《Dual Attention Networks for Multimodal Reasoning and Matching》
Dual Attention Networks for Multimodal Reasoning and Matching
CVPR 2017
图文匹配终极问题是整个Text与整个Image的匹配问题,但是这个问题比较难以解决,所以一个最基本的想法就是把这个问题拆分开来,Text由不同的单词构成,Image由不同的区域构成,如果能把Text的单词与Image的区域进行一个匹配,那么这个问题就会变得比较简单。
一个基本的思路就是使用Attention机制,在网络中自动匹配文本单词与图像区域进行匹配。作者引用了两种Attention机制,分别是:Visual Attention以及Text Attention。
一、Introduction
文章亮点:
1.文章提出双重attention机制:Visual Attention以及Text Attention,用triplet loss度量文本和图像之间的相似性。
2.训练出end-to-end模型
3.同时解决了VQA与Image-Text Matching的问题,提出了r-DAN与m-DAN模型
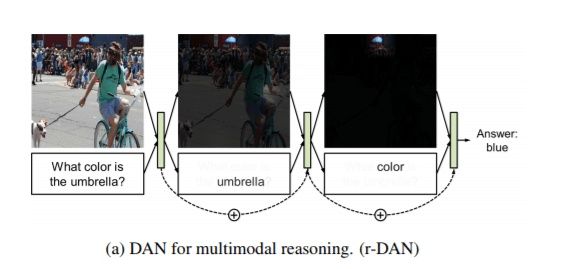
关注图片中“伞”和文本中“color”
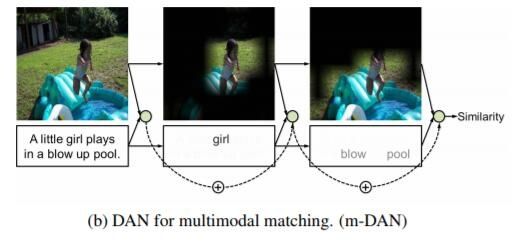
关注语义相同的特定区域和单词,如图片中女孩和“girl”的相似度
二、Model
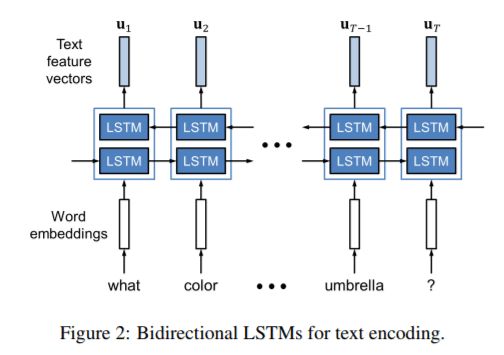
1.文本特征:将输入文本one-hot向量做word embedding,然后再用Bi-LSTM来提取文本的特征,文本的特征为N个512维的向量,最后将N个向量做平均得到初始化的文本特征向量 u_{0}
![]()
2.图像特征:将图像resize成448x448的大小,然后再利用152层的resnet,采用res5c卷积层的feature map,在这个feature map上面做pooling得到N个(image region的个数)2048维的特征向量,然后将N个2048维的特征向量取平均并乘一个权重矩阵,然后再用tanh激活得到初始化的图像特征 v_{0}
![]()
3.初始化记忆向量(memory vector):
将初始化的文本特征向量 u_{0} 与初始化的图像特征 v_{0} 做点乘,得到初始化的记忆向量。
文中用了两种Attention机制,分别是:Visual Attention以及Text Attention。
这两种Attention都是使用前面一种的状态,决定下一个状态需要Attention的"位置"。
4.双重attention
文本attention:
