CodeKoan:一种提取群体知识的源代码模式搜索引擎
CodeKoan: A Source Code Pattern Search Engine Extracting Crowd Knowledge
- 作者
- 会议
- 摘要
- 1 介绍
- 2 相关工作
- 2.1 源代码搜索引擎
- 2.2 代码克隆检测和剽窃
- 2.3 以前使用Stack Overflow数据的工作
- 3 源代码相似性搜索
- 3.1 源代码模式
- 3.2 源代码重用
- 3.3 源代码相似性
- 4 一种搜索代码模式重用的算法
- 4.1 索引代码片段
- 4.2 相似性搜索的管道算法
- 5 实施
- 6 评估
- 6.1 量化假阳性的发生
- 6.2 量化假阴性的发生
- 6.3 实证分析
- 7 结论和未来工作
- 参考文献
作者
Christof Schramm
Institute for Informatics, LMU
Munich, Germany
[email protected]
Yingding Wang
Institute for Informatics, LMU
Munich, Germany
[email protected]
François Bry
Institute for Informatics, LMU
Munich, Germany
[email protected]
会议
2018 ACM/IEEE 5th International Workshop on Crowd Sourcing in Software Engineering
摘要
源代码搜索在软件开发中是经常需要的和重要的。关键字搜索源代码是一种广泛使用但有限的方法。本文介绍了一个可扩展引擎CodeKoan,用于搜索全球程序员社区编写的数百万在线代码示例,该引擎使用数据并行处理来实现水平扩展。搜索引擎依赖于基于单词(token)的、编程语言无关的算法,并且作为概念证明从Stack Overflow索引两个编程语言:Java和Python的所有代码示例。本文通过分析众所周知的开放源代码库(如OpenNLP和ElasticSearch)来演示从Stack Overflow中提取群体知识的好处:在被检查的仓库中,多达三分之一的源代码重用来自Stack Overflow的代码模式。它还表明,所提出的方法可以识别相似的源代码,并且能够适应诸如语句的插入、删除和交换等修改。此外,还证明了所提出的方法在搜索结果中只返回很少的误报。
关键词:挖掘群组知识、源代码搜索、代码模式、源代码相似性、Stack Overflow、搜索算法
1 介绍
编程和软件工程中的一个首要主题一直是源代码重用[10]。广泛可用的库是软件工程的主要成就,因为它们使程序员可以使用复杂的功能。库中源代码的重用一直是软件行业持续增长的一个有利因素[25]。
Brandt等人的研究[7]已经表明,程序员在面临新的实现任务时,通常会查找包含代码示例的在线文档。这项工作的目的是提供一种新的方法,使用包含在在线代码示例的群体知识,以经验地、自动地和有效地检测重用短源代码片段(5-10行代码)。
在线代码示例通常不是针对特定问题的特定解决方案,而是针对经常发生的小规模实现任务的一般解决方案。这些小规模的解决方案集称为源代码模式。
虽然通过检查构建文件可以很容易地自动检测库的使用情况,但是检测代码模式重用要复杂得多。当重用时,代码模式通常适应相关的上下文,以提供定制的解决方案。这使得检测代码模式重用成为一项具有挑战性的任务,因为必须克服模式适应带来的模糊性。
研究代码模式重用有助于创建新的库和工具,为程序员提供反馈。这种反馈可以将程序员链接到相关的在线文档中,以获取与源代码类似的代码示例。此外,基于CodeKoan 的IDE插件可以在项目中引入冗余代码时提醒程序员。本文介绍了一个代码模式搜索引擎CodeKoan ,它利用了在https://codekoan.org上可以访问的Stack Overflow的群体知识。可在https://github.com/kryoxide/codekoan下找到CodeKoan 搜索引擎的完整、AGPLv3授权源代码。
本文的主要贡献是:
- 基于从Stack Overflow中提取的代码模式,构建独创的独立于编程语言的代码模式识别方法。
- 该方法在Stack Overflow的Java和Python两种语言的群体知识部署概念证明。
- 基于著名软件库的概念验证应用的定量分析,指出了所提出的搜索引擎的有效性。
2 相关工作
2.1 源代码搜索引擎
源代码搜索的基本方法可以根据用户提交查询的类型加以区分。
- 根据关键字搜索源代码被许多公共可用的源代码托管平台使用。这种方法的帮助有限,因为通常大量的搜索结果可能与用户正在搜索的内容无关[1]。
- 根据规范搜索源代码是[15,27]中介绍的另一种方法。
- 根据预定义模式视图搜索源代码是根据被索引的源代码中出现的形式预定义查询模式搜索的方法的改进[19]。
注:这几个文献没有看,所以无法理解第二第三项。
本文提出的方法根据查询源代码中出现的任意模式搜索。它不需要查询的抽象规范,可以直接搜索源代码而无需进行任何修改。因此,它与上述方法有很大不同。
2.2 代码克隆检测和剽窃
代码克隆检测的任务是在软件系统之间定位相似源代码的共享部分[24]。虽然在代码克隆检测方面的研究侧重于在源代码项目内部或之间查找复制的或冗余的代码,但这项工作的重点是搜索Web资源以实现源代码重用。
在以前的代码克隆检测研究中,开发了多种算法,大致可分为以下四种比较源代码的方法[22]:
- 根据原始字符串比较,即分析源代码的原始字符串表示,包括注释和格式[2]。
- 根据一个单词字符串的源代码比较。这种算法[14,20,24]有识别相似性的优势,尽管布局、标识符名称和注释不同。这些方法的一个优点是它们往往具有很高的性能。
- 根据抽象语法树(Abstract syntax tree,AST)比较[4,12]。这种算法的一个严重缺点是,AST非常注重源代码的顺序和结构。
