机器学习:特征工程
文章目录
- 特征工程
- 常用的两种数据类型
- 特征归一化
- 数值型特征
- 类别型特征
- 序号编码的python实现
- 独热编码的python实现
特征工程
特征工程,顾名思义,是对原始数据进行一系列工程处理,将其提炼为特征,作为输入供算法和模型使用。从本质上来讲,特征工程是一个表示和展现数据的过程。在实际工作中,特征工程旨在去除原始数据中的杂质和冗余,设计更高效的特征以刻画求解的问题与预测模型之间的关系。
常用的两种数据类型
- 结构化数据。结构化数据类型可以看作关系型数据库的一张表,每列都有清晰的定义,包含了数值型、类别性两种基本类型;每一行数据表示一个样本的信息。
- 非结构化数据。非结构化数据主要包括文本、图像、音频、视频数据,其包含的信息无法用一个简单的数值表示,也没有清晰的类别定义,并且每条数据的大小各不相同。
特征归一化
目的:消除数据特征之间的量纲影响,需要对特征进行归一化处理,使得不同指标之间具有可比性。
数值型特征
对数值类型的特征做归一化可以将所有的特征都统一到一个大致相同的数值区间内。最常用的方法主要有以下两种:
-
线性函数归一化(Min-Max Scaling)
它对原始数据进行线性变换,使得结果映射到[0,1]的范围,实现对原始数据的等比缩放。归一化公式如下: X n o r m = X − X m i n X m a x − X m i n X_{norm}=\frac{X-X_{min}}{X_{max}-X_{min}} Xnorm=Xmax−XminX−Xmin其中X为原始数据, X m a x X_{max} Xmax和 X m i n X_{min} Xmin分别为数据最大值和最小值。 -
零均值归一化(Z-Score Normalization)
它会将原始数据映射到均值为0、标准差为1的分布上。具体来说,假设原始特征的均值为μ、标准差为σ,那么归一化公式定义为 z = x − μ σ z=\frac{x-\mu}{\sigma} z=σx−μ
以梯度下降中的归一化为例:
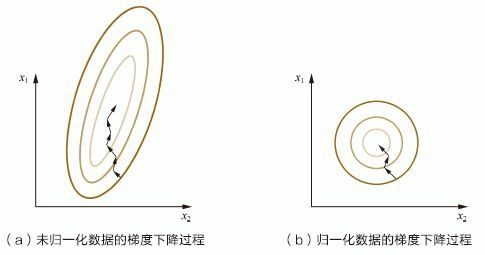
上图中 x 1 x_1 x1的取值范围大于 x 2 x_2 x2的取值范围,梯度下降过程中,学习速率相同的情况下, x 1 x_1 x1的更新速度大于 x 2 x_2 x2,需要较多的迭代才能找到最优解。如果将 x 1 x_1 x1和 x 2 x_2 x2归一化到相同的数值区间后,优化目标的等值图会变成图(b)中的圆形, x 1 x_1 x1和 x 2 x_2 x2的更新速度会变得更为一致,更容易通过梯度下降找到最优解。
当然,数据归一化并不是万能的。在实际应用中,通过梯度下降法求解的模型通常是需要归一化的,包括线性回归、逻辑回归、支持向量机、神经网络等模型。但对于决策树模型则并不适用,以C4.5为例,决策树在进行节点分裂时主要依据数据集D关于特征x的信息增益比,而信息增益比跟特征是否经过归一化是无关的,因为归一化并不会改变样本在特征x上的信息增益。
类别型特征
类别型特征(Categorical Feature)主要是指性别(男、女)、血型(A、B、AB、O)等只在有限选项内取值的特征。类别型特征原始输入通常是字符串形式,除了决策树等少数模型能直接处理字符串形式的输入,对于逻辑回归、支持向量机等模型来说,类别型特征必须经过处理转换成数值型特征才能正确工作。
对类别型特征转换的方式有以下三种:
- 序号编码(Ordinal Encoding)
序号编码通常用于处理类别间具有大小关系的数据。例如成绩,可以分为低、中、高三档,并且存在“高>中>低”的排序关系。序号编码会按照大小关系对类别型特征赋予一个数值ID,例如高表示为3、中表示为2、低表示为1,转换后依然保留了大小关系。 - 独热编码(One-hot Encoding)
独热编码通常用于处理列别见不具有大小关系的特征。例如血型,一共有4个取值(A型血、B型血、AB型血、O型血),独热编码会把血型变成一个4维稀疏向量,A型血表示为(1, 0, 0, 0),B型血表示为(0, 1, 0, 0),AB型表示为(0, 0,1, 0),O型血表示为(0, 0, 0, 1)。对于类别取值较多的情况下使用独热编码需要注意以下问题。
1)、使用稀疏向量来节省空间。在独热编码下。特征向量只有某一维取值为1,其他位置取值均为0.因此可以利用向量的稀疏表示有效地节省空间,并且日前大部分的算法均接受系数向量的输入形式。
2)、配合特征选择来降低维度。高维度特征会带来几方面的问题。一是在K近邻算法中,高维空间下两点之间的距离很难得到有效的衡量;二是在逻辑回归模型中,参数的数量会随着维度的增高而增加,容易引起过拟合问题;三是通常只有部分维度是对分类、预测有帮助,因此可以考虑配合特征选择来降低维度。 - 二进制编码(Binary Encoding)
