[ECCV2018] [MUNIT] Multimodal Unsupervised Image-to-Image Translation
贡献:为 one-to-one 的unpaired image translation 的生成图像提供多样性
提出假设:1、图像可以分解为style code 与 content code;2、不同领域的图像,共享一个content space,但是属于不同的style space;
style code captures domain-specific properties, and content code is domain-invariant. we refer to “content” as the underling spatial structure and “style” as the rendering of the structure
本文基于上述假设,使用c (content code)与s (style code)来表征图像进行图像转换任务。
![[ECCV2018] [MUNIT] Multimodal Unsupervised Image-to-Image Translation_第1张图片](http://img.e-com-net.com/image/info8/d78769c4f6ad4476a310064450fd5cdf.jpg)
related works
1、style transfer分为两类:example-guided style transfer 与collection style transfer (cyclegan)
2、Learning disentangled representations:InfoGAN and β-VAE
Model
模型训练流程图:
![[ECCV2018] [MUNIT] Multimodal Unsupervised Image-to-Image Translation_第2张图片](http://img.e-com-net.com/image/info8/b237092834084a74a8624ee5d916f0e6.jpg)
生成器模型:由两个encoder+MLP+decoder组成
![[ECCV2018] [MUNIT] Multimodal Unsupervised Image-to-Image Translation_第3张图片](http://img.e-com-net.com/image/info8/34c7100df5b043d58284de350a8c54e5.jpg)
损失函数
Bidirectional reconstruction loss
Image reconstruction
![]()
Latent reconstruction
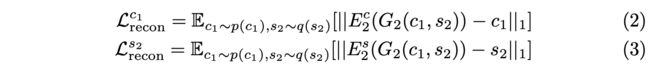
Adversarial loss
![]()
Total loss

Domain-invariant perceptual loss(补充)
可选择使用的一个损失:
传统的perceptual loss即使用两幅图像的VGG特征差异作为距离损失;这里提出的损失的改进即对特征进行了IN层归一化,去除原始特征的均值方差(为domain-specific信息),用于计算损失的两幅图像是真实图像与合成图像(同一content不同style)
实验发现,用了IN改进,same scene 的距离会小于同一domain的图像。
![[ECCV2018] [MUNIT] Multimodal Unsupervised Image-to-Image Translation_第4张图片](http://img.e-com-net.com/image/info8/41419ac39b5a41bda76271987f8f2f53.jpg)
作者发现图像大小大于512时,该损失能加速训练。。。(感觉没什么用 )
评价指标与结果
LPIPS衡量多样性;Human performance score 衡量合成质量; CIS(IS改进版本)
![[ECCV2018] [MUNIT] Multimodal Unsupervised Image-to-Image Translation_第5张图片](http://img.e-com-net.com/image/info8/e143c8d5051442bb8316259e0fab7942.jpg)
![[ECCV2018] [MUNIT] Multimodal Unsupervised Image-to-Image Translation_第6张图片](http://img.e-com-net.com/image/info8/b418a64dd08944e5b50fa47e5d8762fa.jpg)
代码笔记
训练时,主代码部分
# Start training
iterations = trainer.resume(checkpoint_directory, hyperparameters=config) if opts.resume else 0
while True:
for it, (images_a, images_b) in enumerate(zip(train_loader_a, train_loader_b)):
trainer.update_learning_rate()
images_a, images_b = images_a.cuda().detach(), images_b.cuda().detach()
with Timer("Elapsed time in update: %f"):
# Main training code
trainer.dis_update(images_a, images_b, config)
trainer.gen_update(images_a, images_b, config)
torch.cuda.synchronize()
# Dump training stats in log file
if (iterations + 1) % config['log_iter'] == 0:
print("Iteration: %08d/%08d" % (iterations + 1, max_iter))
write_loss(iterations, trainer, train_writer)
# Write images
if (iterations + 1) % config['image_save_iter'] == 0:
with torch.no_grad():
test_image_outputs = trainer.sample(test_display_images_a, test_display_images_b)
train_image_outputs = trainer.sample(train_display_images_a, train_display_images_b)
write_2images(test_image_outputs, display_size, image_directory, 'test_%08d' % (iterations + 1))
write_2images(train_image_outputs, display_size, image_directory, 'train_%08d' % (iterations + 1))
# HTML
write_html(output_directory + "/index.html", iterations + 1, config['image_save_iter'], 'images')
if (iterations + 1) % config['image_display_iter'] == 0:
with torch.no_grad():
image_outputs = trainer.sample(train_display_images_a, train_display_images_b)