- 根据程序依赖图分析。程序依赖图表示源代码的某些部分对其他部分的依赖性[9]。这样一个图可以包含语句和赋值,这些语句和赋值是作为具有边的节点,边将变量的每次使用都链接到其声明中。这些图包含的语义信息比前面提到的三种源代码表示(原始字符串、单词字符串和AST)更多。将这些图进行比较,最终可以简化为求解子图同构问题,该问题已被证明是NP完全问题[21],这意味着这种方法几乎无法进行测量。一些作者[8,16]提出了基于依赖图的代码克隆检测方法,试图管理底层问题的NP完全问题。
注需要进一步学习的知识:
- 抽象语法树(Abstract Syntax Tree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。
2.3 以前使用Stack Overflow数据的工作
Stack Overflow1是一个流行的用于解决编程问题在线问答(Q&A)网站。Stack Overflow上的用户内容在Q&A进程中生成,该进程由提交问题的用户启动,其他用户随后回答该问题。Stack Overflow的一个重要特性是它的评级系统,用户可以通过它来投票决定文章的相关性。这评级有助于提交(post)的可见度。Stack Overflow已经为大量的API、主题和编程语言提供高质量的文档[18]。此外,以前的大量研究使用Stack Overflow数据[3、6、17、29]。此外,Stack Overflow上的用户生成的内容有一个创造性共享许可(Creative Commons license),它允许在研究项目中使用。Stack Overflow在其网站上发布了所有提交的季度转储。有关Stack Overflow数据的出版物包括提交质量研究[17]、讨论的主题[3]以及用户行为和评级[6]。Vassallo等人[29]发布了Eclipse插件CODES系统,它挖掘Stack Overflow数据,以便从Stack Overflow提交的Java类生成注释和文档。CODES系统不会为任意代码生成文档,而是为已经存在的、在Stack Overflow讨论的开源项目生成文档。CODES系统使用Stack Overflow提供的基于关键字的搜索机制,不执行专门的源代码搜索。
3 源代码相似性搜索
3.1 源代码模式
该方法的目标是发现源代码文件中作为用户查询提交的源代码小片段的重用。作为当前搜索引擎设计的主要焦点,代码片段的长度应介于5到50行代码之间。
下面的示例中给出了与CodeKoan搜索引擎相关的代码片段的示例,该代码片段读取文件并逐行打印到标准输出流:
// try-with-resources statement
try (BufferedReader reader = Files.newBufferedReader(file, charset)) {
String line = null;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException x) {
System.err.format("IOException: %s%n", x);
}
有许多线上代码示例展示了相同代码的细微变化:有些缺乏明确的ASCII字符集定义,有些则不尝试使用资源声明(在Java 7中介绍)。但是所有这些代码都使用相似的源代码来完成一个非常相似的任务。这些代码示例被认为是源代码模式的实例,它们解决了具体实现的问题,例如“使用BufferedReader逐行读取文件”。为了简洁起见,本文不包含更多的代码示例。
3.2 源代码重用
用户提交给CodeKoan搜索引擎的查询是单一源代码文件。CodeKoan的目的是寻找查询文件中所有被索引的源代码片段的重用,以及此查询构成重用的区域。应该注意的是,有两种类型的源代码重用,其发生的原因不同[28]。
- 源代码重用的第一种类型是源代码文档中引用示例的改编。以前的工作[7]特别建议这是普遍的行为。
- 第二种类型的源代码重用发生在以下情况下:功能是按照代码模式实现的,但不是特意地改编外部代码。
在这两种情况下,CodeKoan都可以自动将代码库中重用的任何代码片段链接到相关文档,在这些文档中会出现代码片段。本文档可能会指出所实现解决方案的边缘情况或弱点,甚至可能包含不同的、更正确的解决方案。CodeKoan给程序员的一个好处是,它可以将源代码链接到现有的文档,并更好地概述现有解决方案的领域。
3.3 源代码相似性
这项工作的目的是找到在源代码中相似于被索引的代码片段的区域。Walenstein等人[30]指出,相似度的概念本质上是模糊的,因为任何相似度的概念都依赖于一组比较所依据的标准。在这一部分中,我们介绍了由所提出的搜索算法捕获的源代码相似性的概念。还有许多其他的源代码相似性定义,其中一些定义将在第2节中讨论。
从广义上讲,源代码相似性可以从两个视图来看待:语法相似性和语义相似性。一个源代码相似性纯粹的语法视图只考虑程序的语法而不试图捕捉它们的含义,而一个源代码相似性的语义视图只考虑源代码的含义而不考虑语法。
如果两个程序的源代码相同,那么它们在语法上是等价的;如果它们执行完全相同的操作,那么不管语法如何,它们在语义上是等价的。从实际实现的角度来看,对所提出的搜索引擎而言,语法和语义检测都并不是很有帮助。源代码在语法上的等价性是很容易检测到的,但太容易受到诸如源代码布局等方面的细微变化的影响。另一方面,识别源代码语义上的等价性将非常有用,但这(通常)是不可检测的。语义程序相等的问题最终可以归结为两个图灵机是否为相同的输入生成相同的输出,这是不可确定的。
在Codekoan算法中使用的相似性概念处于这两个极端之间的中间地带。搜索引擎初始生成一组假阳性(False Positive)概率很高的搜索结果,然后通过使用启发法筛选出假阳性来优化语义相似度。
假阳性(False Positive)指预测却是错误的,然而真实结果是正确的。
预测结果为Flase 预测结果为True 真实结果 Positive 假阳性False Positive 真阳性True Positive 真实结果 Negative 真阴性True Negative 假阴性False Negative
Codekoan的相似性检测基于四个特征。
- 第一个特征是单词字符串级别上的语法相似性。第一步对单词字符串进行比较,使得Codekoan搜索算法不依赖于空格和注释,这两者都与源代码执行的函数无关。
