【NLP】李宏毅老师ELMO, BERT, GPT讲解【笔记】
零、引例
首先来看一个例子,下面有四句话,每一句话中都有“bank”这个单词:
1、Have you paid that money to the bank yet ?
2、It is safest to deposit your money in the bank .
3、The victim was found lying dead on the river bank .
4、They stood on the river bank to fish.
但“bank”在其前两句话中的意思是“银行”,在后两句话中的意思是“河畔”。
在做word embeding的时候,我们当然希望“bank”这一种token能够有两种embeding结果。
Q:那我们能不能标记一词多义的形式呢?
A:不太现实,首先是词很多,而且“bank”也不止有2种意思,下面这句话:The hospital has its own blood bank.这里“bank”有人认为是第三种意思“库”,也有人认为是“银行”的延伸意思,所以也难界定到底有几种意思。
此时我们需要根据上下文来计算对应单词的embedding结果,这种技术称之为Contextualized Word Embedding 。
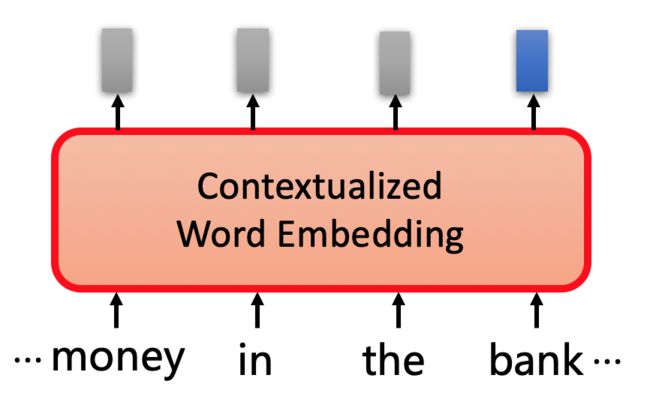

如果根据上下文来进行embedding,那么同样是“bank”,就会产生不同的结果。
一、ELMO
实现Contextualized Word Embedding技术的模型为ELMO模型(Embeddings from Language Model )
ELMO是基于RNN的语言模型。例如现在有一句话: “潮水 退了 就 知道 誰 沒穿 褲子”,需要找到“退了”这个词的编码,就可以根据这个词的上下文来获取。