二进制编码主要分为两步,先用先用序号编码给每个类别赋予一个类别ID,然后将类别ID对应的二进制编码作为结果。以A、B、AB、O血型为例,表1.1是二进制编码的过程。A型血的ID为1,二进制表示为001;B型血的ID为2,二进制表示为010;以此类推可以得到AB型血和O型血的二进制表示。可以看出,二进制编码本质上是利用二进制对ID进行哈希映射,最终得到0/1特征向量,且维数少于独热编码,节省了存储空间。
序号编码的python实现
Often features are not given as continuous values but categorical. For example a person could have features [“male”, “female”], [“from Europe”, “from US”, “from Asia”], [“uses Firefox”, “uses Chrome”, “uses Safari”, “uses Internet Explorer”]. Such features can be efficiently coded as integers, for instance [“male”, “from US”, “uses Internet Explorer”] could be expressed as [0, 1, 3] while [“female”, “from Asia”, “uses Chrome”] would be [1, 2, 1].
To convert categorical features to such integer codes, we can use the OrdinalEncoder. This estimator transforms each categorical feature to one new feature of integers (0 to n_categories - 1):
>>>
>>> enc = preprocessing.OrdinalEncoder()
>>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
>>> enc.fit(X)
OrdinalEncoder(categories='auto', dtype=<... 'numpy.float64'>)
>>> enc.transform([['female', 'from US', 'uses Safari']])
array([[0., 1., 1.]])
独热编码的python实现
1、利用sklearn.preprocessing.OneHotEncoder
先看看官方文档:
class sklearn.preprocessing.OneHotEncoder(n_values=None, categorical_features=None, categories=None, sparse=True, dtype=
, handle_unknown=’error’)[source]
参数说明:
categories : ‘auto’ or a list of lists/arrays of values, default=’auto’.
Categories (unique values) per feature: 每个特性的类别(唯一值):
‘auto’ : Determine categories automatically from the training data. “自动”:根据培训数据自动确定类别。
list : categories[i] holds the categories expected in the ith column. The passed categories should not mix strings and numeric values within a single feature, and should be sorted in case of numeric values. 包含第i列中期望的类别。传递的类别不应该在单个特性中混合字符串和数值,并且应该根据数值排序。
The used categories can be found in the categories_ attribute. 使用的类别可以在categories_属性中找到。
sparse : boolean, default=True
Will return sparse matrix if set True else will return an array.
dtype : number type, default=np.float
Desired dtype of output.
handle_unknown : ‘error’ or ‘ignore’, default=’error’.
