两种基本的数据访问途径:全扫描或者索引扫描。
create table t1 as
select trunc((rownum-1)/100) id,
rpad(rownum,100) t_pad
from dba_source
where rownum<=10000;
create index t1_idx1 on t1(id);
create table t2 as
select mod(rownum,100) id,
rpad(rownum,100) t_pad
from dba_source
where rownum<=10000;
create index t2_idx1 on t2(id);
-- exec dbms_stats.gather_table_stats(user,'t2',method_opt=>'FOR ALL COLUMNS SIZE 1',cascade => TRUE);
SELECT * FROM T1 WHERE rownum<100;
SELECT * FROM T2 WHERE rownum<100;
select count(*) ct from t1 where id=1;
explain plan for
select count(*) ct from t1 where id=1;
select * from table(dbms_xplan.display);
select count(*) ct from t2 where id=1;
explain plan for
select count(*) ct from t2 where id=1;
select * from table(dbms_xplan.display);
上面这个例子展示了基于数据存储方式的不同优化器的执行计划选择也可能不同。
Oracle 12c改进了优化器,使得两种计划都可以使用索引。
全扫描与舍弃
全扫描是否为高效取决于需要访问的数据块个数以及最终的结果集行数。如上例所示,数据的存储方式在决策过程中扮演了重要的角色。此外,全扫描是否为高效选择的另一个关键因素是舍弃。舍弃的行是那些通过筛选谓语验证,被证明是不符合筛选条件后从最终的结果集中剔除的数据行。
--表t1和t2的数据行和数据块统计信息
select table_name, num_rows, blocks
from user_tables
where table_name = 'T1';
select table_name, num_rows, blocks
from user_tables
where table_name = 'T2';
全扫描与多块读取
全扫描将会时行多块读取,也就是一个单独的IO调用将会请求多个块而不仅仅是一个。请求的数据块数量可以从1个到db_file_multiblock_read_count参数所指定的数目范围之间的任意个。
全扫描与高水位
当对全扫描多块读取调用时,oracle将最多读取到位于表中高水位线的数据块。高水位线标出了表中最后一块有数据写入的数据块。为了保持技术上的正确性,这实际上应该称为“底”高水位线。

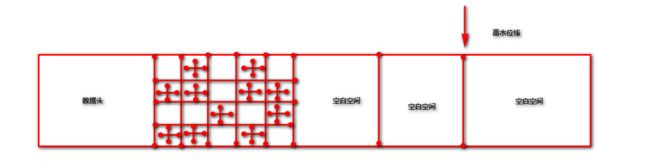
--列出分配的块数
select blocks from user_segments where segment_name = 'T2';
--列出多少块包含数据
select count(distinct(dbms_rowid.rowid_block_number(rowid))) block_ct
from T2;
--列出这个表的最低和最高块数
select min(dbms_rowid.rowid_block_number(rowid)) min_blk,
max(dbms_rowid.rowid_block_number(rowid)) max_blk
from T2;
下面证明:全表扫描是正确的执行了计划选择,读取额外的空块所带来的成本也可能严重降低性能。对于频繁加载和清除的表,你可能发现响应时间会变慢。
SQL> delete from T2;
--列出多少块包含数据
SQL> select count(distinct(dbms_rowid.rowid_block_number(rowid))) block_ct from t2;
--执行全表扫描,注意逻辑读
SQL> set autotrace traceonly
SQL> select * from T2;
SQL> set autotrace off
SQL> truncate table T2;
SQL> set autotrace on
SQL> select * from T2;
索引扫描访问方法