- 第二个相似性特征是在查询文档中按区域充分覆盖代码片段。只有当代码模式大部分存在于查询代码中时,才被视为重用。因此,只有当查询区域与大多数模式匹配时,才认为它们与模式相似。
- 第三个特征是查询文档中匹配代码与比较代码片段的结构相似性。要比较的结构是源代码的块结构,它控制的变量范围等。例如,在使用C类语法的编程语言中,块由大括号分隔。
- 第四个特征是标识符中词汇的相似性。如果两段源代码都处理相似的主题,则认为它们是相似的。主题相似是测量比较源代码片段中作为标识符的一部分出现的词汇。
4 一种搜索代码模式重用的算法
4.1 索引代码片段
算法的核心部分是将被索引的代码片段(网上索引的代码)的单词字符串与查询源代码(提交查询的代码)的单词字符串进行比较。为了有效地搜索数百万个代码片段集,使用了所有代码片段的单词字符串的归纳后缀树(Generalized Suffix Trees,GSTs)。GSTs是归纳后缀树概念的数据结构,它将单个字符串的结构暴露为一组字符串。
对于任何给定的字母 ∑ \sum ∑和字符串集 T \mathcal{T} T,一个GST是一个带有标记边的树,其中从根到叶节点的任何路径都会拼出一些字符串 s ∈ T s \in \mathcal{T} s∈T的后缀。此外,从一个节点到其子节点任何两个边都不能以相同的字母 c ∈ ∑ c \in \sum c∈∑开头。GSTs可用于确定字符串 P P P是否是 O ( ∣ P ∣ ) O(|P|) O(∣P∣)的任意字符串子集的中任何字符串的子字符串。构造一个GST是可能时间 O ( ∑ t ∈ T ∣ t ∣ ) O(\sum_{t \in \mathcal{T}} |t|) O(∑t∈T∣t∣)[11]。接下来使用的GST是从集合 A = { A k ∣ k ∈ N } \mathcal{A}=\{A^k|k \in \mathbb{N} \} A={Ak∣k∈N}生成的,该集合包含所有被索引的代码片段的单词字符串 A k A^k Ak。使用的字母 ∑ \sum ∑是一组依赖于语言的单词集。
注:大概意思就是一个字符串集可以生成一个GST, A k A^k Ak是所有被索引的代码片段的单词字符串集合,利用 A k A^k Ak生成一组GST
CodeKoan搜索引擎对每种编程语言都只使用一种索引。这种索引由两部分组成:一种编程语言的所有代码片段中已经提到的单词字符串 A k A^k Ak的GST和一个10元模型(10-grams)的布隆过滤器(Bloom Filter)。布隆过滤器是基于散列的数据结构,允许查询 O ( 1 ) O(1) O(1)[5]中的集合成员。布隆过滤器用于在固定的时间内识别10单词序列是否是任何被索引的代码片段的成员。布隆过滤器具有一个明确低的,可控性好的假阳性率,但不存在假阴性。
注需要进一步学习的知识:
- N-Gram(有时也称为N元模型)是机器学习中NLP处理中的一个较为重要的语言模型,常用来做句子相似度比较,模糊查询,以及句子合理性,句子矫正等。
- Bloom Filter(BF)是一种空间效率很高的随机数据结构,它具有很好的空间和时间效率,被用来检测一个元素是不是集合中的一个成员。它是一个判断元素是否存在集合的快速的概率算法。Bloom Filter有可能会出现错误判断,但不会漏掉判断。也就是Bloom Filter判断元素不再集合,那肯定不在。如果判断元素存在集合中,有一定的概率判断错误。因此,Bloom Filter”不适合那些“零错误的应用场合。而在能容忍低错误率的应用场合下,可见 Bloom filter 是牺牲了正确率和时间以节省空间,比其他常见的算法(如Hash,折半查找)极大节省了空间。
4.2 相似性搜索的管道算法
CodeKoan的搜索算法的功能就像管道,在管道中,初始步骤生成一组非常大的部分搜索结果。管道的后续部分对这些初始搜索结果过滤并进行分组。每个管道步骤之后识别的代码片段集是各自之后管道步骤输入的子集。
管道背后的想法是首先将代码片段的单词子字符串与查询文件相同的单词子字符串相匹配。然后,这些匹配的单词子字符串按其原始代码片段分组,生成的单词子字符串组是搜索结果。这些搜索结果有很高的假阳性率。管道步骤2-4旨在降低这种假阳性率。
步骤1: 对齐。CodeKoan搜索算法的初始步骤是使用编程语言独有的词法分析器(lexer)从查询文件中获取一个单词字符串D。
词法分析(英语:lexical analysis)是计算机科学中将字符序列转换为单词(Token)序列的过程。进行词法分析的程序或者函数叫作词法分析器(Lexical analyzer,简称Lexer),也叫扫描器(Scanner)。词法分析器一般以函数的形式存在,供语法分析器调用。
定义4.1. 设 S S S是一个字符串。那么 S a : b , a ≤ b S_{a:b}, a≤b Sa:b,a≤b是从位置a开始,长度为 b − a b−a b−a的 S S S的子字符串。 S a : S_{a:} Sa:是从位置 a a a开始的 S S S的后缀。
首先,所有后缀 D i : D_{i:} Di:从索引布隆过滤器识别的一个10元模型成员开始。这些后缀是相关联的,因为从布隆过滤器中可以知道,很可能存在一些被索引的代码片段的子字符串,该子字符串出现在D中,并且至少有10个单词长。然后,使用索引GST为每个相关后缀 D i : D_{i:} Di: 标识被索引的代码片段 A k A^k Ak的所有子字符串 A j : j + n k A^k_{j:j+n} Aj:j+nk,这些子字符串与相应相关后缀的前缀 D i : i + n D_{i:i+n} Di:i+n相同。
定义4.2. 产生的子字符串对 ( D i : i + n , A j : j + n k ) (D_{i:i+n}, A^k_{j:j+n}) (Di:i+n,Aj:j+nk)称为对齐匹配集。对齐匹配的第一部分称为“查询端”,第二部分称为“模式端”。
定义4.3. 搜索结果是一组对齐匹配集,其中所有模式端都是相同代码片段 A k A^k Ak的单词子字符串。
对齐匹配集被分组到搜索结果中,以确保每个代码片段 A k A^k Ak有一个搜索结果,其中子字符串至少出现在一个对齐匹配项中。