“退了”这个词经过RNN层的输出之后得到前文对它的编码,“退了”这个词经过反向的RNN层的输出作为下文对它的编码,之后进行连接得到“退了”这个词的整个编码。
但使用深度的RNN结构,就会产生比较多的RNN层输出,这时候ELMO选择全部利用:
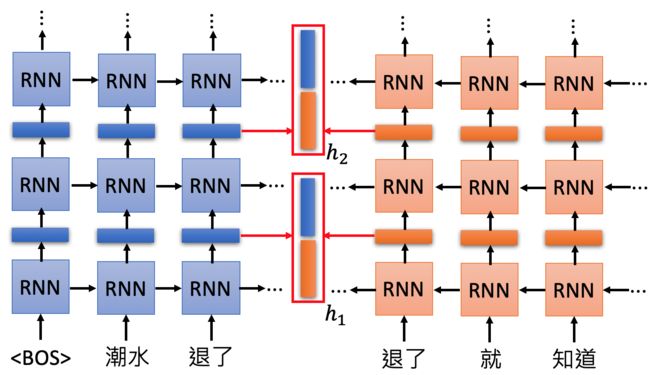

每一层都会给出一个Embedding(上图展示了两层),ELMO把这些加起来生成一个Embedding(上图的蓝色向量),加的时候需要的参数根据模型学出来。
二、BERT
Bidirectional Encoder Representations from Transformers (BERT)
BERT = Encoder of Transformer ;BERT是Transformer中的Encoder,不需要label,只要一些语料,就可以来训练BERT。
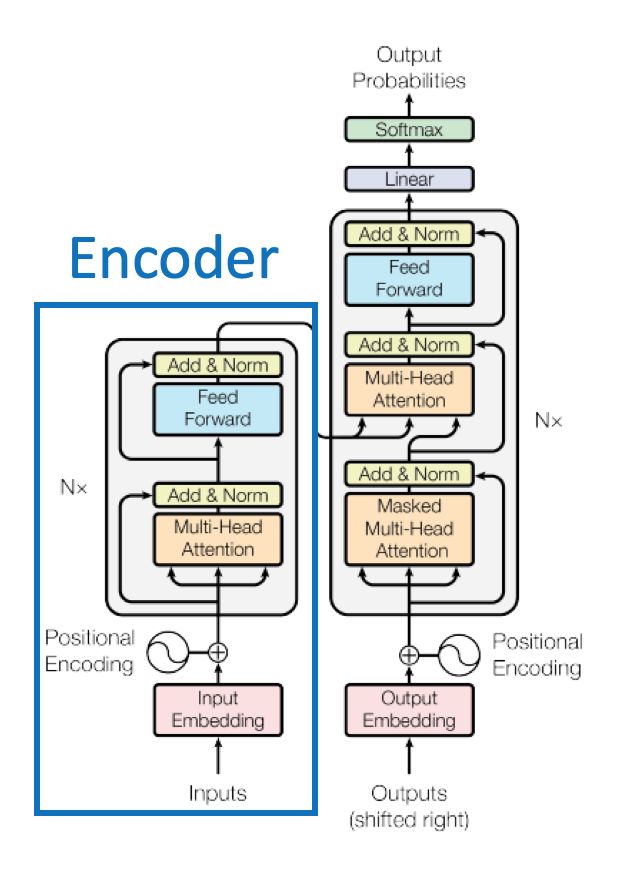
BERT的作用就是通过给定的语料,生成每个词对应的Embedding向量(BERT训练中文的时候,用每个字作为单位可能会更好)。
中文的词语很难穷举,但字的穷举相对容易
2.1 如何训练BERT?
训练BERT的方法分为2种:
1、Masked LM
2、Next Sentence Prediction
2.1.1 Masked LM
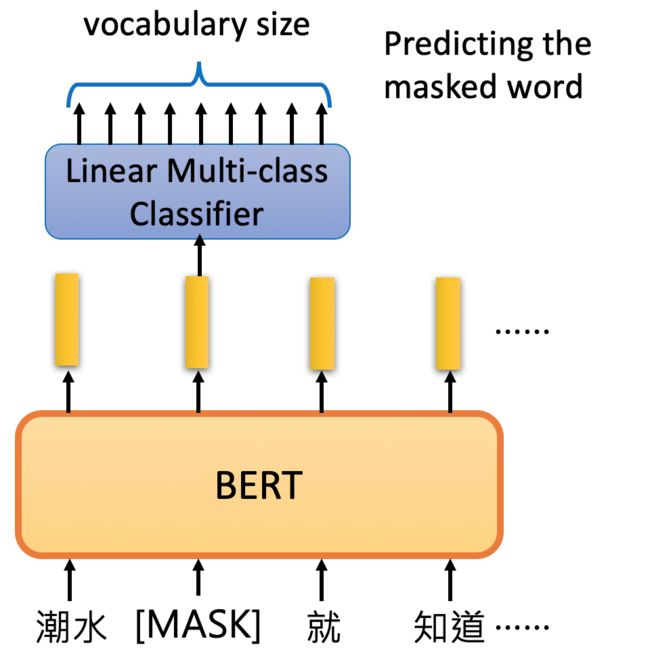
在这种方法里面,会以一定的概率将一个词用[MASK]替代,然后往里面填充相应的编码,如果填进去并没有违和感,则表示预测准确。
2.1.2 Next Sentence Prediction
给出两个句子,BERT判断两个句子是否是接在一起的。
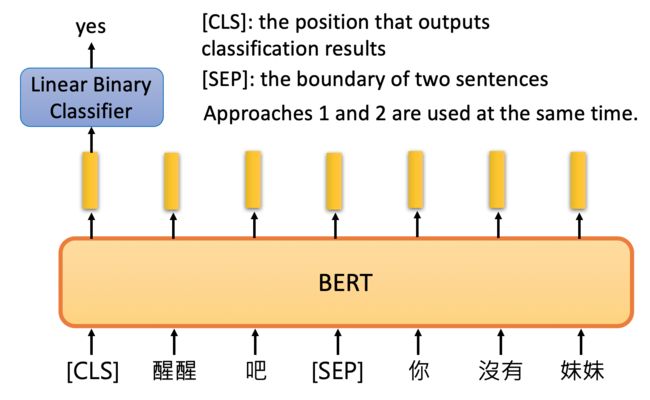
[CLS]放在句子开头,用于存储判断的结果。
方法1和方法2的方法在BERT中是同时使用的。
2.2 如何利用BERT?