默认的索引是B-树索引。
索引建立在表中的一个或多个列或者是表的表达式上,将列值和行编号一起存储。
行编号是唯一标记表中行的伪列。
行编号解码
column filen format a50 head 'file name';
select e.rowid,
(select file_name
from dba_data_files
where file_id =
dbms_rowid.rowid_to_absolute_fno(e.rowid, user, 'EMPLOYEES')) filen,
dbms_rowid.rowid_block_number(e.rowid) block_no,
dbms_rowid.rowid_row_number(e.rowid) row_no
from employees e
where e.email = '[email protected]';
--select * from employees;
行编号是物理表中的行数据的内部地址,包含两个地址,其一是指向数据表中包含该行的块所丰放数据文件的地址,另一个可以直接定位到数据行自身的这一行在数据块中的地址。
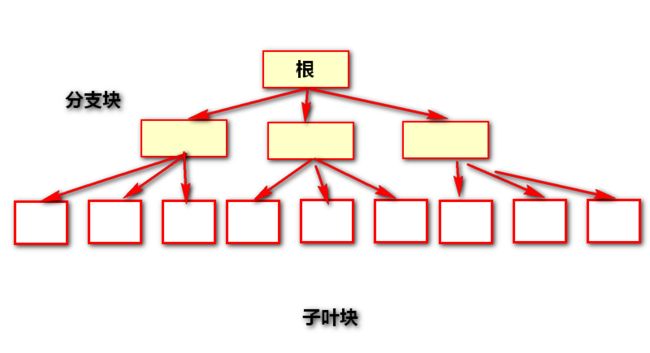

随着新行加入表中,新的索引条目也会加到块中,直到新的条目再也加不进去为止。此时oracle就会分配两个新的索引块并将所有索引条目加入这个两新的叶子块中。之前被填满的那个单独的根数据块现在就替代为指向两个新数据块的指针。这个指针由指向新索引块的相对数据块地址(relative block address, RBA)和表明相关叶子块中最低索引值(即排序顺序中的最小值)的值组成。利用根数据块中的这个信息,oracle就可以搜索索引以找到存有所所需值的特定叶子块。到止前为止,这个索引的高度为2,blevel为1。
随着时间的推进,更多的行插入到表中,索引条目被加入刚才创建的两个叶子数据块中。当两个叶子块被填满之后,oracle将会增加一个新的叶子块并为它分配介于己填满的块与新叶子块之间的索引条目。每次一个叶子数据块填满并分裂之后,就会为这个新的叶子块增加一个新指针到根数据块中。最终,根数据块也被填满了,然后再重复将根数据块分裂为两个新的分支块,当发生这样的分裂时,索引的高度将会增加为3而blevel变为2。
现在,随着新的索引条目的加入,叶子数据块将会被填满并分裂,但不是添加一个新指针到根数据块中,而是将指针加到相应的分支数据块中。最终,分支数据块也将被填满并分裂,这时又将有一个新索引条目加入到根数据块中。随着这些过程的不断继续,最后根数据块又会被填满并分裂,再一次增加索引的高度。记住唯一引起索引高度增加的就是当根数据块分裂的时候。由于这一点,所有叶子数据块到根数块的距离都是一样的。一定要保持索引的高度是保持平衡的。
准备测试数据
drop table t1;
create table t1 as
select trunc((rownum-1)/100) id,
rpad(rownum,100) t_pad
from dba_source
where rownum<=10000;
create index t1_idx1 on t1(id);
drop table t2;
create table t2 as
select mod(rownum,100) id,
rpad(rownum,100) t_pad
from dba_source
where rownum<=10000;
create index t2_idx1 on t2(id);
commit;
SELECT * FROM T1 WHERE rownum<100;
SELECT * FROM T2 WHERE rownum<100;
![随机与顺序载入数据行的对比图]](http://upload-images.jianshu.io/upload_images/2026576-5d7b9990fe112018.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)
索引聚族因子
select t.TABLE_NAME || '.' || i.INDEX_NAME idx_name,
i.CLUSTERING_FACTOR,
t.BLOCKS,
t.NUM_ROWS
from user_indexes i, user_tables t
where i.TABLE_NAME = t.TABLE_NAME
and t.TABLE_NAME in ('T1', 'T2')
order by t.TABLE_NAME, i.INDEX_NAME;

计算索引的聚簇因子