write_2images(image_outputs, display_size, image_directory, 'train_current')
# Save network weights
if (iterations + 1) % config['snapshot_save_iter'] == 0:
trainer.save(checkpoint_directory, iterations)
iterations += 1
if iterations >= max_iter:
sys.exit('Finish training')
trainer为MUNIT_Trainer类对象,该类包含了MUNIT模型的几乎所有操作,包括各个网络的初始化,优化器定义,网络前馈、网络优化等。这个类会相对冗杂,好处就是训练的主函数就只需要调用update_D与update_G就完事了,算是一种训练代码的风格。另一种代码风格就是StarGAN、StarGAN v2的,各个网络单独定义,没有Trainer这种类,因此train的主函数会比较复杂。
1、该类的初始化定义如下:
class MUNIT_Trainer(nn.Module):
def __init__(self, hyperparameters):
super(MUNIT_Trainer, self).__init__()
lr = hyperparameters['lr']
# Initiate the networks
self.gen_a = AdaINGen(hyperparameters['input_dim_a'], hyperparameters['gen']) # auto-encoder for domain a
self.gen_b = AdaINGen(hyperparameters['input_dim_b'], hyperparameters['gen']) # auto-encoder for domain b
self.dis_a = MsImageDis(hyperparameters['input_dim_a'], hyperparameters['dis']) # discriminator for domain a
self.dis_b = MsImageDis(hyperparameters['input_dim_b'], hyperparameters['dis']) # discriminator for domain b
self.instancenorm = nn.InstanceNorm2d(512, affine=False)
self.style_dim = hyperparameters['gen']['style_dim']
# fix the noise used in sampling
display_size = int(hyperparameters['display_size'])
self.s_a = torch.randn(display_size, self.style_dim, 1, 1).cuda()
self.s_b = torch.randn(display_size, self.style_dim, 1, 1).cuda()
# Setup the optimizers
beta1 = hyperparameters['beta1']
beta2 = hyperparameters['beta2']
dis_params = list(self.dis_a.parameters()) + list(self.dis_b.parameters())
gen_params = list(self.gen_a.parameters()) + list(self.gen_b.parameters())
self.dis_opt = torch.optim.Adam([p for p in dis_params if p.requires_grad],
lr=lr, betas=(beta1, beta2), weight_decay=hyperparameters['weight_decay'])
self.gen_opt = torch.optim.Adam([p for p in gen_params if p.requires_grad],
lr=lr, betas=(beta1, beta2), weight_decay=hyperparameters['weight_decay'])
self.dis_scheduler = get_scheduler(self.dis_opt, hyperparameters)
self.gen_scheduler = get_scheduler(self.gen_opt, hyperparameters)
# Network weight initialization
self.apply(weights_init(hyperparameters['init']))
self.dis_a.apply(weights_init('gaussian'))
self.dis_b.apply(weights_init('gaussian'))
# Load VGG model if needed
if 'vgg_w' in hyperparameters.keys() and hyperparameters['vgg_w'] > 0:
self.vgg = load_vgg16(hyperparameters['vgg_model_path'] + '/models')
self.vgg.eval()
for param in self.vgg.parameters():
param.requires_grad = False
1.1 生成器AdaINGen的定义如下:
class AdaINGen(nn.Module):
# AdaIN auto-encoder architecture
def __init__(self, input_dim, params):
super(AdaINGen, self).__init__()
dim = params['dim']
style_dim = params['style_dim']
n_downsample = params['n_downsample']
n_res = params['n_res']
activ = params['activ']
pad_type = params['pad_type']
mlp_dim = params['mlp_dim']
# style encoder
self.enc_style = StyleEncoder(4, input_dim, dim, style_dim, norm='none', activ=activ, pad_type=pad_type)
# content encoder
self.enc_content = ContentEncoder(n_downsample, n_res, input_dim, dim, 'in', activ, pad_type=pad_type)
self.dec = Decoder(n_downsample, n_res, self.enc_content.output_dim, input_dim, res_norm='adain', activ=activ, pad_type=pad_type)
# MLP to generate AdaIN parameters
self.mlp = MLP(style_dim, self.get_num_adain_params(self.dec), mlp_dim, 3, norm='none', activ=activ)
def forward(self, images):
# reconstruct an image
content, style_fake = self.encode(images)
images_recon = self.decode(content, style_fake)