此步骤将第一个参数引入算法,该参数由最小对齐匹配长度n给出。小于n个单词的对齐匹配将被丢弃。该参数n必须大于n元模型尺寸10,这是在布隆过滤器结构中使用的。
这部分没有看太懂
步骤2: 覆盖过滤。算法的步骤1确定了查询D和代码片段 A k A^k Ak的所有对齐匹配 ( D i : i + n , A j : j + n k ) (D_{i:i+n}, A^k_{j:j+n}) (Di:i+n,Aj:j+nk)。第3.3节中概述的第二个相似性标准是,只有当模式的大部分被重用时,代码模式才会被重用。将筛选出不满足此要求的代码片段 A k A^k Ak的所有单词子字符串集。例如,考虑第3.1节中给出的代码片段。如果Java查询文件中的一些打印(print )语句与片段中的打印语句相匹配,而不实际读取文件,则这将不构成模式重用。设 R k R^k Rk是代码片段 A k A^k Ak的搜索结果。那么 ∣ A k ∣ |A^k| ∣Ak∣是 A k A^k Ak中的单词数。通过 R k R^k Rk匹配的单词数定义为 m a t c h e d ( R k ) matched(R^k) matched(Rk),匹配如下所示:
(1) m a t c h e d ( R k ) = ∣ { i ∣ i ≥ 0 ∧ i < ∣ A k ∣ ∧ ∃ ( ( D a : a + x , A b : b + x k ) ∈ R k ) : i ≥ b ∧ i < b + x } ∣ matched(R^k)=|\{ i | i \geq 0 \wedge i < |A^k| \wedge \exists((D_{a:a+x}, A^k_{b:b+x}) \in R^k) : i \geq b \wedge i < b+x \} \tag1| matched(Rk)=∣{i∣i≥0∧i<∣Ak∣∧∃((Da:a+x,Ab:b+xk)∈Rk):i≥b∧i<b+x}∣(1)
定义4.4. 搜索结果 R k R^k Rk的覆盖范围是代码片段 A k A^k Ak至少包含在 R k R^k Rk中的一个对齐匹配中的单词数。 R k R^k Rk的覆盖范围规范化是 m a t c h e d ( R k ) ∣ A k ∣ \frac{matched(R^k)}{|A^k|} ∣Ak∣matched(Rk)
算法参数:覆盖阈值。覆盖范围低于某个阈值的所有搜索结果都将被删除。这个阈值是搜索算法的一个参数。
步骤3: 块结构过滤。在搜索算法的这一步中,将过滤算法步骤2生成的具有多个对齐匹配的搜索结果。只有一个对齐匹配的搜索结果将通过此步骤而不更改。此算法步骤依赖于成对对齐匹配冲突的概念,将在下面定义。此算法步骤将一组对齐匹配(见定义4.2)的搜索结果拆分为最大子集,这样,结果搜索结果中的任何一对对齐匹配都不会发生冲突。
为了定义什么时候两个对齐匹配发生冲突,定义了一个单词字符串 T ∈ ∑ ∗ T \in \sum^* T∈∑∗中两个索引a和b之间的函数 f b l o c k : ∑ ∗ × N × N → N × N f_{block} : \sum^* × \mathbb{N} ×\mathbb{N} \rightarrow \mathbb{N} ×\mathbb{N} fblock:∑∗×N×N→N×N。 f b l o c k f_{block} fblock是直观的描述源代码中两个点在源代码块结构上是如何相互关联的。该块结构可以用Java中的Python或打括号来定义。
独立于编程语言的单词缩进是指打开块的单词,而单词取消缩进是指关闭块的单词。算法1给出了 f b l o c k f_{block} fblock的完整伪码定义。直观地说, f b l o c k f_{block} fblock返回的元组(up,down)描述了单词字符串 T T T中从索引a到索引b必须退出和重新进入的块的数量。例如,如果a和b在同一个块中,(up,down)将为(0, 0)。如果b在a的子块中,则 f b l o c k f_{block} fblock的结果是(0, 1)。使用 f b l o c k f_{block} fblock,可以定义对齐匹配冲突:
定义4.5. 设 ( D a : a + l , A x : x + l k ) (D_{a:a+l}, A^k_{x:x+l}) (Da:a+l,Ax:x+lk)和 ( D b : b + m , A y : y + m k ) (D_{b:b+m}, A^k_{y:y+m}) (Db:b+m,Ay:y+mk)为在相同的搜索结果中的两个对齐匹配。这两个对齐匹配的冲突当且仅当:
- 如果两个对齐匹配查询端和模式端单词子字符串范围重叠;
- 或者如果 f b l o c k ( D , a , b ) ≠ f b l o c k ( A k , x , y ) f_{block}(D, a, b) \neq f_{block}(A^k, x, y) fblock(D,a,b)̸=fblock(Ak,x,y);
Data: TokenString T, indices a and b
if a > b then
return fblock (T,b, a)
else
(up, down) = (0,0);
i = a;
while i != b do
i = i + 1;
t =T [i];
if t == token_indent then
up = up + 1;
else if t == token_unindent then
if up > 0 then
up = up - 1;
else
down = down + 1;
end
end
return (up,down)
end
算法1: 块关系函数 f b l o c k f_{block} fblock(伪代码)
生成无冲突子集。对于算法步骤2返回的每个搜索结果 R k R^k Rk,建立一个以 R k R^k Rk中的对齐匹配为顶点的图 G ( R k ) G(R^k) G(Rk)。如果两个对齐匹配项不冲突,则由(无向)边连接。
