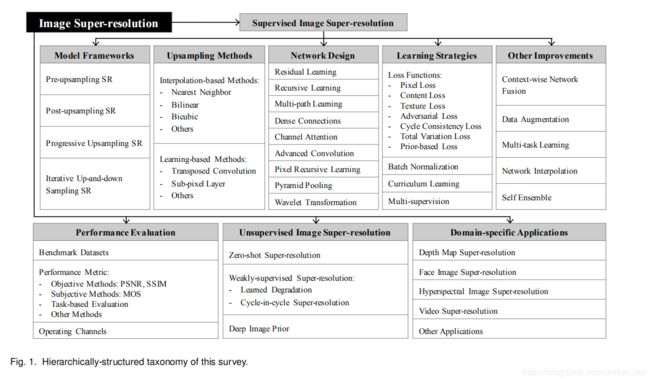
1 pre-upsampling SR
用传统方法(如双三次插值)上采样,然后用cnn重构缺失的细节信息
优点是困难的上采样任务用插值代替,更简单,减少学习难度,能学习任意大小倍数.
缺点,引入噪声和模糊,大多数操作在更大尺度图片上,计算量大
2 Post-upsampling Super-resolution
用end-to-end leatnable上采样层代替预定义的上采样操作
在网络最后再进行上采样,减少计算量
缺点,上采样操作一步完成,增加了大倍数的学习难度,每个扩大倍数需要一个单独的SR模型,不能满足muti-scale SR
3 progressive upsampling super-resolution
级联stage,每个stage包含cnn+上采样,逐步构建超分图像
优点,通过分解任务,不但减少了计算量,提升了效果,尤其是大倍数的效果,而且没有引入额外的时间和空间cost解决了多尺度超分问题
4 iterative up-and-down sampling super-resolution
用back-projection挖掘LR-HR的联系,之前这种方法没有用在深度学习上,存在不能学习的操作,所以提出了deep back-projection network(DBPN) 连接上采样和下采样层,最终HR result使用所有中间重建的HR feature map的串接
unsample methods
1 interpolation-based upsampling
- 最近邻插值
- bilinear interpolation
- bicubic interpolation,常用于构建数据集
缺点: 计算复杂度,放大噪声,模糊结果
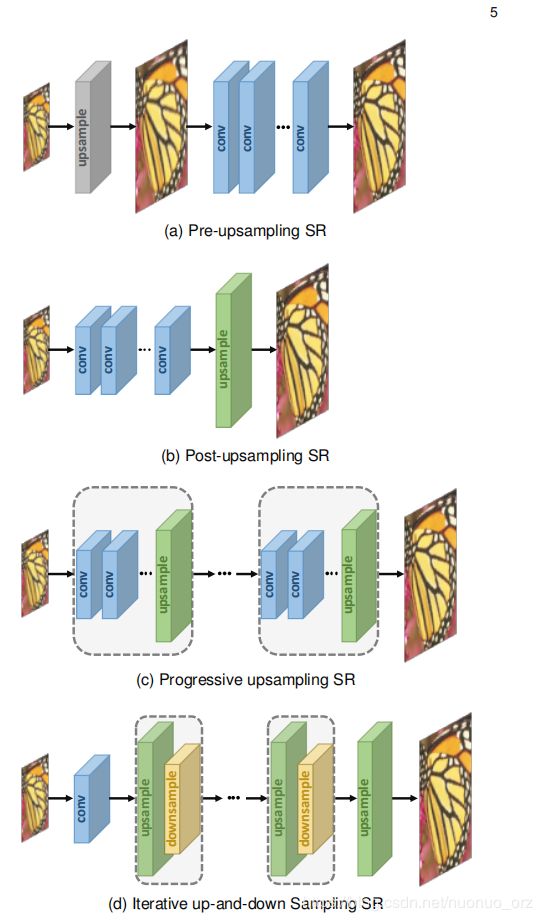
2 learning-based upsampling
转置卷积,也叫反卷积,
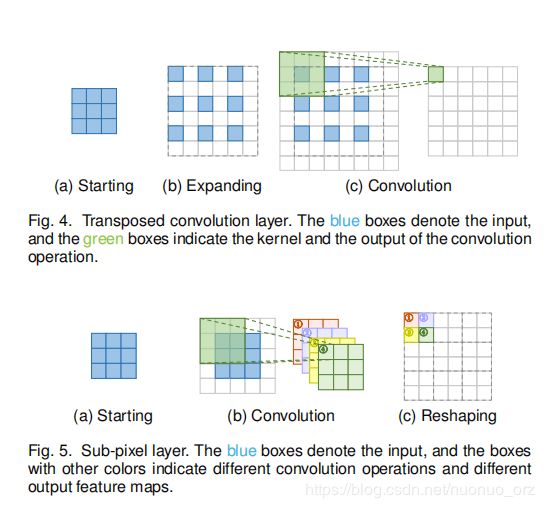
用3*3卷积核实现2倍上采样,
- 把输入变为原来两倍,新加入值设为0
- 使用一个33卷积,步长为1,padding为1
比如输入为55,第一步变成1010,过卷积之后大小不变,结果为1010
再HR中广泛使用,然而,再每个区域上容易导致uneven overlapping,不均匀重叠,在不同轴相乘的结果创建一个特征棋盘,比如不同大小的图案,不利于SR的表现
这句没看懂
sub-pixel layer
也是一个能端到端学习的上采样层,s为放大倍数,输出的通道数为s2*c,然后再进行reshape操作,h*w*S2C -> sh * sw * c,这样,感受野能上升到3*3 (为啥?)
