Multi-modal Deep Learning
转自:http://blog.csdn.net/s2010241013/article/details/51731657
摘要:
本文提出一种在深度网络上的新应用,用深度网络学习多模态。特别的是,我们证明了跨模态特征学习——如果在特征学习过程中多模态出现了,对于一个模态而言,更好的特征可以被学习(多模态上学习,单模态上测试)。此外,我们展示了如何在多模态间学习一个共享的特征,并在一个特别的任务上评估它——分类器用只有音频的数据训练但是在只有视频的数据上测试(反之亦然)。我们的模型在CUAVE和AVLetters数据集上进行视-听语音分类,证明了它在视觉语音分类(在AVLetters数据集上)和有效的共享特征学习上是已发表中论文中最佳的。
1.介绍
在语音识别中,人类通过合并语音-视觉信息来理解语音。视觉模态提供了发音地方和肌肉运动的信息,这些可以帮助消除相似语音(如不发音的辅音)的歧义。
多模态学习包括来自多源的相关信息。语音和视觉数据在语音识别时在某个“中间层”是相关的,例如音位和视位;未加工的像素是很难与语音波形或声谱图产生相关性的。
在本文中,我们对“中间层”的关系感兴趣,因此我们选择使用语音-视觉分类来验证我们的模型。特别的是,我们关注用于语音识别的学习特征,这个学习特征是和视觉中的唇形联系在一起的。
全部任务可分为三部分-特征学习、有监督训练和测试。用一个简单的线性分类器进行有监督训练和测试,以检查使用多模态数据的不同的特征学习模型(eg:多模态融合、跨模态学习和共享特征学习...)的有效性。我们考虑三个学习布置——多模态融合、跨模态学习和共享特征学习。
(如图1所示)多模态融合:数据来自所有模态,用于所有模态。跨模态学习:数据来自所有模态,但只在某模态可用。共享特征学习:训练和测试用的不同模态的数据。如果特征可以在跨不同模态下捕获相关性,这会允许我们进行评价。特别的是,学习这些布置可以使我们评估学到的特征是否具有模态不变性。
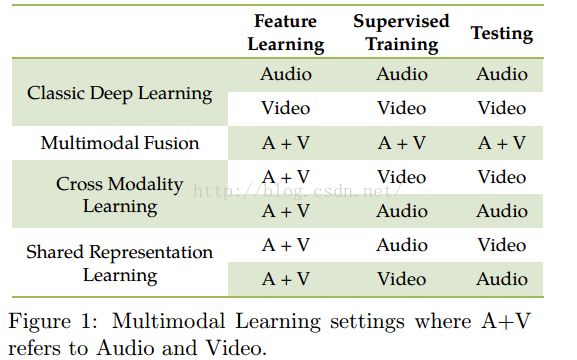
接下来,我们描述模型的构造块。然后,我们实现了不同的使用深度学习的多模态学习模型,这些模型可以实现不同的多模态任务。最后,我们展示实验结果和总结。
2.背景
深度学习的当前工作已经测试了deep sigmoidal networks是如何被训练的,以产生有用的用于手写数字识别和文本的特征。当前工作的关键在于使用RBMs(Restricted Boltzmann Machines)微调的进行贪心的逐层训练。我们使用一个扩展的稀疏RBMs,它学习到的特征对于数字和自然的图像来说是有意义的特征。
2.1稀疏RBMs
为了正则化模型使其稀疏,我们让每个隐藏层单元有一个使用了正则化惩罚的预先期望的激活函数,这个正则化惩罚的形式是![]() ,其中
,其中![]() 是训练集,
是训练集,![]() 决定了隐藏层单元激活函数的稀疏性(就是隐藏层单元激活函数是否被激活)。
决定了隐藏层单元激活函数的稀疏性(就是隐藏层单元激活函数是否被激活)。
3.学习结构
这部分描述我们的模型,用它来完成语音-视频二模态的特征学习任务。输入到模型里的语音和视频是连续的音频和视频图像。为了推出我们的深度自编码模型,我们先描述一些简单的模型以及他们的缺点。(下面的都是预训练模型)
I.RBM模型。用其分别训练语音和视频,学习RBM之后,在v固定时得到的隐藏层值可以作为数据的一个新特征。我们将这个模型作为基准来比较我们的多模态模型的结果,也可以将其用来预训练我们的深度网络。

II.为了训练多模态模型,一个直接的方法是训练一个把语音和视频数据连接在一起的RBM。虽然这个模型联合了语音和视频数据的分布,但它仍是一个浅层模型。语音和视频数据之间的关联是高度非线性的,RBM很难学习这些相关性形成多模态特征。事实上,我们发现在隐藏层单元学习到的浅层的二模态RBM结果与单模态下的值有很强的关联,但与跨模态下的值就没有。
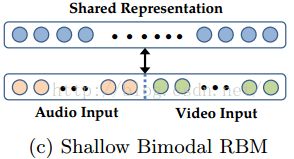