图 G G G中的一个通量 G ′ G' G′是 G G G的一部分,其中存在一条从任何顶点到其他顶点的边[13]。对搜索结果 R k R^k Rk中的对齐匹配构造图 G ( R k ) G(R^k) G(Rk)中的所有最大通量进行了识别。这些最大通量是将在管道中进一步处理的新搜索结果。为了保持算法步骤2的覆盖不变性,对新生成的搜索结果重新应用覆盖过滤器。然后将这些结果传递到步骤4。管道步骤2之后的搜索结果集只包含任何代码片段 A k A^k Ak的一个搜索结果。在步骤3之后,此条件不再保持。任何代码片段 A k A^k Ak都可以有多个搜索结果。
步骤4: 标识符相似性匹配。如第3.3节所述,源代码相似性的关键标准之一是包含在源代码标识符中的信息。这些标识符中的信息在一段源代码后面传递程序员的意图。这一步骤的目的是获得允许;目的不是只保留“正确”的搜索结果,而是排除那些很可能是误报的结果。
处理搜索结果 R k R^k Rk的第一步是分别标识查询边和模式边所覆盖的所有标识符的两组 I q u e r y I_{query} Iquery和 I p a t t e r n I_{pattern} Ipattern,以及搜索结果 R k R^k Rk中所有对齐匹配的两组 I q u e r y I_{query} Iquery和 I p a t t e r n I_{pattern} Ipattern。大多数编程语言使用驼峰命名法(例如如骆驼命名法标识符)或蛇形命名法(例如蛇形命名法标识符)。在这两种命名约定中,可以将多单词标识符拆分为多个单词集。
离开 I q u e r y I_{query} Iquery、 I p a t t e r n I_{pattern} Ipattern的标识符集,生成两背包单词,其中包含 I q u e r y I_{query} Iquery和$I_{pattern}标识符中的单词。这两背包单词使用TF-IDF余弦相似性度量[26]进行比较,得出范围[0,1]内的值。值为1表示最大相似性,值为0表示最大差异。此步骤的工作原理是排除所有低于某个给定阈值的搜索结果,这些搜索结果的相似性值如上所述。此阈值是算法管道的参数。
5 实施
该搜索引擎是一个并发的分布式系统,可以在一组机器上水平扩展。数据并行处理用于满足所实现系统的可扩展性需求。这是因为索引数据结构(GST和布隆过滤器)可以在一组机器之间进行拆分和分布。
不需要为被索引的代码片段集 A = { A k ∣ 0 ≤ k < n } \mathcal{A}=\{A^k|0 \leq k < n \} A={Ak∣0≤k<n}构建单个GST,其中n是被索引的代码片段的数量。可以将 A \mathcal{A} A拆分为n个子集 { A 0 , . . . , A n − 1 } \{ \mathcal{A}_0,..., \mathcal{A}_{n-1}\} {A0,...,An−1},每个子集都可以创建一个单独的索引。因此,单个编程语言的索引遍历可以分布在n台工作机器上。对CodeKoan的每个查询都由包含部分索引的n台工作机通过所有四个管道步骤进行独立处理。最后的结果是这些n个结果集的并集。
RabbitMQ。RabbitMQ消息代理用于连接CodeKoan的分布式集群的各个部分。RabbitMQ具有很高的性能,并在工作节点发生故障时保持消息,从而最大限度地减少数据丢失的可能性。RabbitMQ将每个查询的副本分发给集群中的n台工作机。专用进程收集查询的所有部分结果,直到生成完整的结果为止。
索引。CodeKoan搜索引擎的索引由两个实现的编程语言Java和Python中的所有Stack Overflow答案中的代码示例组成。Stack Overflow提供了所有用户提交内容的季度XML转储,这些内容是在一个CreativeCommons许可证下获得许可的。此转储用于将所有Stack Overflow日志索引到PostgreSQL数据库中。
Stack Overflow文章的内容以HTML形式提供,从中可以通过读取
块来解析源代码示例。短于10个单词的代码示例不会被索引。假设Stack Overflow答案中的代码示例是用给定语言编写的,如果答案是回答一个问题,该问题具有相应的语言标记(例如“Java”)。
6 评估
6.1 量化假阳性的发生
如果报告为重用的代码片段 A k A^k Ak在提交的查询源代码中没有实际重用,则该算法的搜索结果(定义见4.3)为假阳性。为了分析这一点,我们创建了一个专门的代码片段索引,用于创建和提交PostgreSQL数据库的查询。这些代码示例是Stack Overflow所有代码示例的子集,并且手动选择这些示例以仅包含PostgreSQL特定的源代码。
选择开放源代码仓库时,可以确定不会执行任何SQL数据库访问。选择这样的仓库很简单。例如,像ElasticSearch这样的NoSQL数据库不包含用于访问PostgreSQL数据库的源代码。DuckDuckGo Android应用程序也没有。
分析后的仓库中的每个源代码文件都将以一个专门的索引提交给建议的搜索引擎。这个专门的索引只包含代码片段,在其中创建和提交PostgreSQL查询。由于所分析的应用程序不使用此类代码模式,因此搜索引擎生成的每个结果在构造上都是假阳性的。
表1分别显示了ElasticSearch和DuckDuckGo Android应用程序仓库的此类假阳性结果的数量。如预期,“低”设置会产生大量假阳性结果。“低”设置的目的是尽量减少假阴性的数量,而很少考虑假阳性的数量。“中等”搜索设置是最小化假阳性率和假阴性率之间的折衷。使用此搜索设置的弹性搜索仓库中的误报数量非常少,每1000行代码的误报搜索结果少于一个。“高”设置没有产生任何假阳性结果。这是意料之中的,因为它是一种设置,旨在在接受增加的假阴性结果的同时将假阳性率降至最低。
表1:查询指定仓库中所有源代码文件时,各种搜索设置的搜索结果数。所有的搜索结果根据构造都是假阳性,因为使用的索引只包含专门查询PostgreSQL的代码模式。所有列出的仓库都不使用SQL数据库。
仓库
搜索设置
假阳性/1000行代码
Elasticsearch
低
146.14
中
0.46
高
0.0
DuckDuckGo
(Android App)
低
76.04
中
0.273
高
0.0
6.2 量化假阴性的发生