return images_recon
def encode(self, images):
# encode an image to its content and style codes
style_fake = self.enc_style(images)
content = self.enc_content(images)
return content, style_fake
def decode(self, content, style):
# decode content and style codes to an image
adain_params = self.mlp(style)
self.assign_adain_params(adain_params, self.dec)
images = self.dec(content)
return images
def assign_adain_params(self, adain_params, model):
# assign the adain_params to the AdaIN layers in model
for m in model.modules():
if m.__class__.__name__ == "AdaptiveInstanceNorm2d":
mean = adain_params[:, :m.num_features]
std = adain_params[:, m.num_features:2*m.num_features]
m.bias = mean.contiguous().view(-1)
m.weight = std.contiguous().view(-1)
if adain_params.size(1) > 2*m.num_features:
adain_params = adain_params[:, 2*m.num_features:]
def get_num_adain_params(self, model):
# return the number of AdaIN parameters needed by the model
num_adain_params = 0
for m in model.modules():
if m.__class__.__name__ == "AdaptiveInstanceNorm2d":
num_adain_params += 2*m.num_features
return num_adain_params
生成器是由两个Encoder(style encoder + content encoder)与一个Decoder组成。
1.1.1 StyleEncoder定义如下:
class Conv2dBlock(nn.Module):
def __init__(self, input_dim ,output_dim, kernel_size, stride,
padding=0, norm='none', activation='relu', pad_type='zero'):
super(Conv2dBlock, self).__init__()
self.use_bias = True
# initialize padding
if pad_type == 'reflect':
self.pad = nn.ReflectionPad2d(padding)
elif pad_type == 'replicate':
self.pad = nn.ReplicationPad2d(padding)
elif pad_type == 'zero':
self.pad = nn.ZeroPad2d(padding)
else:
assert 0, "Unsupported padding type: {}".format(pad_type)
# initialize normalization
norm_dim = output_dim
if norm == 'bn':
self.norm = nn.BatchNorm2d(norm_dim)
elif norm == 'in':
#self.norm = nn.InstanceNorm2d(norm_dim, track_running_stats=True)
self.norm = nn.InstanceNorm2d(norm_dim)
elif norm == 'ln':
self.norm = LayerNorm(norm_dim)
elif norm == 'adain':
self.norm = AdaptiveInstanceNorm2d(norm_dim)
elif norm == 'none' or norm == 'sn':
self.norm = None
else:
assert 0, "Unsupported normalization: {}".format(norm)
# initialize activation
if activation == 'relu':
self.activation = nn.ReLU(inplace=True)
elif activation == 'lrelu':
self.activation = nn.LeakyReLU(0.2, inplace=True)
elif activation == 'prelu':
self.activation = nn.PReLU()
elif activation == 'selu':
self.activation = nn.SELU(inplace=True)
elif activation == 'tanh':
self.activation = nn.Tanh()
elif activation == 'none':
self.activation = None
else:
assert 0, "Unsupported activation: {}".format(activation)
# initialize convolution
if norm == 'sn':
self.conv = SpectralNorm(nn.Conv2d(input_dim, output_dim, kernel_size, stride, bias=self.use_bias))
else:
self.conv = nn.Conv2d(input_dim, output_dim, kernel_size, stride, bias=self.use_bias)
def forward(self, x):
x = self.conv(self.pad(x))
if self.norm:
x = self.norm(x)
if self.activation:
x = self.activation(x)
return x
class StyleEncoder(nn.Module):
def __init__(self, n_downsample, input_dim, dim, style_dim, norm, activ, pad_type):
super(StyleEncoder, self).__init__()
self.model = []
self.model += [Conv2dBlock(input_dim, dim, 7, 1, 3, norm=norm, activation=activ, pad_type=pad_type)]
for i in range(2):
self.model += [Conv2dBlock(dim, 2 * dim, 4, 2, 1, norm=norm, activation=activ, pad_type=pad_type)]
dim *= 2
for i in range(n_downsample - 2):
self.model += [Conv2dBlock(dim, dim, 4, 2, 1, norm=norm, activation=activ, pad_type=pad_type)]
