[调研] 通用实例分割方法
目前的实例分割方法可分为3类:
- top-down,也叫做 detect-then-segment,顾名思义,先检测后分割,如FCIS, Mask-RCNN, PANet, Mask Scoring R-CNN;
- bottom-up,也叫Embedding-cluster,将每个实例看成一个类别;然后按照聚类的思路,最大类间距,最小类内距,对每个像素做embedding,最后做grouping分出不同的instance。Grouping的方法:learned associative embedding,A discriminative loss function,SGN,SSAP. 一般bottom-up效果差于top-down;
- direct的方法。不同与上述两类方法,直接得到实例分割结果,如SOLO。
目录
- Deep Snake for Real-Time Instance Segmentation [2001]
- PointRend: Image Segmentation as Rendering [1912]
- SOLO: Segmenting Objects by Locations [1912]
- FCOS: Fully Convolutional One-Stage Object Detection [1904]
- TensorMask: A Foundation for Dense Object Segmentation [1903]
- Hybrid Task Cascade for Instance Segmentation [1901]
- Path Aggregation Network for Instance Segmentation [1803]
- Mask R-CNN [1703]
- Fully Convolutional Instance-aware Semantic Segmentation [1611]
- Deep Watershed Transform for Instance Segmentation [1611]
- InstanceCut: from Edges to Instances with MultiCut [1611]
- Instance-sensitive Fully Convolutional Networks [1603]
- SGN: Sequential Grouping Networks for Instance Segmentation [16XX]
Deep Snake for Real-Time Instance Segmentation [2001]
物体轮廓用循环卷积来学习特征确定offset
文章提出two-stage、real-time的instance segmentation方法:1、得到初始的目标轮廓;2、轮廓迭代变形,以得到最终精准的目标边界;
不同于CornerNet、ExtremeNet等方法直接回归目标边界上的点,受到传统snake算法的启发,Deep Snake 通过迭代变形一个初始轮廓来得到最终的目标边界;文章使用循环卷积来学习目标轮廓的结构特征;对512x512大小的图片在1080Ti上达到32.3 fps
![[调研] 通用实例分割方法_第1张图片](http://img.e-com-net.com/image/info8/1184968dd11a41c58d04af7b3c24fef3.jpg)
![[调研] 通用实例分割方法_第2张图片](http://img.e-com-net.com/image/info8/4973161ddf4b49b18788e4865213c227.jpg)
先得到检测框,再得到diamond框,学习offset得到四个极点,得到octagon 轮廓; 输入到 deep snake,学习边缘;
![[调研] 通用实例分割方法_第3张图片](http://img.e-com-net.com/image/info8/70cb53d9f8f149ab91b4c49a2c3d050f.jpg)
![[调研] 通用实例分割方法_第4张图片](http://img.e-com-net.com/image/info8/61ca622a58e74e23b18c2bd2c6849f59.jpg)
![[调研] 通用实例分割方法_第5张图片](http://img.e-com-net.com/image/info8/da45a574734f4e7da3fbda58cce2682b.jpg)
PointRend: Image Segmentation as Rendering [1912]
![[调研] 通用实例分割方法_第6张图片](http://img.e-com-net.com/image/info8/4df4249783c74ee4bc8739127eb1f312.jpg)
方法:对输出的coarse mask 和 fine-grained 特征选部分点进行学习,用提出的subdivision mask rendering算法迭代,得到不确定边界区域的mask
Render方法:subdivision 、adaptive sampling、 ray-tracing
Subdivision: 只在(与周围区域十分不同的)区域计算;其他区域直接插值;
如何选点:将coarse mask 上采样X2;选择p接近0.5的N个点;用MLP得到这N个点预测值;一直迭代,直到到达某一分辨率;
![[调研] 通用实例分割方法_第7张图片](http://img.e-com-net.com/image/info8/a214bb854d9b44048d325420c8187396.jpg)
但训练阶段,不采用迭代的方式训练;而是使用随机采样
![[调研] 通用实例分割方法_第8张图片](http://img.e-com-net.com/image/info8/1eb0969580244da19010b56884790bc2.jpg)
![[调研] 通用实例分割方法_第9张图片](http://img.e-com-net.com/image/info8/4dd7d62d0ee44599b9ea194a9f6964f0.jpg)
SOLO: Segmenting Objects by Locations [1912]