create index EMP_DEPARTMENT_IX on employees(DEPARTMENT_ID);
select t.TABLE_NAME || '.' || i.INDEX_NAME idx_name,
i.CLUSTERING_FACTOR,
t.BLOCKS,
t.NUM_ROWS
from all_indexes i, all_tables t
where i.TABLE_NAME = t.TABLE_NAME
and t.TABLE_NAME = 'EMPLOYEES'
and t.owner = 'SCOTT'
and i.INDEX_NAME = 'EMP_DEPARTMENT_IX'
order by t.TABLE_NAME, i.INDEX_NAME;
select department_id,
last_name,
blk_no,
lag(blk_no, 1, blk_no) over(order by department_id) prev_blk_no,
case
when blk_no != lag(blk_no, 1, blk_no)
over(order by department_id) or rownum = 1 then
'*** +1'
else
null
end cluf_ct
from (select department_id,
last_name,
dbms_rowid.rowid_block_number(rowid) blk_no
from SCOTT.Employees
where department_id is not null
order by department_id);
在oracle 12版本中,可以定义一个新的统计信息收集偏好-TABLE_CACHED_BLOCKS。
过程如下:
-- conn sys/0529 as sysdba;
dbms_stats.set_table_prefs(
ownname=>'SCOTT',
tabname=>'EMPLOYEES',
pname=>'TABLE_CACHED_BLOCKS',
pvalue=>50
);
oracle 12c执行
exec dbms_stats.set_table_prefs(user,'T2',pname => 'TABLE_CACHED_BLOCKS',pvalue => 255);
exec dbms_stats.gather_table_stats(user,'T2');
select t.TABLE_NAME || '.' || i.INDEX_NAME idx_name,
i.CLUSTERING_FACTOR,
t.BLOCKS,
t.NUM_ROWS
from user_indexes i, user_tables t
where i.TABLE_NAME = t.TABLE_NAME
and t.TABLE_NAME in ('T1', 'T2')
order by t.TABLE_NAME, i.INDEX_NAME;
聚簇因子与表中数据相关而不是与索引相关。因此,重建索引对优化器不有任何影响。
唯一索引
当谓语中包含使用unique或primary key索引的列作为条件时就会选用索引唯一扫描。这种类型的索引能够保证对于某个特定的值只返回一行数据。这种情况下,索引结构将会被从根到叶子进行遍历直到某个条目,取出其行编号,然后使用这个行编号访问包含这一行的表数据块。计划中的TABLE ACCESS BY INDEX ROWID步骤表明了对表数据块的访问。
唯一索引扫描
SQL> set autotrace off
SQL> set autotrace traceonly
SQL> select * from employees where employee_id=60;
范围索引扫描
当谓语中包含将会返回一定范围数据的条件时,就会选用索引范围扫描。索引可以是唯一的或者是不唯一的。
指定的条件可以使用如<、>、LIKE、BETWEEN和=等运算符。
范围索引扫描
SQL> set autotrace traceonly
SQL> select * from employees where department_id>60;
范围扫描将会从根数据块开始到第一个包含符合条件的条目所在的叶子数据块来遍历索引结构。再从那一点开始,从索引条目中取出行编号然后取出相应的表数据块(通过索引行编号访问数据表)。在第一行取出来之后,之前的叶子索引块将再一次被访问并读取下一个索引条目来获取下一个行编号。这种索引叶子块和表数据块之间的反复来回将会不断持续直到所有匹配的索引条目都被读出。因此,所需访问数据块的次数为索引中的分支块数加上符合条件的索引条目乖以2.