self.model += [nn.AdaptiveAvgPool2d(1)] # global average pooling
self.model += [nn.Conv2d(dim, style_dim, 1, 1, 0)]
self.model = nn.Sequential(*self.model)
self.output_dim = dim
def forward(self, x):
return self.model(x)
上面代码的Conv2dBlock给了最全的配置(padding层、归一化层以及激活层),可以留着以后直接套用。对edge2shoes任务(其具体参数可在edges2shoes_folder.yaml配置文件中查看,YAML文件,是YAML Ain’t a Markup Language的缩写,是专门用于写配置文件的语言,比json更方便),StyleEncoder为6层的全卷积网络,没有norm层,输入图像shape为(N,3,256,256),输出的style code 为(N,8,1,1)
1.1.2 ContentEncoder 定义如下
class ResBlocks(nn.Module):
def __init__(self, num_blocks, dim, norm='in', activation='relu', pad_type='zero'):
super(ResBlocks, self).__init__()
self.model = []
for i in range(num_blocks):
self.model += [ResBlock(dim, norm=norm, activation=activation, pad_type=pad_type)]
self.model = nn.Sequential(*self.model)
def forward(self, x):
return self.model(x)
class ResBlock(nn.Module):
def __init__(self, dim, norm='in', activation='relu', pad_type='zero'):
super(ResBlock, self).__init__()
model = []
model += [Conv2dBlock(dim ,dim, 3, 1, 1, norm=norm, activation=activation, pad_type=pad_type)]
model += [Conv2dBlock(dim ,dim, 3, 1, 1, norm=norm, activation='none', pad_type=pad_type)]
self.model = nn.Sequential(*model)
def forward(self, x):
residual = x
out = self.model(x)
out += residual
return out
class ContentEncoder(nn.Module):
def __init__(self, n_downsample, n_res, input_dim, dim, norm, activ, pad_type):
super(ContentEncoder, self).__init__()
self.model = []
self.model += [Conv2dBlock(input_dim, dim, 7, 1, 3, norm=norm, activation=activ, pad_type=pad_type)]
# downsampling blocks
for i in range(n_downsample):
self.model += [Conv2dBlock(dim, 2 * dim, 4, 2, 1, norm=norm, activation=activ, pad_type=pad_type)]
dim *= 2
# residual blocks
self.model += [ResBlocks(n_res, dim, norm=norm, activation=activ, pad_type=pad_type)]
self.model = nn.Sequential(*self.model)
self.output_dim = dim
def forward(self, x):
return self.model(x)
n_downsample为2,n_res为4,因此ContentEncoder有3个卷积层+4个resblock,norm层为InstanceNorm,输出content code的shape为(4, 256, 64, 64)
1.1.3 Decoder定义如下:
class Decoder(nn.Module):
def __init__(self, n_upsample, n_res, dim, output_dim, res_norm='adain', activ='relu', pad_type='zero'):
super(Decoder, self).__init__()
self.model = []
# AdaIN residual blocks
self.model += [ResBlocks(n_res, dim, res_norm, activ, pad_type=pad_type)]
# upsampling blocks
for i in range(n_upsample):
self.model += [nn.Upsample(scale_factor=2),
Conv2dBlock(dim, dim // 2, 5, 1, 2, norm='ln', activation=activ, pad_type=pad_type)]
dim //= 2
# use reflection padding in the last conv layer
self.model += [Conv2dBlock(dim, output_dim, 7, 1, 3, norm='none', activation='tanh', pad_type=pad_type)]
self.model = nn.Sequential(*self.model)
def forward(self, x):
return self.model(x)
Decoder包含4个resblock,AdaIN做norm层;后接两个上采样层,LN做norm层;最后接一个conv,tanh做激活层。输出为(N,3,256,256)
1.1.4 AdaptiveInstanceNorm2d公式如下:

函数定义如下:
class AdaptiveInstanceNorm2d(nn.Module):
def __init__(self, num_features, eps=1e-5, momentum=0.1):
super(AdaptiveInstanceNorm2d, self).__init__()
self.num_features = num_features
self.eps = eps
self.momentum = momentum
# weight and bias are dynamically assigned
self.weight = None
self.bias = None
# just dummy buffers, not used
self.register_buffer('running_mean', torch.zeros(num_features))
self.register_buffer('running_var', torch.ones(num_features))
def forward(self, x):
assert self.weight is not None and self.bias is not None, "Please assign weight and bias before calling AdaIN!"
