一些吴恩达深度学习教程笔记
下降法
1.梯度下降算法
2.动量(Momentum)梯度下降法
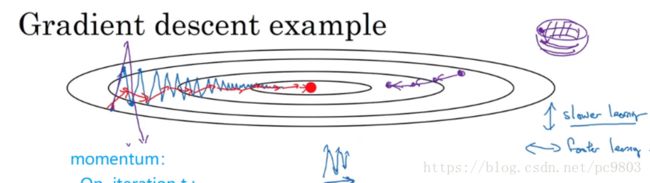
向着最小点的方向加速,与这个方向垂直方向减速

v=β∗v+(1−β)∗v=β∗v+(1−β)∗数据 t
β越小,就越关注当前数据,也就是曲线的细节
动量梯度下降法,就是在原来的梯度下降法上面改动,把参数w和b的更新参考值选为Vw而不是原来的dw,也就是选择速度。这个速度是由上一个速度以及当前的dw一起组成的,当然了还有参数β,这个值通常选择0.9(鲁棒性最好)。有些版本中去除了1-β,只保留dw。动量梯度下降法相当于求平均速度,垂直方向的速度存在的不确定性,可能上下摆动,经过平均之后,相互抵消了很多,整体值接近于0,而平行方向则多数指向于coast 最小值,平均之后影响不大。
直观来说,就是每次迭代的步幅会根据当前cost位置而调整,即当dw小的时候,迭代步幅会相应的减小。
3.RMSprop (root mean square prop),也可以加速梯度下降.均方根
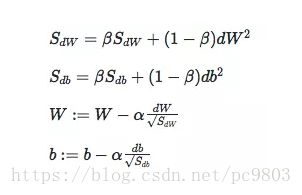
梯度除以平均之后的S,假设是垂直方向的速度很大,那相除之后速度会变小,假设水平方向的变化量很小,相除之后会变大。就可以控制住速度以及方向了。其中的权重参数数β通常设置为0.9999,为了防止出现除以0的情况,通常S会加上一个很小的值,例如ε=10−8。
4.Adam下降法

动量梯度下降法 和 均方根下降法,的结合,采用均方根的形式和s,把均方根的dw变为Vw。
问题:
vdW是不是dw维的矩阵,值是不是相等的
dw是不是w那样维数的矩阵,值是不是统一相等的
学习率衰减

局部最优问题
实际的高维运算中, 很难出现最低点重合的情况的
超参数调试
为超参数选择合适的范围
1.Scale均匀随机,一定的合适范围内随机选取
2.指数式的随机选取,例如从0.0001到1之间的选取,要按指数式随机选取
超参数调试实践–Pandas vs. Caviar

- 在计算资源有限的情况下,使用第一种,仅调试一个模型,每天不断优化;
- 在计算资源充足的情况下,使用第二种,同时并行调试多个模型,选取其中最好的模型。
网络中激活值的归一化
Batch Norm 的实现
就是将激活函数之前的z进行归一化处理,把z减去均值,再除以方差,进行除法的时候加上极小值ε避免被除数为0的情况,保证网络稳定,得到均值为0,方差为1的z值矩阵,为了保证z值矩阵不总是如此分布,则加上z等于z乘以阿发加上β。
Batch Norm 起作用的原因:
1.相当于改善了Cost function的形状,使得神经网络训练加快
2.对每一层的输出进行了一定的限制,使得在反向传播的过程中不至于出现梯度消失或者梯度爆炸,使得网络可以更深。
3.Batch Norm还有轻微的正则化效果,因为在每个批次的训练过程中,计算均值与方差的是某批数据,而不是全部训练集,因此计算出来的均值和方差不一定与整体的均值方差接近,因此会bn处理之后会引入了一点点噪声,就类似于做了一下正则化处理那样,还有一个细节就是,处理批次数量大的话,方差均值啥的就会更接近于整体的,因此噪声会更小一些。
CNN流程
1.图像去均值,减去均值zero-center(一般乘1/255);图像归一化normalized:mean/std,除以方差;不进行pca(斜的变成直的)和白化(就是归一化)
2.进行数据集的洗牌处理shuffle
3.Dropout,防止过拟合
CNN网络优化:
Mini-batch;正则化;Dropout;输入归一化;Batch Normalization
CNN算法优化:
Mini-batch梯度下降;Momentum、RMSprop、Adam优化算法;衰减学习率;
=================================
正交化:
正交化或者正交性,是系统设计的一种属性,使得系统部分算法改动时不会影响到另外的部分,或者副作用传播到其他部分,系统各部分可以相互独立的进行测试改动,加快开发周期。
==========================================
单一数字评估指标:
就是 用但一个标准来评价一个模型,为了模型的好坏更直观也为了更容易调整模型;例如判断是否为猫的例子,有查准率和查全率,查准率代表选出的全部的号称是猫的照片中,实际上是有多少真的是猫;查全率是在测试集合所有的猫的照片之中有多少真的被选出来了。在模型处理的时候,可以使用f1 score来评价这个模型,也就是两者的平均值。再例如,若干个判别模型,在不同的国家里面的准确率个有不同,选定各个模型的平均准确率为单一指标。
===================================================
满足和优化指标:
必须先达到满足的指标,然后选择最优化
=======================================================================
减少可避免偏差
训练更大的模型
训练更长时间、训练更好的优化算法(Momentum、RMSprop、Adam)
寻找更好的网络架构(RNN、CNN)、寻找更好的超参数
减少方差
收集更多的数据
正则化(L2、dropout、数据增强)
寻找更好的网络架构(RNN、CNN)、寻找更好的超参数
迁移学习有意义的情况:
任务a与任务b有相同的输入
任务a说具有的数据量远大于任务b所具有的数据量
任务a存在任务b所能利用的特征
卷积操作之后的宽度:

数据扩充的方法:
镜像翻转(Mirroring);
随机剪裁(Random Cropping);
色彩转换(Color shifting):
为图片的RGB三个色彩通道进行增减值,如(R:+20,G:-20,B:+20);PCA颜色增强:对图片的主色的变化较大,图片的次色变化较小,使总体的颜色保持一致。
风格转换中的Gram 矩阵:同一张图片的L层激活值,自己的两个通道进行两个图的点乘,这就组成了一张新的图,理论上需要全部的该层的通道进行同样的相互操作,就形成了K*K个通道的矩阵。S图和G图的gram矩阵点对点相减,就是风格损失函数了。