如果返回5行数据且blevel为3,则总的需要访问的数据块次数将是: 5行*2+3=13
注意: 有时使用索引范围扫描的谓语实际上没有使用,如果通配符开如"%abc"的like运算符,优化器将不会选用该列上的索引范围扫描,因为条件太宽泛了。另一情况就是使用了组合索引中的非引导列。
索引范围扫描可以使用一个升序排列的索引(默认是升序的)来返回降序排列的数据行。
使用索引扫描来避免排序
set autotrace off;
set autotrace traceonly;
--使用索引扫描来避免排序
select *
from employees
where department_id in (90, 60, 88)
order by department_id desc;
已选择10行。
执行计划
----------------------------------------------------------
Plan hash value: 3707994525
---------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9 | 369 |2 (0)| 00:00:01 |
| 1 | INLIST ITERATOR | | | | | |
| 2 | TABLE ACCESS BY INDEX ROWID | EMPLOYEES | 9 | 369 |2 (0)| 00:00:01 |
|* 3 | INDEX RANGE SCAN DESCENDING| EMP_DEPARTMENT_IX | 9 | |1 (0)| 00:00:01 |
INDEX RANGE SCAN DESCENDING,索引条目以相返的顺序进行读取,避免了再做单独的排序运算。
索引全扫描
好几种情况都会使用选择索引全扫描,包括:当没有谓语但是所需的列可以通过其中的一列的索引获取,谓语中包含一个位于索引中非引导列上的条件,或者数据可以通过一个排过序的索引来获取并且会省去单独的排序步骤。
set autotrace off;
set autotrace traceonly;
-- 当没有谓语但是所需的列可以通过其中的一列的索引获取
create index EMP_EMAIL_UK on employees(EMAIL);
select email from employees;
--谓语中包含一个位于索引中非引导列上的条件
select first_name,last_name from employees where first_name like 'Li%';
--通过一个排过序的索引来获取并且会省去单独的排序步骤。
create index emp_emp_id_pk on employees(employee_id);
select * from employees order by employee_id;
select * from employees order by employee_id desc;
索引全扫描求最小、最大值的最优方法
--create index emp_dept_id_idx on employees(department_id);
select min(department_id) from employees;
select max(department_id) from employees;
select min(department_id),max(department_id) from employees;
select (select min(department_id) from employees) min_id,
(select max(department_id) from employees) max_id
from dual;
索引跳跃扫描
当谓语中包含位于索引非引导列上的条件,且引导列的值唯一时会选择索引跳跃扫描。
set autotrace off;
set autotrace traceonly;
drop table employees2;
create table employees2 as select * from employees;
create index emp_jobfname_ix on employees2(job_id,first_name,salary);
select * from employees2 where first_name='Polly';
select /*+ full(employees2) */ * from employees2 where first_name='Polly';
select count(distinct job_id) ct from employees;
索引快速全扫描
索引快速全扫描更像全表扫描而不像其它类型的索引扫描。当选用索引快速全扫描时,所有索引块都将通过多块读取来进行。这种类型的索引扫描是用来在查询列表中所有字段都包含在索引中并且索引中至少有一列具有非空约束时替代全表扫描的。这种情况下,数据通过索引访问而不必访问表数据块。
索引快速全扫描
create index emp2_email_idx on employees2(email);
alter table employees2 modify (email null);
select email from employees2;
alter table employees2 modify (email not null);
select email from employees2;
选择快速合扫描运算的依据是包含非空约束,如果没有这个约束,将会选择全表扫描运算。