b, c = x.size(0), x.size(1)
running_mean = self.running_mean.repeat(b)
running_var = self.running_var.repeat(b)
# Apply instance norm
x_reshaped = x.contiguous().view(1, b * c, *x.size()[2:])
out = F.batch_norm(
x_reshaped, running_mean, running_var, self.weight, self.bias,
True, self.momentum, self.eps)
return out.view(b, c, *x.size()[2:])
def __repr__(self):
return self.__class__.__name__ + '(' + str(self.num_features) + ')'
AdaIN的一种实现,另一种可见StarGAN v2。
Tensor.repeat():在指定维度上重复,是tensor数据的复制,示例如下:
>>> x = torch.tensor([1, 2, 3])
>>> x.repeat(4, 2)
tensor([[ 1, 2, 3, 1, 2, 3],
[ 1, 2, 3, 1, 2, 3],
[ 1, 2, 3, 1, 2, 3],
[ 1, 2, 3, 1, 2, 3]])
>>> x.repeat(4, 2, 1).size()
torch.Size([4, 2, 3])
另一个类似的函数为Tensor.expand():同样在维度上复制,但并不会分配新的内存。示例如下:
>>> x = torch.tensor([[1], [2], [3]])
>>> x.size()
torch.Size([3, 1])
>>> x.expand(3, 4)
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])
>>> x.expand(-1, 4) # -1 means not changing the size of that dimension
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])
Tensor.contiguous()以邻接内存的形式返回数据的拷贝(一般直接定义的tensor都是邻接的,经过reshape、permute、transpose、expand等操作后,内存会不相邻),因为torch.view需要处理连续的Tensor [参考1] [参考2]
F.batch_norm(),BN归一化的是Batch中所有样本每个channel的数据;IN归一化的是Batch中每个样本每个channel的数据,因此用如下语句将B的维度移到C上,即可用BN来实现IN:
# Apply instance norm
x_reshaped = x.contiguous().view(1, b * c, *x.size()[2:])
BN、IN、LN、GN的区别可见下图:
![[ECCV2018] [MUNIT] Multimodal Unsupervised Image-to-Image Translation_第7张图片](http://img.e-com-net.com/image/info8/55904bcff44848789bbf2c3d017ff867.jpg)
register_buffer(name,tensor)为nn.Module的函数,用于添加persistent buffer(如BN中的running_mean,它持续存在着,但并非模型参数)def __repr__(),显示对象,即它定义着print输出的内容,用于调试开发;与此类似的是def __str__()用于用户端输出- 可以看到
AdaptiveInstanceNorm2d的参数weight与bias是未定义的,是AdaINGen.assign_adain_params()通过MLP将style code分解后,为这两个参数动态赋值,具体即一半的维度赋给weight,一半的维度赋给bias.
1.1.5 MLP定义如下,用于将style code 转换成 weight , bias 参数:
class LinearBlock(nn.Module):
def __init__(self, input_dim, output_dim, norm='none', activation='relu'):
super(LinearBlock, self).__init__()
use_bias = True
# initialize fully connected layer
if norm == 'sn':
self.fc = SpectralNorm(nn.Linear(input_dim, output_dim, bias=use_bias))
else:
self.fc = nn.Linear(input_dim, output_dim, bias=use_bias)
# initialize normalization
norm_dim = output_dim
if norm == 'bn':
self.norm = nn.BatchNorm1d(norm_dim)
elif norm == 'in':
self.norm = nn.InstanceNorm1d(norm_dim)
elif norm == 'ln':
self.norm = LayerNorm(norm_dim)
elif norm == 'none' or norm == 'sn':
self.norm = None
else:
assert 0, "Unsupported normalization: {}".format(norm)
# initialize activation
if activation == 'relu':
self.activation = nn.ReLU(inplace=True)
elif activation == 'lrelu':
self.activation = nn.LeakyReLU(0.2, inplace=True)
elif activation == 'prelu':
self.activation = nn.PReLU()
elif activation == 'selu':
self.activation = nn.SELU(inplace=True)
elif activation == 'tanh':
self.activation = nn.Tanh()
elif activation == 'none':
self.activation = None
else:
assert 0, "Unsupported activation: {}".format(activation)
def forward(self, x):