识别假阴性结果的传统方法是使用黄金标准,即查询一组文档哪个完美,搜索结果“真”集是已知的。CodeKoan的索引太大,专家无法决定每个被索引的代码示例是否在查询文件中重用。因此,建立了“综合黄金标准”来测量假阴性率。这种方法类似于Roy等人[23]之前发表的工作。在这种“综合黄金标准”方法中,只构建了一个代码示例E的索引。由于搜索算法是自反的,因此使用 E E E作为搜索查询,在搜索结果中返回 E E E。如果 E ′ E' E′是 E E E的一个微小的修改,使用 E ′ E' E′作为搜索查询,建议的搜索算法仍然应该确定 E ′ E' E′是模式 E E E的重用,并在搜索结果中返回 E E E。如果e E E E查询 E ′ E' E′的搜索结果,则 E E E被视为假阴性结果。
为了进行这种分析,使用了三种基本类型的源代码修改:简单语句的插入、删除和交换。简单语句是“没有任何部分构成另一语句的语句”[31]。这意味着for循环、类声明和方法声明的头不是简单的语句。下面是一组随机选择的1000个代码示例,用于Stack Overflow的Python编程语言,其中只使用了10个简单语句。
这些随机选择的代码示例中的每一个都成功用列出的修改类型之一进行了修改。在所有代码示例修改一次之后,计算仍然可以识别的示例的计数。在此之后,对每个示例应用另一个修改。图1、2和3显示了这些插入、交换和删除实验的结果。
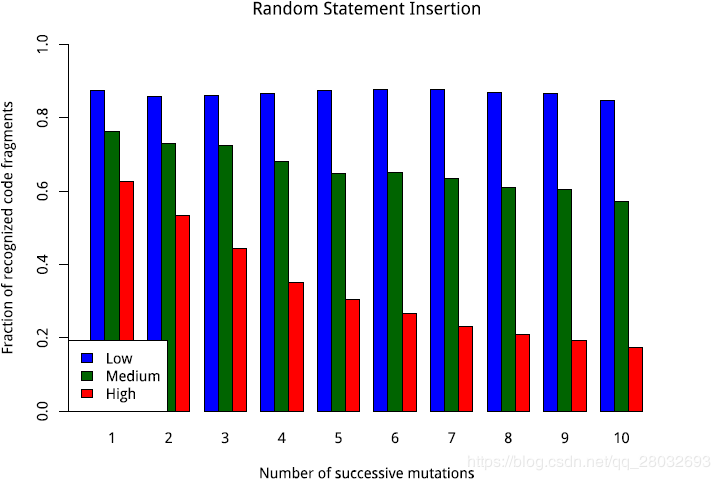
图1:在随机选择的10个简单语句长python代码示例中插入简单语句时的识别频率。值为1.0意味着所有突变的例子都被认为与原始的相似,值为0.0意味着没有一个被认为相似。频率显示为第6.1节中概述的三种不同搜索参数设置“低”、“中”和“高”。
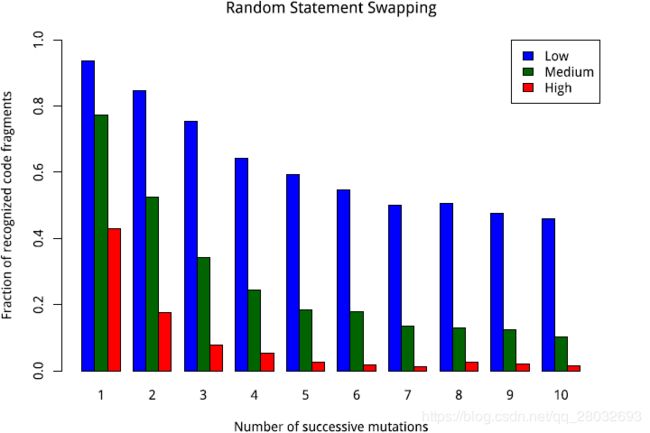
图2:在随机选择的10个简单语句长python代码示例中交换简单语句时的识别频率。值为1.0意味着所有突变的例子都被认为与原始的相似,值为0.0意味着没有一个被认为相似。

图3:从随机选择的10个简单语句长python代码示例中删除随机简单语句时的识别频率。值为1.0意味着所有突变的例子都被认为与原始的相似,值为0.0意味着没有一个被认为相似。
为了获得可比较的结果,选择了具有固定数量和精确数量的简单语句的代码示例。选择了10个简单语句的数目,因为Stack Overflow的代码示例通常大约有10个简单语句的长度,因此这些数字最具代表性。
图1、图2和图3表明,所提出的算法对于简单的语句插入非常有弹性,而交换和删除代码会导致识别率更快地下降。需要考虑的一点是,在一个10个简单语句的长代码片段中,删除3个或4个简单语句已经是一个实质性的更改,因此可以显著降低识别频率。
总的来说,对少量变更的识别率很高。此外,插入源代码是最有助于识别的场景。附加代码的插入增加了模式的功能,并且模式仍然被清晰地重用。另一方面,交换和删除一个模式的部分会很快导致语义的急剧变化,因此在这种变化上更快地降低识别率是搜索算法的一种期望行为,因为它被设计为只找到有意义的代码模式重用。
6.3 实证分析
本节显示在公共可用的源代码仓库中分析源代码的结果。这些分析是在每个仓库的基础上进行的。对分析仓库中的每个源代码文件查询CodeKoan ,并收集结果集。使用这些结果集集合,可以完成两件事情:
- 首先,在所有源代码文件中,至少包含一个搜索结果的所有单词的一小部分将被确定。因为只有来Stack Overflow应答的源代码被索引,所以这个一小部分表示项目的总源代码的一小部分至少类似于Stack Overflow上的一个应答。其次,根据匹配的Stack Overflow答案的标记,可以生成仓库的描述性标记。
Stack Overflow的重用率。 在这个分析中,建议的搜索引擎被用来量化在Stack Overflow中的几个公共仓库中被重用的源代码数量。如上所述,此过程很容易实现。对于给定的源代码仓库,项目中的每个源代码文件 F i F_i Fi都通过CodeKoan搜索引擎进行查询。设 ∣ F i ∣ |F_i| ∣Fi∣为 F i F_i Fi的单词字符串中的单词数。对于每个文件,覆盖单词数 c o v e r e d ( F i ) ≤ ∣ F i ∣ covered(F_i)\leq |F_i| covered(Fi)≤∣Fi∣是导出的,至少包含在一个搜索结果中。
这些覆盖率数字用于计算
(2) ∑ i c o v e r e d ( F i ) ∑ i ∣ F i ∣ \frac{\sum_i covered(F_i)}{\sum_i |F_i|} \tag2 ∑i∣Fi∣∑icovered(Fi)(2)
这个分数是项目中源代码的相对数量,它是作为Stack Overflow应答组件的源代码模式的一部分。利用该方法,收集了实际项目中源代码重用量的经验数据。结果分为表2的一些一般项目,以及表3中的Android应用程序。
项目名
重用 %
代码行数
描述
Open NLP
3.3
106.4k
NLP library
GraphJet
3.4
27.5k
Graph algorithms
maven-shared
6.3
97.4k
Maven components
testng
7.0
93.6k
Testing framework
tomcat
7.2
533.1k
Webserver
humanize
8.7
15.7k
Data formatting
Tiny
21.2
5.6k
Image processing
AlgoDS
21.5
17.2k
Algorithms, educational
Jest
23.2
27.6k
Elasticsearch client
表2:在Java编写的通用开源库中Stack Overflow的源代码示例的重用率
项目名
重用 %
代码行数
描述
duckduckgo-android
14.9
7.3k
Web Search Engine
openkeychain
15.9
96.1k
Encryption
studentenportal
21.2
18.5k
Klagenfurt university
TUM Campus
23.0
28.8k
TU munich
HWT Dresden
27.6
8.5k
Dresden university
unisannio