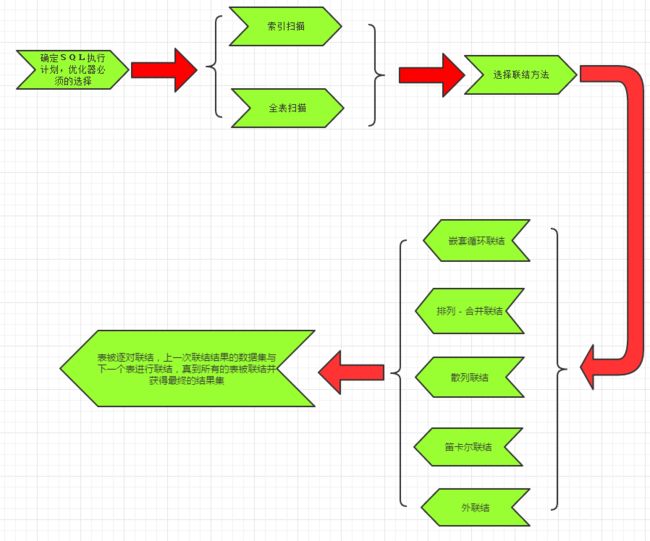
联结方法
如果查询中有多张表,在优化器确定了每个表最恰当的访问方法之后,下一步就是确定将这些表联结起来的最佳方法以及最恰当的顺序。任何时候当from中有多个表时,都需要时行联结。表之间的关系通过where子句中的一个条件定义。如果没有指定条件,联结就会隐含地定义为一个表中的每一行与另一个表中的所有行匹配。这称为笛卡儿联结。
联结的方法有: 嵌套循环联结,散列联结,排序-合并联结以及笛卡儿联结。
每种联结方法都有一定的最适合使用的条件。对于每对需要联结的表,优化器还必须确定表联结的顺序。
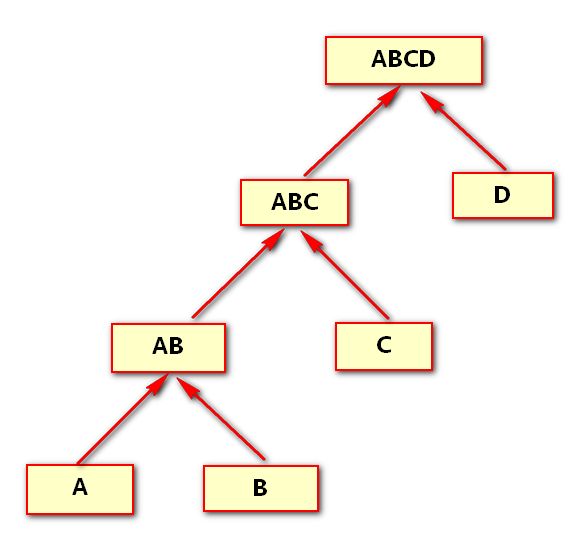
在第一对表联结后,下一张表是与第一个联结得到的结果行进行联结。在这次联结进行完了之后,下一个联结还是与其结果联结。这个过程会不断进行直到所有的表被联结为止。
每个联结都有两个分支,所访问的第一个表为驱动表,第二个表为内层表或被驱表。优化器使用统计信息和where子句中的筛选条件计算每个表分别返回多少行数据,从而确定哪张表是驱动表。预估大小最小的表通常被作为驱动表。尤其是当优化器确定其中的一张表基于unique或primary key约束将最多返回一行时,这样的表在联结过程中将放在前面。使用外联结运算符的表必须放在所联结表的后面。除这两中特殊情况,其它表的联结顺序都是由优化器使用所能得到的表,表及索引统计信息计算得到的选择比来进行评估的。
嵌套循环联结
嵌套循环联结使用一次访问运算所得税到的结果集中的每一行与另一个表进行对碰。如果结果集是有限的而且在用来联结的列上建有索引,那么这种联结的效率通常是最高的。
嵌套循环联结就是一个循环嵌在另一个循环当中。外层循环基本来说就是只查询where子句中的与驱动表有关的条件。当数据行经过了外层条件筛选并被确认匹配条件后,这些行就会逐个进入到内层循环中。然于基于联结列进行逐行检查看是否与被联结的表中的某一行相匹配。如果这一行与第二次的检查相匹配,就会被传递到查询计划的下一步,或者如果没有更多步骤则会直接包含在最终的结果集中。
嵌套回路
drop table emp;
create table emp(
empno number primary key not null ,
ename varchar2(30) not null,
deptno number not null,
job varchar2(20) not null,
mgr number(4) not null,
hiredate date default sysdate ,
sal number,
comm number
);
drop table dept;
create table dept(
deptno number primary key not null,
dname varchar2(30) unique not null ,
loc varchar2(30) not null
);
delete from dept;
insert into dept values(1,'sales','shenzhen');
insert into dept values(2,'develop','shanghai');
insert into dept values(3,'finance','beijing');
insert into dept values(4,'hr','tokyo');
delete from emp;
insert into emp values(1,'litao',1,'saler',2,default,9000,0);
insert into emp values(2,'liqian',1,'saler',2,default,9000,0);
insert into emp values(3,'polly',2,'it manager',2,default,9000,0);
insert into emp values(4,'hameimei',2,'engineer',2,default,9000,0);
insert into emp values(5,'uncle wang',2,'it director',2,default,9000,0);
insert into emp values(6,'lilei',2,'maintainer',2,default,9000,0);
insert into emp values(7,'jack',3,'cashier',2,default,9000,0);
insert into emp values(8,'tom',3,'cashier',2,default,9000,0);
insert into emp values(9,'andre',4,'hr supervisor',2,default,9000,0);
select * from emp;
select * from dept;
commit;
select /*+ leading (emp,dept) use_nl (emp) */
empno, ename, dname, loc
from emp, dept
where emp.deptno = dept.deptno;
SQL> select /*+ leading (emp,dept) use_nl (emp) */
2 empno, ename, dname, loc
3 from emp, dept
4 where emp.deptno = dept.deptno;
未选定行
执行计划
----------------------------------------------------------