Whether to raise an error or ignore if an unknown categorical feature is present during transform (default is to raise). When this parameter is set to ‘ignore’ and an unknown category is encountered during transform, the resulting one-hot encoded columns for this feature will be all zeros. In the inverse transform, an unknown category will be denoted as None.
如果转换过程中出现未知的分类特性,是引发错误,还是忽略(默认是引发)。当该参数设置为“ignore”,并且在转换过程中遇到未知类别时,该特性的一个热编码列将全部为零。在逆变换中,未知类别表示为None。
n_values : ‘auto’, int or array of ints, default=’auto’
Number of values per feature.
‘auto’ : determine value range from training data.
int : number of categorical values per feature.Each feature value should be in range(n_values)
array : n_values[i] is the number of categorical values in
X[:, i]. Each feature value should be in range(n_values[i])
categorical_features : ‘all’ or array of indices or mask, default=’all’
Specify what features are treated as categorical.
‘all’: All features are treated as categorical.
array of indices: Array of categorical feature indices.
mask: Array of length n_features and with dtype=bool.
Non-categorical features are always stacked to the right of the matrix.

链接:https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html
再来看看几个例子:
>>> enc = preprocessing.OneHotEncoder()
>>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
>>> enc.fit(X)
OneHotEncoder(categorical_features=None, categories=None,
dtype=<... 'numpy.float64'>, handle_unknown='error',
n_values=None, sparse=True)
>>> enc.transform([['female', 'from US', 'uses Safari'],
... ['male', 'from Europe', 'uses Safari']]).toarray()
array([[1., 0., 0., 1., 0., 1.],
[0., 1., 1., 0., 0., 1.]])
这个例子没有定义categories参数,因此默认自动生成categories_属性:
>>> enc.categories_
[array(['female', 'male'], dtype=object), array(['from Europe', 'from US'], dtype=object), array(['uses Firefox', 'uses Safari'], dtype=object)]
现在我们自定义categories:
>>> genders = ['female', 'male']
>>> locations = ['from Africa', 'from Asia', 'from Europe', 'from US']
>>> browsers = ['uses Chrome', 'uses Firefox', 'uses IE', 'uses Safari']
>>> enc = preprocessing.OneHotEncoder(categories=[genders, locations, browsers])
看看结果,会生成10新的变量(handel_known=‘error’):
>>> # Note that for there are missing categorical values for the 2nd and 3rd
>>> # feature
>>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
>>> enc.fit(X)
OneHotEncoder(categorical_features=None,
categories=[...],
dtype=<... 'numpy.float64'>, handle_unknown='error',
n_values=None, sparse=True)
>>> enc.transform([['female', 'from Asia', 'uses Chrome']]).toarray()
array([[1., 0., 0., 1., 0., 0., 1., 0., 0., 0.]])
如果训练数据可能缺少分类特性,通常最好指定handle_unknown=‘ignore’,而不是像上面那样手动设置类别。当指定handle_unknown=‘ignore’,并且在转换过程中遇到未知类别时,不会产生错误,但是为该特性生成的一热编码列将全部为零(handle_unknown='ignore’只支持一热编码):
>>> enc = preprocessing.OneHotEncoder(handle_unknown='ignore')
>>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']]
>>> enc.fit(X)
OneHotEncoder(categorical_features=None, categories=None,
dtype=<... 'numpy.float64'>, handle_unknown='ignore',
n_values=None, sparse=True)
>>> enc.transform([['female', 'from Asia', 'uses Chrome']]).toarray()
array([[1., 0., 0., 0., 0., 0.]])