29.6
3.6k
University of Sannio
表3:Android应用程序中堆栈溢出的源代码示例的重用率
此分析的收集结果表明,在被分析的项目中,Stack Overflow发生的源代码模式在多大程度上被重用是有很大差异的。显然,Android项目显示了更高的源代码重用率。源代码重用检测率的差异通常可以通过在项目中使用流行的库和框架来解释。例如,Stack Overflow存在大量关于在Android应用程序中实现功能的问题。此外,依赖关系很少的库,实现基本算法(如GraphJet或Open NLP)的库往往显示出较低的重用率。
用CodeKoan标记仓库。 以上分析的结果集用于使用Stack Overflow问题中的标记为仓库生成描述性标记。每个定位的重用都引用Stack Overflow应答中的源代码,而Stack Overflow应答又是对单个带标记问题的应答。答案可以被认为与其父问题具有相同的标记。通过扩展,答案中的每个代码示例 A k A^k Ak都具有与整个答案相同的标记。因此,每个带有 A k A^k Ak模式端的搜索结果都具有与 A k A^k Ak相同的标记集。
一个简单的统计模型用于为每个仓库分配一个介于0和1之间的显著性的标记 t t t。假设 H 0 H_0 H0是从所有被索引的Stack Overflow代码示例中随机抽取生成搜索结果的模式端的零假设。在 H 0 H_0 H0下,结果集 R \mathcal{R} R中出现标记 t t t的次数 k k k将遵循二项零分布。试验次数 n n n为 ∣ R ∣ |\mathcal{R}| ∣R∣且零分布的成功概率 p ( t ) p(t) p(t)将是所有带标记t的被索引的Stack Overflow示例的分数。因此,零分布具有参数 ( n , p ( t ) ) (n,p(t)) (n,p(t))。该零分布近似于参数 μ = n p ( t ) \mu = np(t) μ=np(t)和 σ 2 = n p ( t ) ( 1 − p ( t ) ) \sigma^2=np(t)(1-p(t)) σ2=np(t)(1−p(t))的正态分布。该正态分布的累积分布函数用于对观察到的标记进行评分,对观察到频率高于零分布下的预期值的标记给更高的评分。
使用此技术,可以使用社区提供的Stack Overflow问题标签自动检测未知软件仓库的内容。在检查了GraphJet 仓库之后,标记如“数组,数组列表,枚举,列表,哈希表,随机数,循环,迭代器,文件输入流,…”收到高分,这些标签合理地描述了观察到的GraphJet仓库实现的图形算法的内容。
7 结论和未来工作
本文提出的搜索引擎可用于定位短源代码片段的重用。目前,索引数据包含了Stack Overflow的答案中的Java和Python编程语言所有代码示例。由于使用了一种与语言无关的算法,只需要依赖于编程语言的词法分析器,因此这组索引数据可以扩展到将来包含更多编程语言。同样,未来的工作也可以对网络进行爬行,以便为搜索索引中的更多内容编制索引。
CodeKoan搜索引擎可以在未来的开发工具中使用,并集成到现有的解决方案中。可能有益的应用程序是集成开发环境(IDES)的插件。这样的插件可以用来让程序员在编辑源代码时了解现有的解决方案,从而减少冗余代码的数量和用现有解决方案解决任务的脑力劳动。此外,这样的一个IDE插件可以为程序员提供源代码的文档,这些源代码重用已经有很好文档记录的代码示例。
CodeKoan还可以用于改进现有的持续集成(Continuous Integration,CI)系统。CI系统在版本控制下持续构建和测试源代码仓库。这些构建过程可能包含样式检查程序,如果新的源代码不符合(例如首选的缩进或标识符命名样式),这些样式检查程序会使构建失败。使用所提供的搜索引擎,可以通过检查源代码中的反模式来扩展CI系统。例如,如果检查过的仓库是一个库,其中不应访问任何文件,那么CodeKoan可以用于指定文件访问的反模式示例列表,如果出现这种情况,则会导致生成失败。
参考文献
[1] Sushil Bajracharya, Trung Ngo, Erik Linstead, Yimeng Dou, Paul Rigor, Pierre Baldi, and Cristina Lopes. 2006. Sourcerer: a search engine for open source code supporting structure-based search. In Companion to the 21st ACM SIGPLAN symposium on Object-oriented programming systems, languages, and applications. ACM, 681–682.
[2] Brenda S Baker. 1995. On finding duplication and near-duplication in large software systems. In Reverse Engineering, 1995., Proceedings of 2ndWorking Conference on. IEEE, 86–95.
[3] Anton Barua, Stephen W Thomas, and Ahmed E Hassan. 2014. What are developers talking about? an analysis of topics and trends in stack overflow. Empirical Software Engineering 19, 3 (2014), 619–654.
[4] Ira D Baxter, Andrew Yahin, Leonardo Moura, Marcelo Sant’Anna, and Lorraine Bier. 1998. Clone detection using abstract syntax trees. In Software Maintenance, 1998. Proceedings., International Conference on. IEEE, 368–377.