Plan hash value: 1770543576
---------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 90 | 4 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 1 | 90 | 4 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL | EMP | 1 | 43 | 3 (0)| 00:00:01 |
|* 4 | INDEX UNIQUE SCAN | SYS_C0010235 | 1 | | 0 (0)| 00:00:01 |
| 5 | TABLE ACCESS BY INDEX ROWID| DEPT | 1 | 47 | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------
执行计划展示了将emp表作为驱动表,dept表作为内层表的嵌套循环联结方法。
嵌套循环联结顺序比较
select /*+ leading (dept,emp) use_nl (dept) */
empno, ename, dname, loc
from emp, dept
where emp.deptno = dept.deptno;
SQL> set autotrace traceonly
SQL> select /*+ leading (dept,emp) use_nl (dept) */
2 empno, ename, dname, loc
3 from emp, dept
4 where emp.deptno = dept.deptno;
未选定行
执行计划
----------------------------------------------------------
Plan hash value: 615168685
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 90 | 7 (15)| 00:00:01 |
|* 1 | HASH JOIN | | 1 | 90 | 7 (15)| 00:00:01 |
| 2 | TABLE ACCESS FULL| DEPT | 1 | 47 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| EMP | 1 | 43 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("EMP"."DEPTNO"="DEPT"."DEPTNO")
Note
-----
- dynamic sampling used for this statement
排序-合并联结
排序-合并联结独立地读取需要联结的两张表,对每张表中的数据行(仅是那些满足where子句中条件的数据行)按照联结键排序,然后将排序后的数据行集合并。
set autotrace traceonly
select /*+ ordered */
empno, ename, dname, loc
from dept,emp
where emp.deptno = dept.deptno;
首先关注的是对dept表使用的索引扫描。因为索引将按排序后的顺序返回数据,优化器选择使用索引来读取表数据。这就意味着避免一次单独的排序运算。对于emp表则必须进行全表扫描,然后单独排序,因为在deptno这一列上没有索引可用。在两个数据行集都准备好并排序后,它们将会被合并到一起。
排序-合并联结一般最适合数据筛选条件有限并返回有限数据行的查询。如果没有可用的直接访问数据的索引,那么排序-合并联结通常是较好的选择。总的来说,条件为非等式时,如where table1.column1 between table2.column1 and table2.column2,排序-合并联结通常是最好的选择。
散列联结
散列联结,与排序-合并联结类似,首先应用where子句中的筛选标准单独读取要进行的联结的两个表。基于表和索引的统计信息,确定返回最少行数的表将完全散列化到内存中。这个散列表包含了原表的所有数据行并被基于将联结键转化为散列值的随机函数载入到散列桶中。只要有足够的内存空间,这个散列表将一直放在内存中。如果没有足够的内存,散列表将会被写入到临时磁盘空间。
下一步就是读取另一张较大的表并对联结键列应用散列函数,然后利用得到的散列值对较小的在内存中的散列表进行探测以寻找匹配的第一个表的行数据所在的散列桶。每个散列桶都有一个放在其中的数据行列表。这个列表用来与探测行进行匹配。如果匹配成功,则返回这一行数据,否则丢弃。较大的表只读取一次,并检查其中每一行来寻找匹配。这与嵌套循环联结的不同之处在于此处内层表被多次读取。
散列联结
SQL> set autotrace traceonly;
SQL> select /*+ use_hash(dept,emp) */ empno,ename,dname,loc from dept,emp where emp.deptno=dept.deptno;
未选定行
执行计划
----------------------------------------------------------
Plan hash value: 615168685
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 90 | 7 (15)| 00:00:01 |
|* 1 | HASH JOIN | | 1 | 90 | 7 (15)| 00:00:01 |