BERT论文中给出的例子是将BERT和接下来的任务一起训练的。
例1:分类
Input: single sentence,
output: class
Example: Sentiment analysis (our HW),Document Classification
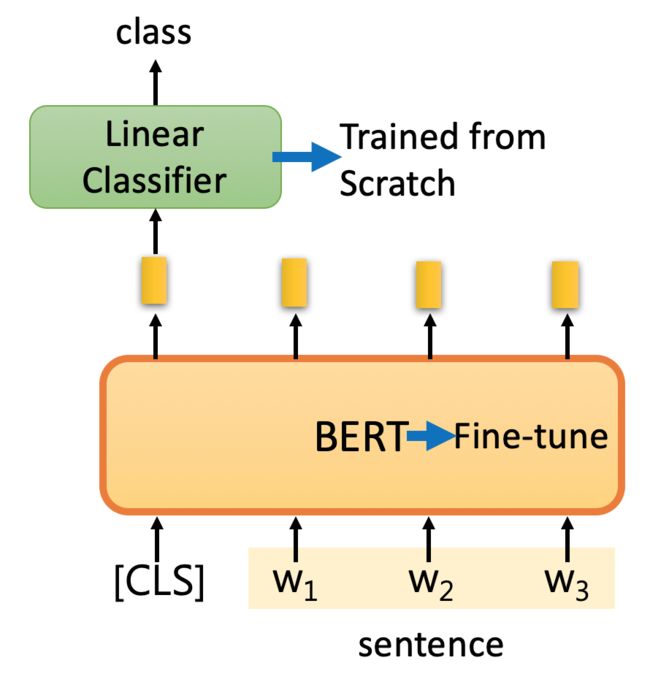
对于分类任务可以给句子前加一个[CLS],然后在进行线性的分类。也可以加上标签训练线性分类起,同时对BERT进行微调(Fine-tune)。
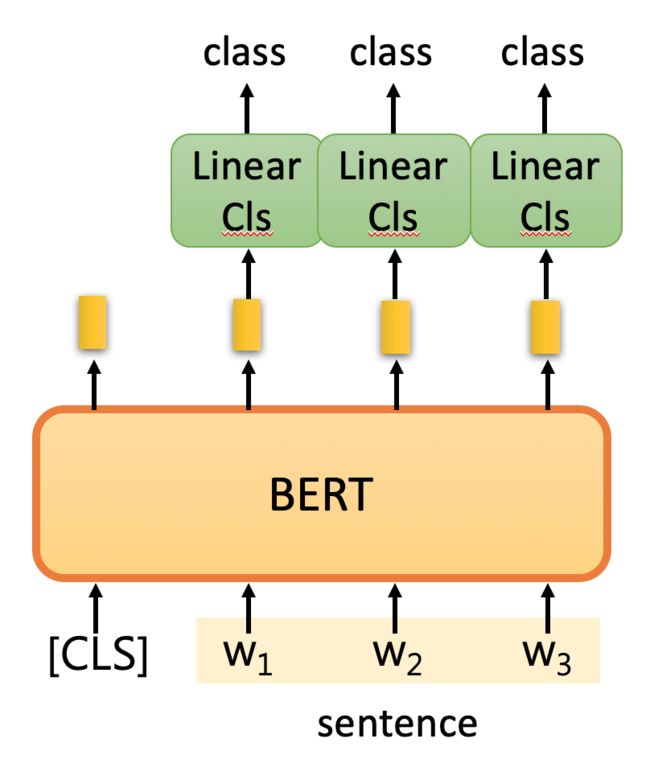
例2:词性标注
Input: single sentence,
output: class of each word
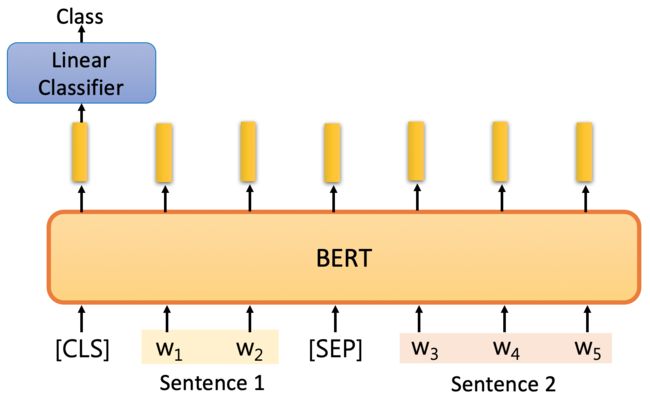
例3:自然语言推理
Input: two sentences,
output: class
Example: Natural Language Inference
例4:阅读理解

最后一个例子是抽取式QA,抽取式的意思是输入一个原文和问题,输出两个整数start和end,代表答案在原文中的起始位置和结束位置,两个位置中间的结果就是答案
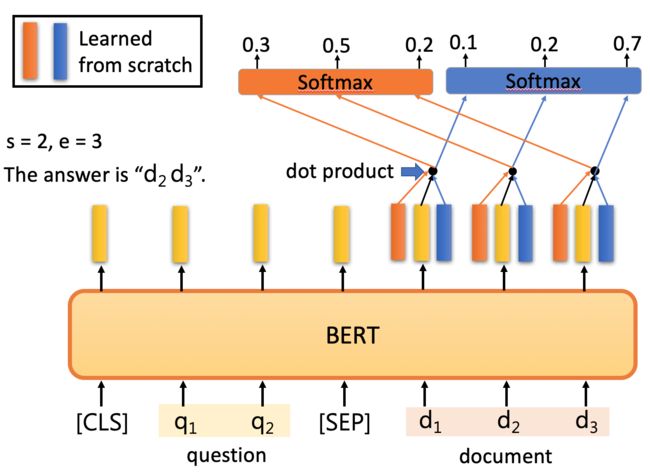