[5] Burton H Bloom. 1970. Space/time trade-offs in hash coding with allowable errors. Commun. ACM 13, 7 (1970), 422–426.
[6] Amiangshu Bosu, Christopher S Corley, Dustin Heaton, Debarshi Chatterji, Jeffrey C Carver, and Nicholas A Kraft. 2013. Building reputation in stackoverflow: an empirical investigation. In Proceedings of the 10th Working Conference on Mining Software Repositories. IEEE Press, 89–92.
[7] Joel Brandt, Philip J Guo, Joel Lewenstein, Mira Dontcheva, and Scott R Klemmer. 2009. Two studies of opportunistic programming: interleaving web foraging, learning, and writing code. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. ACM, 1589–1598.
[8] Kai Chen, Peng Liu, and Yingjun Zhang. 2014. Achieving accuracy and scalability simultaneously in detecting application clones on android markets. In Proceedings of the 36th International Conference on Software Engineering. ACM, 175–186.
[9] Jeanne Ferrante, Karl J Ottenstein, and Joe D Warren. 1987. The program dependence graph and its use in optimization. ACM Transactions on Programming Languages and Systems (TOPLAS) 9, 3 (1987), 319–349.
[10] William B Frakes and Kyo Kang. 2005. Software reuse research: Status and future. IEEE transactions on Software Engineering 31, 7 (2005), 529–536.
[11] Dan Gusfield. 1997. Algorithms on strings, trees and sequences: computer science and computational biology (12 ed.). Cambridge university press.
[12] Lingxiao Jiang, Ghassan Misherghi, Zhendong Su, and Stephane Glondu. 2007. Deckard: Scalable and accurate tree-based detection of code clones. In Proceedings of the 29th international conference on Software Engineering. IEEE Computer Society, 96–105.
[13] Dieter Jungnickel and D Jungnickel. 2008. Graphs, networks and algorithms. Springer.
[14] Toshihiro Kamiya, Shinji Kusumoto, and Katsuro Inoue. 2002. CCFinder: a multilinguistic token-based code clone detection system for large scale source code. IEEE Transactions on Software Engineering 28, 7 (2002), 654–670.
[15] Otávio Augusto Lazzarini Lemos, Sushil Krishna Bajracharya, Joel Ossher, Ricardo Santos Morla, Paulo Cesar Masiero, Pierre Baldi, and Cristina Videira Lopes. 2007. CodeGenie: using test-cases to search and reuse source code. In Proceedings of the twenty-second IEEE/ACM international conference on Automated software engineering. ACM, 525–526.
[16] Chao Liu, Chen Chen, Jiawei Han, and Philip S Yu. 2006. GPLAG: detection of software plagiarism by program dependence graph analysis. In Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 872–881.
[17] Seyed Mehdi Nasehi, Jonathan Sillito, Frank Maurer, and Chris Burns. 2012. What makes a good code example?: A study of programming Q&A in StackOverflow. In Software Maintenance (ICSM), 2012 28th IEEE International Conference on. IEEE, 25–34.
[18] Chris Parnin, Christoph Treude, Lars Grammel, and Margaret-Anne Storey. 2012. Crowd documentation: Exploring the coverage and the dynamics of API discussions on Stack Overflow. Georgia Institute of Technology, Tech. Rep (2012).
[19] Santanu Paul and Atul Prakash. 1994. A framework for source code search using program patterns. IEEE Transactions on Software Engineering 20, 6 (1994), 463–475.
[20] Lutz Prechelt, Guido Malpohl, and Michael Philippsen. 2002. Finding plagiarisms among a set of programs with JPlag. J. UCS 8, 11 (2002), 1016.
[21] Ronald C Read and Derek G Corneil. 1977. The graph isomorphism disease. Journal of Graph Theory 1, 4 (1977), 339–363.
[22] Chanchal Kumar Roy and James R Cordy. 2007. A survey on software clone detection research. Queen’s School of Computing TR 541, 115 (2007), 64–68.
[23] Chanchal K Roy and James R Cordy. 2009. A mutation/injection-based automatic framework for evaluating code clone detection tools. In Software Testing, Verification and Validation Workshops, 2009. ICSTW’09. International Conference on. IEEE, 157–166.
[24] Hitesh Sajnani, Vaibhav Saini, Jeffrey Svajlenko, Chanchal K Roy, and Cristina V Lopes. 2016. SourcererCC: Scaling code clone detection to big-code. In Software Engineering (ICSE), 2016 IEEE/ACM 38th International Conference on. IEEE, 1157– 1168.
[25] Robert J Shapiro. 2014. The US Software Industry As an Engine for Economic Growth and Employment. Georgetown McDonough School of Business Research Paper 2541673 (2014).
[26] Amit Singhal, Chris Buckley, and Mandar Mitra. 1996. Pivoted Document Length Normalization. ACM Press, 21–29.
[27] Kathryn T Stolee, Sebastian Elbaum, and Daniel Dobos. 2014. Solving the search for source code. ACM Transactions on Software Engineering and Methodology (TOSEM) 23, 3 (2014), 26.
[28] Medha Umarji, Susan Sim, and Crista Lopes. 2008. Archetypal internet-scale source code searching. Open source development, communities and quality (2008), 257–263.
[29] Carmine Vassallo, Sebastiano Panichella, Massimiliano Di Penta, and Gerardo Canfora. 2014. Codes: Mining source code descriptions from developers discussions. In Proceedings of the 22nd International Conference on Program Comprehension. ACM, 106–109.
[30] Andrew Walenstein, Mohammad El-Ramly, James R Cordy, William S Evans, Kiarash Mahdavi, Markus Pizka, Ganesan Ramalingam, and JürgenWolff von Gudenberg. 2007. Similarity in programs. In Dagstuhl Seminar Proceedings. Schloss Dagstuhl-Leibniz-Zentrum für Informatik.
[31] Niklaus Wirth. 1971. The programming language Pascal. Acta informatica 1, 1 (1971), 35–63.