现有方法分为两类:
top-down,也叫做 detect-then-segment,顾名思义,先检测后分割,如FCIS, Mask-RCNN, PANet, Mask Scoring R-CNN、TensorMask
bottom-up,也叫Embedding-cluster,将每个实例看成一个类别;然后按照聚类的思路,最大类间距,最小类内距,对每个像素做embedding,最后做grouping分出不同的instance。Grouping的方法:learned associative embedding,A discriminative loss function,SGN,SSAP. 一般bottom-up效果差于top-down。
但这些方法是two-step而且indirect。我们思考12,不同的instance的真正区别是什么,我们的答案是 location 和 object size。
Location:将图像分成S*S个cell,就形成了S^2个location类别;网络输出的一个channel就代表了一个location类别;相应的这个channel map就输出属于这个location类别的instance。
将每个像素分类到不同的location class,等价于对每个像素的中心位置做回归;相比起回归;用分类来做对位置预测的任务,更加直观,且用固定的channel能预测不同数量的instance。且不需要grouping或者embedding的后处理。
Size:FPN做不同大小的类别,不同的level预测不同的大小
![[调研] 通用实例分割方法_第10张图片](http://img.e-com-net.com/image/info8/783e0223ebf04d8cb29fa249da9b0e9e.jpg)
传统卷积是spatial invariant,但这里需要position sensitive.受CoordConv启发,直接把归一化坐标信息与特征拼接(简单易行)。
最后接NMS后输出实例分割结果。
FPN-backbone + prediction head –{ semantic category
---------------------------------------------- { instance mask
![[调研] 通用实例分割方法_第11张图片](http://img.e-com-net.com/image/info8/eb14b87ece8c4011a41496bc0e491999.jpg)
为验证方法有效性,选择了不同backbone+head+loss来进行试验。
标签赋值:Center sampling (在FCOS2019, Beyond anchor-based中都有使用)
中心区域定义:(cx, cy, εw, εh) ,ε=0.2,平均有3个positive sample
损失函数:category的focal 分类损失+ mask的分割损失(DICE)
在MS-COCO上与其他方法对比结果:
![[调研] 通用实例分割方法_第12张图片](http://img.e-com-net.com/image/info8/f33638908a084d4897e4369ce3ac5a19.jpg)
用FPN比直接设置grid num效果好很多✅
![[调研] 通用实例分割方法_第13张图片](http://img.e-com-net.com/image/info8/0f5998d82a41466083a1a429f496c7f5.jpg)
FPN各level的grid num
![[调研] 通用实例分割方法_第14张图片](http://img.e-com-net.com/image/info8/03d3146715ac4084bc2e5a0524c34aea.jpg)
COORDCONV作用:
![[调研] 通用实例分割方法_第15张图片](http://img.e-com-net.com/image/info8/cbc5bb8b847e462785d291c16690ac98.jpg)
Decoupled方法
![[调研] 通用实例分割方法_第16张图片](http://img.e-com-net.com/image/info8/cfe78d71752a4380b972bfc3a183feee.jpg)
GPU显存更少
![[调研] 通用实例分割方法_第17张图片](http://img.e-com-net.com/image/info8/f1efa41231d44a71b85b3428263b0691.jpg)
速度:
SOLO – RESNET-50 Speed 12FPS ON V100
FCOS: Fully Convolutional One-Stage Object Detection [1904]
Method:不预测检测框;而是直接预测点距离四个边的距离
![[调研] 通用实例分割方法_第18张图片](http://img.e-com-net.com/image/info8/3c9150398e184b1ca507332e14212436.jpg)
Centerness:一个branch抑制离中心点远的低质量proposal;训练时,计算;(l,t,r,b)为该点距离四个边的距离;不同level使用同一head对性能不太好,添加一个可学习的参数s用于回归,使得性能略微上升
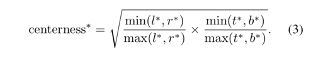
CE作为loss;测试时,nms抑制低的得分。
同一点对应不同目标,可以用FPN解决;不同level预测不同scale
![[调研] 通用实例分割方法_第19张图片](http://img.e-com-net.com/image/info8/4d554972ccb24837b339b37656e95f3c.jpg)
![[调研] 通用实例分割方法_第20张图片](http://img.e-com-net.com/image/info8/766778bf02e84df49002aa6e4a1bde7f.jpg)
TensorMask: A Foundation for Dense Object Segmentation [1903]