out = self.fc(x)
if self.norm:
out = self.norm(out)
if self.activation:
out = self.activation(out)
return out
class MLP(nn.Module):
def __init__(self, input_dim, output_dim, dim, n_blk, norm='none', activ='relu'):
super(MLP, self).__init__()
self.model = []
self.model += [LinearBlock(input_dim, dim, norm=norm, activation=activ)]
for i in range(n_blk - 2):
self.model += [LinearBlock(dim, dim, norm=norm, activation=activ)]
self.model += [LinearBlock(dim, output_dim, norm='none', activation='none')] # no output activations
self.model = nn.Sequential(*self.model)
def forward(self, x):
return self.model(x.view(x.size(0), -1))
具体调用时,语句如下:
# MLP to generate AdaIN parameters
self.mlp = MLP(style_dim, self.get_num_adain_params(self.dec), mlp_dim, 3, norm='none', activ=activ)
这里self.get_num_adain_params()计算decoder中所有Adain层的参数总量,然后作为MLP的输出维度。注意,style code输入到MLP中,一次就得到了decoder中所有Adain层的参数。 因此在assign_adain_params()赋值时,是依次对每个Adain层进行了赋值。也因此函数中会有如下语句,每次赋完一层的值后,对adain_params去掉用过的值。
# 参数weight 与bias 维度都是 num_features
if adain_params.size(1) > 2*m.num_features:
adain_params = adain_params[:, 2*m.num_features:]
1.2 鉴别器MsImageDis()定义如下:
class MsImageDis(nn.Module):
# Multi-scale discriminator architecture
def __init__(self, input_dim, params):
super(MsImageDis, self).__init__()
self.n_layer = params['n_layer']
self.gan_type = params['gan_type']
self.dim = params['dim']
self.norm = params['norm']
self.activ = params['activ']
self.num_scales = params['num_scales']
self.pad_type = params['pad_type']
self.input_dim = input_dim
self.downsample = nn.AvgPool2d(3, stride=2, padding=[1, 1], count_include_pad=False)
self.cnns = nn.ModuleList()
for _ in range(self.num_scales):
self.cnns.append(self._make_net())
def _make_net(self):
dim = self.dim
cnn_x = []
cnn_x += [Conv2dBlock(self.input_dim, dim, 4, 2, 1, norm='none', activation=self.activ, pad_type=self.pad_type)]
for i in range(self.n_layer - 1):
cnn_x += [Conv2dBlock(dim, dim * 2, 4, 2, 1, norm=self.norm, activation=self.activ, pad_type=self.pad_type)]
dim *= 2
cnn_x += [nn.Conv2d(dim, 1, 1, 1, 0)]
cnn_x = nn.Sequential(*cnn_x)
return cnn_x
def forward(self, x):
outputs = []
for model in self.cnns:
outputs.append(model(x))
x = self.downsample(x)
return outputs
def calc_dis_loss(self, input_fake, input_real):
# calculate the loss to train D
outs0 = self.forward(input_fake)
outs1 = self.forward(input_real)
loss = 0
for it, (out0, out1) in enumerate(zip(outs0, outs1)):
if self.gan_type == 'lsgan':
loss += torch.mean((out0 - 0)**2) + torch.mean((out1 - 1)**2)
elif self.gan_type == 'nsgan':
all0 = Variable(torch.zeros_like(out0.data).cuda(), requires_grad=False)
all1 = Variable(torch.ones_like(out1.data).cuda(), requires_grad=False)
loss += torch.mean(F.binary_cross_entropy(F.sigmoid(out0), all0) +
F.binary_cross_entropy(F.sigmoid(out1), all1))
else:
assert 0, "Unsupported GAN type: {}".format(self.gan_type)
return loss
def calc_gen_loss(self, input_fake):
# calculate the loss to train G
outs0 = self.forward(input_fake)
loss = 0