优点,更大的感受野,
缺点,blocky regions共享相同的感受野,may result in some artefacts near the boundaries of different blocks
network design
residual learning
global residual learning
只学习input image 和out image之间的残差,
local residual learnign
类似于resnet,用来解决网络加深带来的梯度消失问题,增加学习能力
recursive learning
为了在不引入额外参数的情况下获得更大感受野和学习到更高层次的特征,利用循环,将同一个模块使用多次
DRCN用一个residual block作为循环单元25次,取得更好的表现
MemNet memory block,由6-recursive block组成,每次循环输出的结果concatnated,经过1*1卷积for记忆或遗忘。
muti-path learning
使用模型多个路径的特征
global muti-path learning
用多条路径提取图像不同区域(还是不同领域,层面)的特征,增强特征提取能力,
local multi-path learning
同一特征图,分别用33和55卷积来提取特征,将结果concat
scale-specific multi-path learning
不同的方法倍数,经过同样的卷积层,即共享feature extraction
Dense Connections
参考desnet,不但减少梯度消失,鼓励特征复用,还靠减少通道数量来减少参数,
被应用在很多SR网络上,dense连接在上采样和下采样层之前
channel attention 通道注意力
每个通道,经过全局平均池化层变为一个值,然后经过两层全连接,产生channel-wise scalinf factors,再和input相乘,进行缩放
adcanced convolution,最新的卷积方法
dilated convolution,空洞卷积,增加感受野来提升性能
group convolution,能大幅度减少参数和计算,只牺牲一点性能
pixel recursive learning
多数SR模型把其看作一个像素独立的任务,不能找到生成像素之间的内在联系。
使用两个网络捕获全局上下文信息和serial generation synthesizes,
受到人注意力转移机制启发,the Attention-FH 凭借recurrent policy 来发现注意panch和进行局部增强
pyramid pooling
提出pyramid pooling module更好的利用全局和局部的上下文联系
输入hwc,分成MM块,每块过全局平均池化,再用11卷积压缩到一个通道,然后再用双线性插值来上采样到输入尺寸,使用不同的M,有效的融合全局和局部信息
wavelet transformation
将图像信号转换成包含细节信息的高频wavelet和全局信息的低频wavelet。
https://zhuanlan.zhihu.com/p/43715796,试试能不能用在文字识别上
特定领域的应用
1、深度图超分辨率
深度图记录了场景中视点和目标之间的距离,深度信息在姿态估计 [150], [151], [152]、语义分割 [153], [154] 等许多任务中发挥着重要作用。然而,由于生产力和成本方面的限制,由深度传感器生成的深度图通常分辨率较低,并饱受噪声、量化、缺失值等方面的降级影响。为了提高深度图的空间分辨率,研究人员引入了超分辨率。
2、人脸图像超分辨率
人脸图像超分辨率(又名 face hallucination,FH)通常有助于完成其它与人脸相关的任务 [6], [72], [73], [162]。与一般图像相比,人脸图像拥有更多与人脸相关的结构化信息,因此将人脸先验知识整合到 FH 中是一种非常流行且颇有前景的方法。
3、超光谱图像超分辨率
与全色图像(panchromatic image,PAN)相比,超光谱图像(HSI)包含数百个波段的高光谱图像,能够提供丰富的光谱特征,帮助完成许多视觉任务 [174], [175], [176], [177]。然而,由于硬件限制,不仅是搜集高质量 HSI 比搜集 PAN 难度更大,搜集到的 HSI 分辨率也要更低。因此,该领域引入了超分辨率,研究人员往往将 HR PAN 与 LR HSI 相结合来预测 HR HSI。
4、视频超分辨率
在视频超分辨率中,多个帧可以提供更多的场景信息,该领域不仅有帧内空间依赖,还有帧间时间依赖(如运动、亮度和颜色变化)。因此,现有研究主要关注更好地利用时空依赖,包括明确的运动补偿(如光流算法、基于学习的方法)和循环方法等。
5、其它应用
基于深度学习的超分辨率也被应用到其它特定领域的应用中,而且表现出色。尤其是,RACNN[197] 利用 SR 模型增强了用于细粒度分类的 LR 图像细节的可辨性。类似地,感知 GAN[198] 通过超分辨小目标的表征解决了小目标检测问题,实现了与大目标相似的特征,检测更具可辨性。FSR-GAN[199] 超分辨化了特征空间而非像素空间中的小图像,将质量较差的原始特征转换成了可辨性更高的特征,这对图像检索非常有利。此外,Dai 等人 [7] 验证了 SR 技术在若干视觉应用中的有效性和有用性,包括边缘检测、语义分割、数字和场景识别。Huang 等人 [200] 开发了专门用于超分辨率遥感图像的 RS-DRL。Jeon 等人 [201] 利用立体图像中的视差先验来重建配准中具有亚像素准确率的 HR 图像。
参考:
https://wangxuehui.site/article/a-survey-SR/
https://zhuanlan.zhihu.com/p/57564211