将初始化的文本特征向量query(在r-DAN中为前一层的memory vector即前一层图像特征与文本特征的点乘)和文本的特征key
![]()
用两层前馈神经网络(FNN)相连,然后再用tanh激活并做点乘,然后用softmax做归一化得到权重向量(N维向量),利用权重向量将N个512维的向量做加权平均,得到文本attention向量。
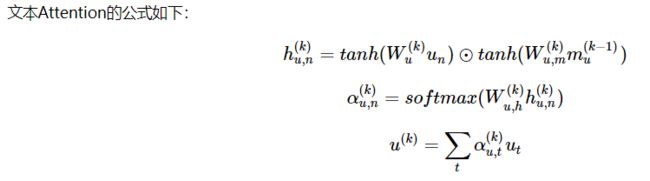
图像attention:
分别将初始化的图像特征向量(在r-DAN中为前一层的memory vector即前一层图像特征与文本特征的点乘)和图像的特征
![]()
用两层前馈神经网络(FNN)相连,然后再用tanh激活并做点乘,然后用softmax做归一化得到权重向量(N维向量),利用权重向量将N个2048维的向量做加权平均,然后再乘以一个权重矩阵,最后再用tanh进行激活,得到图像attention向量。

两种Attention的步长K是超参,作者在实验中证明K=2效果是最好的。
5. VQA & Image-Text Matching
文中作者解决了两种不同的问题,都用到了前面的Attention机制,但是不同的问题,提出了r-DAN(用于VQA)和m-DAN(用于Image-Text Matching)两种模型
A. Visual Question and Answer
VQA本质上为分类问题,将图像attention特征和文本attention特征融合得到memory vector,做分类任务。
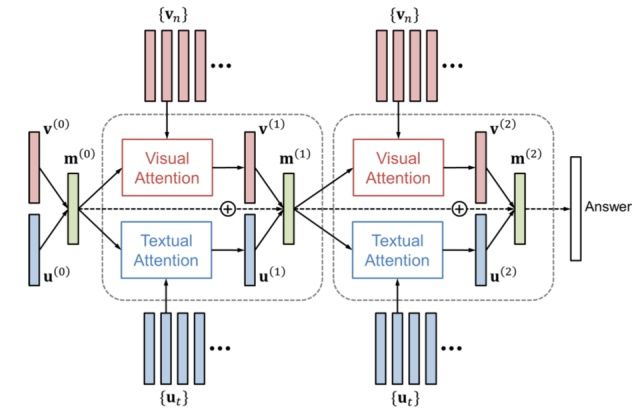

B. Image-Text Matching
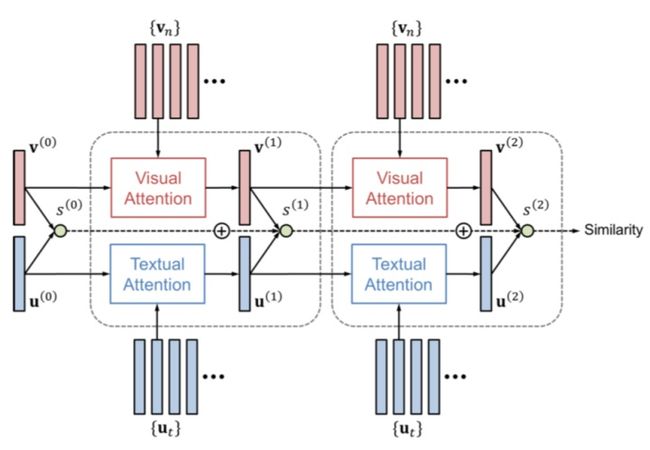
图文匹配问题与VQA最大的不同就是,他要解决的是一个Rank问题,所以需要比对两种特征之间的距离,因此就不能共享一个相同的Memory Vector。
对应Image和Text都有自己的Memory Vector, 他们的计算公式如下:
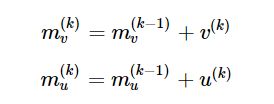
每一步的Attention都会产生一个匹配的向量,这里做的是把所有的S进行相加。
6.Loss Function
Triplet Loss(文章中没有提到hard的思想,负样本应该是在minibatch里面随机选的)
相似度S为内积:
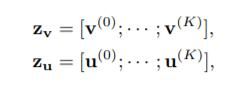
![]()
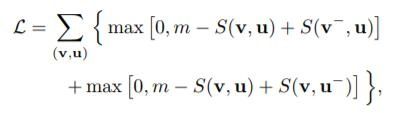
参考文章:
http://www.wangqingbaidu.cn/category/Papers/www.wangqingbaidu.cn