另一个例子:
>>> from sklearn.preprocessing import OneHotEncoder
>>> enc = OneHotEncoder(handle_unknown='ignore')
>>> X = [['Male', 1], ['Female', 3], ['Female', 2]]
>>> enc.fit(X)
...
OneHotEncoder(categorical_features=None, categories=None,
dtype=<... 'numpy.float64'>, handle_unknown='ignore',
n_values=None, sparse=True)
>>> enc.categories_
[array(['Female', 'Male'], dtype=object), array([1, 2, 3], dtype=object)]
>>> enc.transform([['Female', 1], ['Male', 4]]).toarray()
array([[1., 0., 1., 0., 0.],
[0., 1., 0., 0., 0.]])
>>> enc.inverse_transform([[0, 1, 1, 0, 0], [0, 0, 0, 1, 0]])
array([['Male', 1],
[None, 2]], dtype=object)
>>> enc.get_feature_names()
array(['x0_Female', 'x0_Male', 'x1_1', 'x1_2', 'x1_3'], dtype=object)
2、利用pd.get_dummies
(将类别变量转换为one-hot编码,使用pandas方法实现,相当于sklearn的one-hot编码)
官方文档
pandas.get_dummies(data, prefix=None, prefix_sep=’_’, dummy_na=False, columns=None, sparse=False, drop_first=False, dtype=None)[source]
data:可以是数组类型,Series类型,DataFrame类型
prefix:可以字符串,字符串列表,或字符串的字典类型,默认为None。将data的列名映射到prefix的字符串或者字典;
drop_first:布尔型,默认为False,指是否删除第一列
离散特征的编码分为两种情况:
1、离散特征的取值之间没有大小的意义,比如color:[red,blue],那么就使用one-hot编码
2、离散特征的取值有大小的意义,比如size:[X,XL,XXL],那么就使用数值的映射{X:1,XL:2,XXL:3}
使用pandas可以很方便的对离散型特征进行one-hot编码.
例子:
import pandas as pd
import numpy as np
s=pd.Series(list('abca'))
s0=pd.get_dummies(s)
print(s)
print(s0)
'''
0 a
1 b
2 c
3 a
dtype: object
a b c
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
'''
s1=['a','b',np.nan]
print(s1)
print(pd.get_dummies(s1))
print(pd.get_dummies(s1,dummy_na=True))
'''
['a', 'b', nan]
a b
0 1 0
1 0 1
2 0 0
a b NaN
0 1 0 0
1 0 1 0
2 0 0 1
'''
df=pd.DataFrame({'A':['a','b','a'],'B':['b','a','c'],'C':[1,2,3]})
print(df)
print(pd.get_dummies(df))
print(pd.get_dummies(df,prefix=['col1','col2']))
'''
A B C
0 a b 1
1 b a 2
2 a c 3
C A_a A_b B_a B_b B_c
0 1 1 0 0 1 0
1 2 0 1 1 0 0
2 3 1 0 0 0 1
C col1_a col1_b col2_a col2_b col2_c
0 1 1 0 0 1 0
1 2 0 1 1 0 0
2 3 1 0 0 0 1
'''
print(pd.get_dummies(pd.Series(list('abcaa'))))
print(pd.get_dummies(pd.Series(list('abcaa')),drop_first=True))
'''
a b c
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
4 1 0 0
b c
0 0 0
1 1 0
2 0 1
3 0 0
4 0 0
'''
print(pd.get_dummies(pd.Series(list('abx')),dtype=float))
'''
a b x
0 1.0 0.0 0.0
1 0.0 1.0 0.0
2 0.0 0.0 1.0
'''
例子:
import pandas as pd
df=pd.DataFrame([['green','A'],
['red','B'],
['blue','A']])
df.columns=['color','class']
print(df)
print(pd.get_dummies(df))
'''
color class
0 green A
1 red B
2 blue A
color_blue color_green color_red class_A class_B
0 0 1 0 1 0
1 0 0 1 0 1
2 1 0 0 1 0
'''