III.因此,我们考虑在每个模态的预训练层贪婪的训练一个RBM,前面(![]() )的第一层的隐藏值作为新层的训练数据。通过学习到的第一层特征来表示数据可以更容易的让模型来学习跨模态的高阶相关性。通俗的来说,第一层特征相当于音位和视位,第二层模型化了他们之间的关系。
)的第一层的隐藏值作为新层的训练数据。通过学习到的第一层特征来表示数据可以更容易的让模型来学习跨模态的高阶相关性。通俗的来说,第一层特征相当于音位和视位,第二层模型化了他们之间的关系。
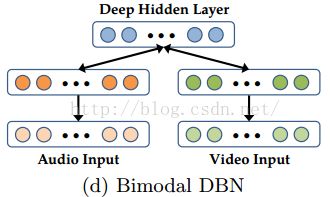
然而,上述的多模态模型还有两个问题。第一,没有明确的目标提供给模型去发现跨模态间的相关性;一些隐藏层单元只针对语音调整参数,另一些只针对视频调整参数,这样模型才有可能找到想要的特征。第二,在跨模态学习布置中只有一个模态用于监督训练和测试,这样的模型显得很笨拙。只有一个模态呈现,就要整合没有观察到的可见变量来推理。
因此,我们提出解决以上问题的深度自编码模型。我们首先考虑跨模态学习布置:特征学习过程中两个模态都呈现了,但只有一个模态用于有监督训练和测试。当只给视频数据时,深度自编码模型用于训练重建语音和视频模态(图3a)。我们用二模态的DBN(Deep belief network)权重(图2d)去初始化深度自编码模型。中间层可以作为新特征表示来用。这个模型可以看做多任务学习的一个实例。
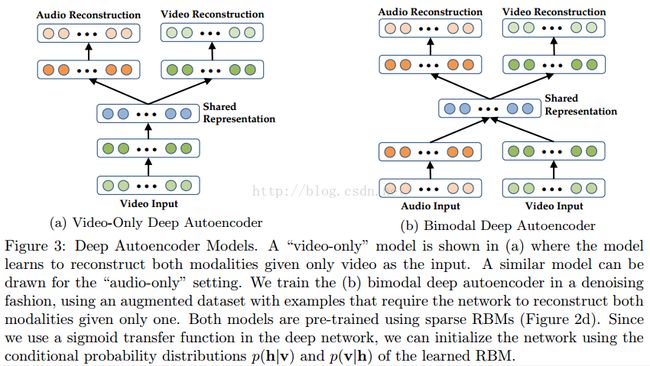
我们在布置中使用图3a模型。另一方面,当多模态适合任务时,并不清楚如何使用模型针对每个模态进行深度自编码训练。一个直接的方法是训练解码权重tied(这个我也不知道怎么理解)的网络。但是,这样的方法扩展性不是很好——如果在测试时我们允许任意模态相结合形成特征,我们将需要训练指数级数量的模型。
受到降噪自编码模型的启发,我们提出训练二模态深度自编码模型(3b),它使用了一个扩充(对单模态输入的扩充)但是有噪声的数据集。实际上,我们扩充时一个模态用全零作为输入,另一个模态用原始值作为输入,但是依旧要求模型重建这两个模态。因此,三分之一的训练数据只有视频作为输入,三分之一的训练数据只有语音作为输入,最后三分之一既有视频又有语音。
由于使用了稀疏RBMs进行的初始化,我们发现就算深度自编码训练之后,隐藏层单元还是有低期望激活函数。因此,当一个输入模态全设为零,第一层特征也接近于零。所以,我们本质上训练了一个模态特别的深度自编码网络(3a)。当某个模态输入缺失时,这个模型仍是鲁棒的。
4.实验和结果
我们用分离字母和数字的语音-视频分类来评估我们的模型。稀疏参数![]() 采用交叉核实来选择,即其它所有参数都保持固定(包括隐藏层大小和权重调整)。
采用交叉核实来选择,即其它所有参数都保持固定(包括隐藏层大小和权重调整)。
4.1数据预处理
我们用时间导数的谱来表现语音信号,采用PCA白化(就是归一化)将483维减少到100维。
对于视频,我们预处理它以便于只提取嘴部的ROI(感兴趣区域)。每个嘴部ROI都缩放到60*80,进一步使用PCA白化减少到32维。我们用4帧连续视频作为输入,这近似于10帧连续的语音。对每个模态,我们都在时间上进行特征均值归一化,类似于去除直流分量。我们也注意到在特征里增加时间导数,这种用法在文献里有很多,它有助于模拟不断变化的语音信息。时间导数用归一化线性斜率计算,所以导数特征的动态范围可以和原始信号媲美。
4.2数据集和任务
我们保证没有测试集数据用于无监督特征学习。所有的深度自编码模型都用全部无标签的语音和视频数据来训练。
我们注意到在所有的数据集中,就唇的外表、定位和大小是多样性的。对每个语音-视频剪切块,我们从其帧的重叠序列中提取出特征。由于每个样本都有不同的持续时间,我们将每个样本分割成S个相等的块,用平均值表示每块。来自所有块的特征随后连接在一起。特别的是,我们使用S=1和S=3时的特征结合形成我们最终的特征,用SVM来进行分类。
4.3跨模态学习
我们评估如果在特征学习过程中给的是多模态数据,我们是否可以在一个模态上学习到很好的特征。