for it, (out0) in enumerate(outs0):
if self.gan_type == 'lsgan':
loss += torch.mean((out0 - 1)**2) # LSGAN
elif self.gan_type == 'nsgan':
all1 = Variable(torch.ones_like(out0.data).cuda(), requires_grad=False)
loss += torch.mean(F.binary_cross_entropy(F.sigmoid(out0), all1))
else:
assert 0, "Unsupported GAN type: {}".format(self.gan_type)
return loss
- multi-scale(3个),每个鉴别器含有【4层卷积block与一个conv1x1】,每个鉴别器输入图像大小分别为256,128,64(体现multi-scale);输出分别为
(N,1,16,16),(N,1,8,8),(N,1,4,4) - 类中定义了计算鉴别器loss与生成器loss的函数
calc_dis_loss(),calc_gen_loss(),损失使用LSGAN损失
1.3 MUNIT_Trainer类中更新鉴别器函数:
def dis_update(self, x_a, x_b, hyperparameters):
self.dis_opt.zero_grad()
s_a = Variable(torch.randn(x_a.size(0), self.style_dim, 1, 1).cuda())
s_b = Variable(torch.randn(x_b.size(0), self.style_dim, 1, 1).cuda())
# encode
c_a, _ = self.gen_a.encode(x_a)
c_b, _ = self.gen_b.encode(x_b)
# decode (cross domain)
x_ba = self.gen_a.decode(c_b, s_a)
x_ab = self.gen_b.decode(c_a, s_b)
# D loss
self.loss_dis_a = self.dis_a.calc_dis_loss(x_ba.detach(), x_a)
self.loss_dis_b = self.dis_b.calc_dis_loss(x_ab.detach(), x_b)
self.loss_dis_total = hyperparameters['gan_w'] * self.loss_dis_a + hyperparameters['gan_w'] * self.loss_dis_b
self.loss_dis_total.backward()
self.dis_opt.step()
输入为属于不同domain的两张图片,分别得到它们的content code 后,进行基于噪声的cross domain 合成,最后输入真实影像与合成影像到鉴别器进行优化。更新鉴别器完成了图中红框的部分:
![[ECCV2018] [MUNIT] Multimodal Unsupervised Image-to-Image Translation_第8张图片](http://img.e-com-net.com/image/info8/851d0fb0bb8548c99f56586aca6471d2.jpg)
1.4 MUNIT_Trainer类中更新生成器函数:函数完成的上图中所有转换,即img–解码成code – cross domain 重建 – 对重建img解码 (–再次重建原始img,该步类似于cyclge loss,代码中没使用)。
def gen_update(self, x_a, x_b, hyperparameters):
self.gen_opt.zero_grad()
s_a = Variable(torch.randn(x_a.size(0), self.style_dim, 1, 1).cuda())
s_b = Variable(torch.randn(x_b.size(0), self.style_dim, 1, 1).cuda())
# encode
c_a, s_a_prime = self.gen_a.encode(x_a)
c_b, s_b_prime = self.gen_b.encode(x_b)
# decode (within domain)
x_a_recon = self.gen_a.decode(c_a, s_a_prime)
x_b_recon = self.gen_b.decode(c_b, s_b_prime)
# decode (cross domain)
x_ba = self.gen_a.decode(c_b, s_a)
x_ab = self.gen_b.decode(c_a, s_b)
# encode again
c_b_recon, s_a_recon = self.gen_a.encode(x_ba)
c_a_recon, s_b_recon = self.gen_b.encode(x_ab)
# decode again (if needed)
x_aba = self.gen_a.decode(c_a_recon, s_a_prime) if hyperparameters['recon_x_cyc_w'] > 0 else None
x_bab = self.gen_b.decode(c_b_recon, s_b_prime) if hyperparameters['recon_x_cyc_w'] > 0 else None
# reconstruction loss
self.loss_gen_recon_x_a = self.recon_criterion(x_a_recon, x_a)
self.loss_gen_recon_x_b = self.recon_criterion(x_b_recon, x_b)
self.loss_gen_recon_s_a = self.recon_criterion(s_a_recon, s_a)
self.loss_gen_recon_s_b = self.recon_criterion(s_b_recon, s_b)
self.loss_gen_recon_c_a = self.recon_criterion(c_a_recon, c_a)
self.loss_gen_recon_c_b = self.recon_criterion(c_b_recon, c_b)
self.loss_gen_cycrecon_x_a = self.recon_criterion(x_aba, x_a) if hyperparameters['recon_x_cyc_w'] > 0 else 0
