集成方法之快照集成(Snapshot Ensembling)
论文:
SNAPSHOT ENSEMBLES: TRAIN 1, GET M FOR FREE
Github:
https://github.com/gaohuang/SnapshotEnsemble
https://tiny-imagenet.herokuapp.com
一作是denseNet作者,康奈尔大学的黄高。
论文基于cos循环的学习策略,提出了快照集成(snapshot ensembles),只需要一次训练就可以得到收敛于多个不同最小值处的模型,从而进行模型集成。使用集成模型相比单模型可以获得更大的准确性。在CIFAR-10 上错误率为3.4%,在CIFAR-100 上错误率为17.4%。
SNAPSHOT ENSEMBLING :
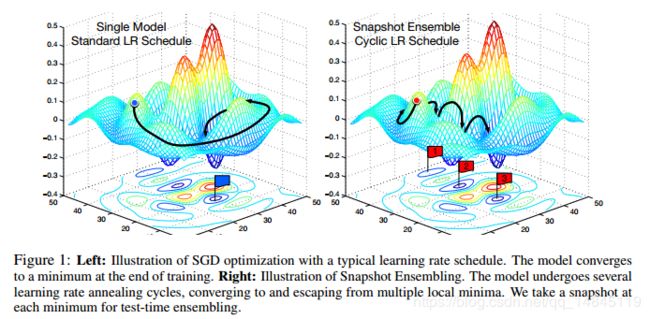
左图为使用传统的学习率不断下降的学习策略。
右图为使用cos方式的学习率不断循环下降,上升的策略。可以看出该方式可以收敛到多个全局最小值。从而可以使用这些模型进行集成学习。
使用传统学习率训练的单个模型,模型精度可能会比使用cos方式训练的每个模型的精度都略高。但是cos方式的模型进行集成后,效果会优于传统方式训练的单个模型。
使用Snapshot Ensembling得到的多个模型具有下面2个性质:
- 每个模型都有比较低的错误率
- 模型两两之间对识别错误的例子没有交集
基于这2个性质就可以进行模型集成。
![]()
Cyclic Cosine Annealing :
![]()
t:迭代的次数
T:一共的训练次数
f:cos方式的循环递减函数
M:循环的cycle次数
其中,初始学习率为a=f(0),最终学习率为a= f(T/M)
实验中将f定义为cos形式的函数
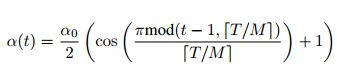
a0:初始学习率

TensorFlow函数:
tf.train.cosine_decay(
learning_rate,
global_step,
decay_steps,
alpha=0.0,
name=None
)具体实现:
def cosine_decay_with_warmup(global_step,
learning_rate_base,
total_steps,
warmup_learning_rate=0.0,
warmup_steps=0,
hold_base_rate_steps=0):
"""Cosine decay schedule with warm up period.
Cosine annealing learning rate as described in:
Loshchilov and Hutter, SGDR: Stochastic Gradient Descent with Warm Restarts.
ICLR 2017. https://arxiv.org/abs/1608.03983
In this schedule, the learning rate grows linearly from warmup_learning_rate
to learning_rate_base for warmup_steps, then transitions to a cosine decay
schedule.
Args:
global_step: int64 (scalar) tensor representing global step.
learning_rate_base: base learning rate.
total_steps: total number of training steps.
warmup_learning_rate: initial learning rate for warm up.
warmup_steps: number of warmup steps.
hold_base_rate_steps: Optional number of steps to hold base learning rate
before decaying.
Returns:
a (scalar) float tensor representing learning rate.
Raises:
ValueError: if warmup_learning_rate is larger than learning_rate_base,
or if warmup_steps is larger than total_steps.
"""
if total_steps < warmup_steps:
raise ValueError('total_steps must be larger or equal to '
'warmup_steps.')
learning_rate = 0.5 * learning_rate_base * (1 + tf.cos(
np.pi *
(tf.cast(global_step, tf.float32) - warmup_steps - hold_base_rate_steps
) / float(total_steps - warmup_steps - hold_base_rate_steps)))
if hold_base_rate_steps > 0:
learning_rate = tf.where(global_step > warmup_steps + hold_base_rate_steps,
learning_rate, learning_rate_base)
if warmup_steps > 0:
if learning_rate_base < warmup_learning_rate:
raise ValueError('learning_rate_base must be larger or equal to '
'warmup_learning_rate.')
slope = (learning_rate_base - warmup_learning_rate) / warmup_steps
warmup_rate = slope * tf.cast(global_step,
tf.float32) + warmup_learning_rate
learning_rate = tf.where(global_step < warmup_steps, warmup_rate,
learning_rate)
return tf.where(global_step > total_steps, 0.0, learning_rate,
name='learning_rate')
实验结果:
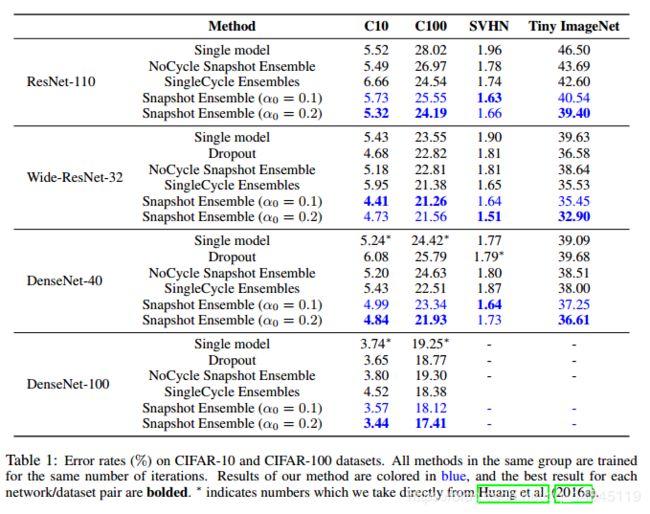
Snapshot Ensembling和不同方式训练的模型集成对比:
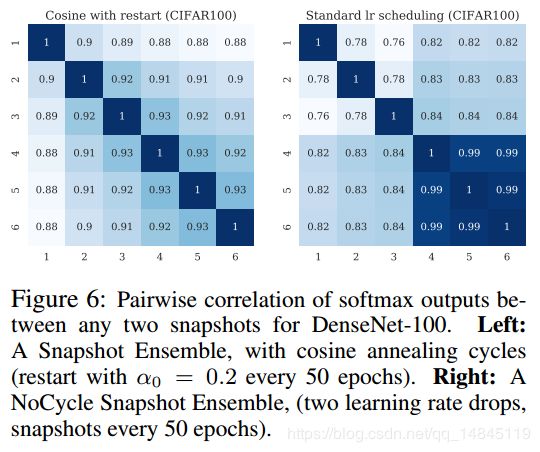
总结:
Kaggle比赛中经常使用的模型集成方法