具体怎么解决刚才的QA问题呢?把问题 - 分隔符 - 原文输入到BERT中,每一个单词输出一个黄颜色的embedding,这里还需要学习两个(一个橙色一个蓝色)的向量,这两个向量分别与原文中每个单词对应的embedding进行点乘,经过softmax之后得到输出最高的位置。正常情况下start <= end,但如果start > end的话,说明是矛盾的case,此题无解。
三、GPT
GPT:Generative Pre-Training
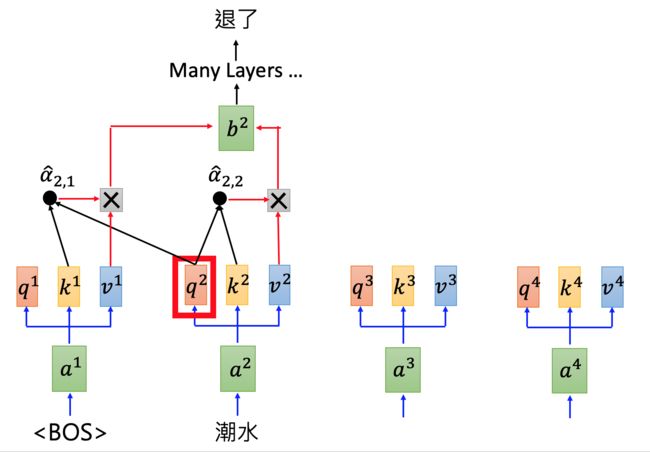
GPT-2是Transformer的Decoder部分,输入一个句子中的上一个词,我们希望模型可以得到句子中的下一个词。
根据“潮水”预测下一个词语“退了”:
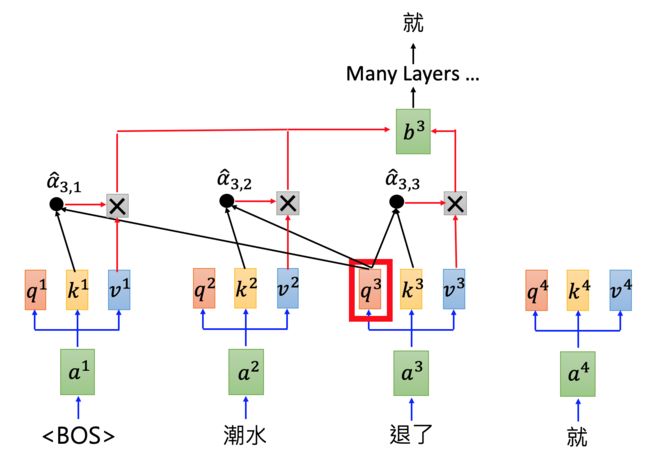
根据“退了”预测下一个词:
、
由于GPT-2的模型非常巨大,它在很多任务上都达到了惊人的结果,甚至可以做到zero-shot learning(简单来说就是模型的迁移能力非常好),如阅读理解任务,不需要任何阅读理解的训练集,就可以得到很好的结果。
参考资料:
视频:https://www.bilibili.com/video/av56235038
ppt下载地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML19.html
https://www.jianshu.com/p/f4ed3a7bec7c