self.loss_gen_cycrecon_x_b = self.recon_criterion(x_bab, x_b) if hyperparameters['recon_x_cyc_w'] > 0 else 0
# GAN loss
self.loss_gen_adv_a = self.dis_a.calc_gen_loss(x_ba)
self.loss_gen_adv_b = self.dis_b.calc_gen_loss(x_ab)
# domain-invariant perceptual loss
self.loss_gen_vgg_a = self.compute_vgg_loss(self.vgg, x_ba, x_b) if hyperparameters['vgg_w'] > 0 else 0
self.loss_gen_vgg_b = self.compute_vgg_loss(self.vgg, x_ab, x_a) if hyperparameters['vgg_w'] > 0 else 0
# total loss
self.loss_gen_total = hyperparameters['gan_w'] * self.loss_gen_adv_a + \
hyperparameters['gan_w'] * self.loss_gen_adv_b + \
hyperparameters['recon_x_w'] * self.loss_gen_recon_x_a + \
hyperparameters['recon_s_w'] * self.loss_gen_recon_s_a + \
hyperparameters['recon_c_w'] * self.loss_gen_recon_c_a + \
hyperparameters['recon_x_w'] * self.loss_gen_recon_x_b + \
hyperparameters['recon_s_w'] * self.loss_gen_recon_s_b + \
hyperparameters['recon_c_w'] * self.loss_gen_recon_c_b + \
hyperparameters['recon_x_cyc_w'] * self.loss_gen_cycrecon_x_a + \
hyperparameters['recon_x_cyc_w'] * self.loss_gen_cycrecon_x_b + \
hyperparameters['vgg_w'] * self.loss_gen_vgg_a + \
hyperparameters['vgg_w'] * self.loss_gen_vgg_b
self.loss_gen_total.backward()
self.gen_opt.step()
def compute_vgg_loss(self, vgg, img, target):
img_vgg = vgg_preprocess(img)
target_vgg = vgg_preprocess(target)
img_fea = vgg(img_vgg)
target_fea = vgg(target_vgg)
return torch.mean((self.instancenorm(img_fea) - self.instancenorm(target_fea)) ** 2)
1.5 在训练生成器时,因为包含两个网络gen_a,gen_b,计算完损失后,如何同时更新两个网络呢?1、直接分别定义它们的优化器,再两个网络依次step()即可;2、也可以按本文代码如下定义一个优化器,最后可只使用一次step();
gen_params = list(self.gen_a.parameters()) + list(self.gen_b.parameters())
self.gen_opt = torch.optim.Adam([p for p in gen_params if p.requires_grad],
lr=lr, betas=(beta1, beta2), weight_decay=hyperparameters['weight_decay'])
2、 torch.cuda.synchronize()
这部分代码如下:
class Timer:
def __init__(self, msg):
self.msg = msg
self.start_time = None
def __enter__(self):
self.start_time = time.time()
def __exit__(self, exc_type, exc_value, exc_tb):
print(self.msg % (time.time() - self.start_time))
with Timer("Elapsed time in update: %f"):
# Main training code
trainer.dis_update(images_a, images_b, config)
trainer.gen_update(images_a, images_b, config)
torch.cuda.synchronize()
- 上述代码,
Timer()是一个上下文管理器【参考】,在执行到with时,先调用Timer的__enter__(),如果是使用的with ... as ...,该函数返回的内容会赋值给as后的变量;然后再调用with内部的语句块;最后调用__exit__(). torch.cuda.synchronize()等待当前GPU设备所有任务完成。进入with的时候,__enter__()内timer开始计时,之后完成G、D的更新,等待所有GPU任务结束,进入__exit__()内停止计时,并打印时间
代码中batch_size设置为1,运行时打印如下,每对图像更新大约需要0.35s:
![[ECCV2018] [MUNIT] Multimodal Unsupervised Image-to-Image Translation_第9张图片](http://img.e-com-net.com/image/info8/c0e7b62c4ba84683a3e12f91ca509dd8.jpg)
训练结果
单个1080Ti 训练16小时,210000个iteration后,测试图片上结果如下,每一列为一个样例。其中x_a与x_b为两个domain的真实图像,x_ab1 为利用从x_b得到的style code 进行合成的结果,x_ab2 为利用随机采样得到的style code 进行合成的结果。从合成图可以看出其MUNIT转换的多样性。
我的思考
1、style code 支持直接从正态分布采样,也支持直接从参考图像进行编码
2、模型到底如何区分style 是颜色等渲染,而 content 是空间结构的?
3、AdaIN的实现上 与 StarGAN v2 不同。前者一个MLP同时计算出所有AdaIN层的weight,bias参数,后者每个AdaIN层都有一个独立的MLP来计算参数