| 2 | TABLE ACCESS FULL| DEPT | 1 | 47 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| EMP | 1 | 43 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------
散列联结只有在相等联结的情况下才能进行。
散列值
SQL> select distinct deptno,ora_hash(deptno,1000) hv from emp order by deptno;
DEPTNO HV
---------- ----------
1 355
2 979
3 660
4 560
SQL> select deptno from ( select distinct deptno,ora_hash(deptno,1000) hv from emp order by deptno) where hv between 300 and 600;
DEPTNO
----------
1
4
SQL> select distinct deptno, ora_hash(deptno,1000,50) hv from emp order by deptno;
DEPTNO HV
---------- ----------
1 580
2 93
3 756
4 785
SQL> select deptno from (select distinct deptno, ora_hash(deptno,1000,50) hv from emp order by deptno) where hv between 300 and 600;
DEPTNO
----------
1
用ora_hash函数来说明值是如何生成的,有3个参数:一个任何基本类型的输入,最大散列桶值(最小值为0),以及一个种子值(默认值也是0)。因此ora_hash(10,1000)将会返回一个0~1000之间的整数值。这儿主要是为了说明它们为什么不适合用于非等式联结。
笛卡尔联结
笛卡儿联结发生在当一张表中的所有行与另一张表的所有行联结时,这种联结所得到的结果集的总行为等于一张表中的数据行乖以另一张表中的数据行数。A X B = 结果集的总行数。
笛卡尔联结
SQL> set autotrace traceonly;
SQL> select empno, ename,dname, loc from dept,emp;
已选择36行。
执行计划
----------------------------------------------------------
Plan hash value: 2034389985
-----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 36 | 2304 | 10 (0)| 00:00:01 |
| 1 | MERGE JOIN CARTESIAN| | 36 | 2304 | 10 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL | DEPT | 4 | 136 | 3 (0)| 00:00:01 |
| 3 | BUFFER SORT | | 9 | 270 | 7 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL | EMP | 9 | 270 | 2 (0)| 00:00:01 |
-----------------------------------------------------------------------------
外联结
外联结返回一张表的所有行以及另一张表中满足联结条件的行数据。oracle使用+字符来表明进行外联结。+号放在一对圆括号中,位于只有匹配才会返回数据行的表联结条件旁。
外联结
select * from orders;
select * from customers;
--增加一些没有定单的客户
insert into customers values(6,'M','Li','Lei',3);
insert into customers values(6,'M','Jiang','tao',3);
insert into customers values(6,'F','Lili','cao',3);
commit;
--对下单数5000到10000的顾客进行统计
select c.cust_last_name, nvl(sum(o.order_total), 0) tot_orders
from customers c, orders o
where c.customer_id = o.customer_id
group by c.cust_last_name
having nvl(sum(o.order_total), 0) between 5000 and 100000
order by c.cust_last_name;
--计算一个总数
select count(*)
from (select c.cust_last_name, nvl(sum(o.order_total), 0) tot_orders
from customers c, orders o
where c.customer_id = o.customer_id
group by c.cust_last_name
having nvl(sum(o.order_total), 0) between 0 and 100000