滑动窗目标检测;dense sliding-window instance segmentation network
利用滑窗来寻找物体,是CV中古老又传统的方法。
Insight:
Faster-rcnn、mask-rcnn都是用滑窗检测出候选框,再用refinement net来进一步挑选;
SSD和RetinaNet舍弃了refinement,直接用滑窗得到检测结果。然而目前这类方法没有拓展到instance 分割上。本文即填补这个gap
方法:
定义 nature representation 与 aligned representation
![[调研] 通用实例分割方法_第21张图片](http://img.e-com-net.com/image/info8/c332057bc1994277a925088dc68b8d98.jpg)
方法总结:精度比不过mask rcnn,而且还慢3倍;
Hybrid Task Cascade for Instance Segmentation [1901]
Insight:充分利用detection与segmentation的相互(reciprocal)关系设计级联方式
现有方法粗略分为两类:
detection-based:detector先产生bbox或region proposal,再在区域内预测mask;
segmentation-based:
method:
交织进行bbox 回归与mask预测,而非并行
Mask brainch,上阶段信息直接输入到当前;
加入了额外的语义分割branch,并融入到bbox与mask branch中
这些改进改善了stage以及task的信息流
![[调研] 通用实例分割方法_第22张图片](http://img.e-com-net.com/image/info8/467d95b3372142c890fc5461b2e4662f.jpg)
速度、性能比较:
![[调研] 通用实例分割方法_第23张图片](http://img.e-com-net.com/image/info8/9d183be2a6dc4ed9b6d2e2e4db094745.jpg)
CASCADE R-CNN: iou=0.5 ,FP多,iou升高,性能下降;原因:1、由于指数消失的正样本导致过拟合;2、训练与测试的mismatch(即在train上取得最佳的IOU阈值对inference时产生的proposal并不能很好地进行回归)
方法:级连不同iou的detector;iou逐渐升高;
![[调研] 通用实例分割方法_第24张图片](http://img.e-com-net.com/image/info8/55aa2e739f244363b84063eab3ede2ba.jpg)
![[调研] 通用实例分割方法_第25张图片](http://img.e-com-net.com/image/info8/64f353e03584488fa247620867bbc00a.jpg)
Path Aggregation Network for Instance Segmentation [1803]
PANET CVPR2018
关键词:information flow
1st place in the COCO 2017 Challenge Instance Segmentation task
Method:bottom-up path + adaptive feature pooling + mask branch中 添加了 fc;
![[调研] 通用实例分割方法_第26张图片](http://img.e-com-net.com/image/info8/e038c81a55264b4fbfeecaf18cbb1e7b.jpg)
![[调研] 通用实例分割方法_第27张图片](http://img.e-com-net.com/image/info8/e06febc61f7c483db107ec12e9d48131.jpg)
![[调研] 通用实例分割方法_第28张图片](http://img.e-com-net.com/image/info8/3ca8b4ba4400429a97fda955ca15e1bb.jpg)
Mask R-CNN [1703]
FPN + FPN + ROI Align + 3 branch (class, mask , box )
FCIS缺点:重叠instance、虚假边缘
![[调研] 通用实例分割方法_第29张图片](http://img.e-com-net.com/image/info8/5c62a9a054104351a1962e4e712658a7.jpg)
![[调研] 通用实例分割方法_第30张图片](http://img.e-com-net.com/image/info8/3d56c77d03c643e993bdfcbfd7a570c2.jpg)
![[调研] 通用实例分割方法_第31张图片](http://img.e-com-net.com/image/info8/afd30e6bc396445c82b735e2b977f023.jpg)
实验:cityscape + coco
![[调研] 通用实例分割方法_第32张图片](http://img.e-com-net.com/image/info8/1fc0e7faadcd475d92279a70ed0c30f9.jpg)
Fully Convolutional Instance-aware Semantic Segmentation [1611]
FCIS. : 首个端到端的实例分割网路;CVPR2017 spotlight
检测与分割同时进行. 用RPN代替sliding window。
此前的技术分为三步:1、FCN提取特征;2、将每个ROI pooling成相同尺寸的特征图;3、全连接层输出ROI mask。 注意:translation-variant在fc上引入。
缺点如下:1、ROIpooling损失空间细节;2、使用fc层参数量过多;3、最后一步每个ROI之间的计算不共享;
Method:
position-sensitive score map
joint mask prediction and classification