order by c.cust_last_name);
--改变成外联结,包括没有定单的客户
select count(*)
from (select c.cust_last_name, nvl(sum(o.order_total), 0) tot_orders
from customers c, orders o
where c.customer_id = o.customer_id(+)
group by c.cust_last_name
having nvl(sum(o.order_total), 0) between 0 and 100000
order by c.cust_last_name);
SQL> set autotrace traceonly;
SQL> select count(*)
2 from (select c.cust_last_name, nvl(sum(o.order_total), 0) tot_orders
3 from customers c, orders o
4 where c.customer_id = o.customer_id(+)
5 group by c.cust_last_name
6 having nvl(sum(o.order_total), 0) between 0 and 100000
7 order by c.cust_last_name);
执行计划
----------------------------------------------------------
Plan hash value: 2112959513
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 8 (25)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | | |
| 2 | VIEW | | 1 | | 8 (25)| 00:00:01 |
|* 3 | FILTER | | | | | |
| 4 | HASH GROUP BY | | 1 | 15 | 8 (25)| 00:00:01 |
|* 5 | HASH JOIN OUTER | | 24 | 360 | 7 (15)| 00:00:01 |
| 6 | TABLE ACCESS FULL| CUSTOMERS | 5 | 40 | 3 (0)| 00:00:01 |
| 7 | TABLE ACCESS FULL| ORDERS | 24 | 168 | 3 (0)| 00:00:01 |
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter(NVL(SUM("O"."ORDER_TOTAL"),0)>=0 AND
NVL(SUM("O"."ORDER_TOTAL"),0)<=100000)
5 - access("C"."CUSTOMER_ID"="O"."CUSTOMER_ID"(+))
**使用ANSI联结语法的外联结 **
--使用ANSI联结语法的外联结
select count(*)
from (select c.cust_last_name, nvl(sum(o.order_total), 0) tot_orders
from customers c
left outer join orders o
on (c.customer_id = o.customer_id)
group by c.cust_last_name
having nvl(sum(o.order_total), 0) between 0 and 100000
order by c.cust_last_name);
在ANSI语法中,只需要使用关键字left outer join即可,这表明左侧的表是你需要的,即使没有满足联结条件的数据行也要将所有行包含在结果集中的表。如果你想即使在customers表中没有对应的匹配,也要返回orders表中的所有数据行,可以用right outer join。
Oracle外联结语法的另一个局限性在于它不支持全外联结。全外联结从左到右以及从右到左对两个表进行联结。两个联结方向所得到的结果只输出一次以避免重复。
使用ANSI联结语法的全外联结
select * from emp;
create table e1 as select * from emp where empno in (1,4);
create table e2 as select * from emp where empno in (2,6);
select * from e1;
select * from e2;
select e1.ename,e1.deptno,e1.job,
e2.ename,e2.deptno,e2.job
from e1 full outer join
e2 on (e1.empno=e2.empno);
两张表中的数据行即使在相对的表中没有匹配项也都出现在输出结果中。这就是全外联结所能做的事情,在部分数据集需要进行联结的时候是很有用的。
全外联结功能的oracle等价语法
select e1.ename, e1.deptno, e1.job, e2.ename, e2.deptno, e2.job
from e1, e2
where e1.empno(+) = e2.empno
union all
select e1.ename, e1.deptno, e1.job, e2.ename, e2.deptno, e2.job
from e1, e2
where e1.empno = e2.empno(+)
and e2.rowid is null;