RPN得到的检测框,直接在score map上裁剪,特征图一半(inside)做softmax得到实例分割图;特征图另一半(outside)max + avg Pooling + softmax,判断是否为instance
inside score:像素在目标内 segment+
outside score:像素在目标外 segment-
![[调研] 通用实例分割方法_第33张图片](http://img.e-com-net.com/image/info8/bfe8150e0e414ba0860ec861be0a4891.jpg)
总共有3个loss, C+1类的检测loss,分割loss以及bbox的回归loss
实验:pascal+coco
Deep Watershed Transform for Instance Segmentation [1611]
需要好的语义分割图像(由PSPNet得到);
优点:适合学习相互连接的物体
缺点:遮挡、重叠;学不到实例类别;性能比mask-rcnn差很多
方法:网络学习分水岭变换;得到能量图,再根据能量图,直接得到每个实例:DN net (梯度图,单位向量,得到2维)+ WT net (能量图)
![[调研] 通用实例分割方法_第34张图片](http://img.e-com-net.com/image/info8/1fc3efccbe954e5d888723e1f26994d2.jpg)
![[调研] 通用实例分割方法_第35张图片](http://img.e-com-net.com/image/info8/b3661e2dec35494c92b475d48709aa04.jpg)
InstanceCut: from Edges to Instances with MultiCut [1611]
方法:输出语义分割图+所有instance的边界— 之后用MultiCut来分割最终的instance; instance-aware;
ituition : Semantic seg 的中间特征可以用来 学习edge
数据:cityscape,8个类别;2975 images for training, 500 for validation and 1525 for testing
![[调研] 通用实例分割方法_第36张图片](http://img.e-com-net.com/image/info8/612a0418d98c4f449bf78ab03b017510.jpg)
![[调研] 通用实例分割方法_第37张图片](http://img.e-com-net.com/image/info8/8efcfaf377f64399852a86cdda633dfb.jpg)
Instance-sensitive Fully Convolutional Networks [1603]
ECCV2016
优点:普通卷积有平移不变形,同一位置,响应总是一样,这阻碍了实例分割;为此文章引入instance-sensitive score map,同一个像素,因为相对位置发生了变化,选择了不同的score map的值,因此有了translation-variant。
缺点:1、非端到端的实例分割;因为无法判断instance分割的语义类别;2、 固定的224大小滑窗+ image pyramid scanning,十分耗费时间;
细节:测试训练都使用多尺度
基于像素的相对位置来进行分类,从而产生一些instance-sensitive的score map,后续通过一个简单的assembling module来得到最终的instance分割结果
![[调研] 通用实例分割方法_第38张图片](http://img.e-com-net.com/image/info8/cde806419fa84006a61d2997c403b3a3.jpg)
![[调研] 通用实例分割方法_第39张图片](http://img.e-com-net.com/image/info8/295ee1027abc4fb896fb6be132beb873.jpg)
具体实现上,特征提取使用VGG16网络,输出特征(H/8,W/8);第一个分支,经过两个卷积,先输出K^2个score map (K=5),用mXm的滑动窗用assemble 得到instance,再从得到的instance里面随机抽样256个,这些instance 和instance的分割gt计算loss;
第二个分支,预测分支一得到256个instance是真正的instance 的概率,计算loss;
![]()
![[调研] 通用实例分割方法_第40张图片](http://img.e-com-net.com/image/info8/29415529482d4e8db06a79c125c5fb94.jpg)
测试阶段:
对分支一上sliding window得到的instance score map,先二值化,再用分支二的概率以及instance的box的iou来做NMS,最后选择top-N作为最终结果。
预处理上,scale jittering在多篇文章中大量运用;
SGN: Sequential Grouping Networks for Instance Segmentation [16XX]
ICCV17 ; 内容过于繁琐,且无开源代码
Insight:点成线;线成面
Method:一串子网络逐渐完成任务;
子网络1:水平以及垂直预测breakpoints;产生线的分割
子网络2:将线分割连成 联通的区域; 将对pixel的分类 降维成 对 线的分类;RNN网络 LineNet(很小);输入为9个通道
子网络3:连通区域形成最后instance; MergerNet(很小)
![[调研] 通用实例分割方法_第41张图片](http://img.e-com-net.com/image/info8/2831993bf4034519b754712f77baea48.jpg)
1、每个像素额外标注成background,interior,starting point,termination point
2、水平、垂直两个方向成线
![[调研] 通用实例分割方法_第42张图片](http://img.e-com-net.com/image/info8/ad6abdce87034e1cbfeddfa04f6963b8.jpg)