RR级别下的GAP锁范围
故不尽知用兵之害者,则不能尽知用兵之利也。
对于索引,给人的第一印象可能是查询性能的提高,再者是更新或插入之后的sort/merge开销以及页分裂问题(聚簇索引也是索引)。
还有一些同学说索引对于写数据也有颇多好处,好处来自于记录锁定的减少,那么,究竟锁住了多少条记录呢?(知道的就不用往下翻了,不如看看女主播爽歪歪)
今天聊的是MySQL数据库InnoDB引擎下RR级别SQL执行的加锁范围,版本号是8.0.18。
先贴一波表结构:
create table stusys.a
(
id bigint auto_increment
primary key,
num int not null,
note int null
);
create index a_num_index
on stusys.a (num);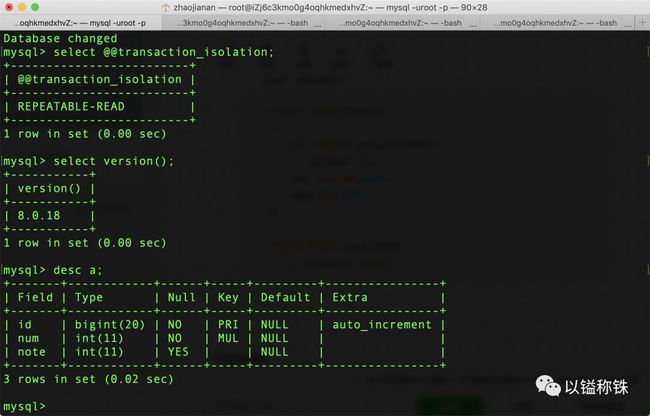
准备一下做实验的数据:
insert into a(num) values(5);
insert into a(num) values(10);
insert into a(num) values(20);
众所周知,四种隔离级别解决的是读数据的问题,RC和RR是通过MVCC实现了一致性非锁定读,就是常说的快照读,读不加锁;与之相对的一致性锁定读就是所谓的当前读了,顾名思义,读加锁。
锁定读在RR级别下是为了解决幻读的问题,幻读是发生在两次update/delete下数据不一致的情况,究其原因是在两次写过程中有新的数据插入,所以要做的自然就是如何在两次写过程中禁止新的数据插入,InnoDB通过RecordLock+GapLock+NextKeyLock解决了这个问题。
---------------切入正题---------------
首先我们开启事务1,做一个update:
update a set note = '1' where num = 10;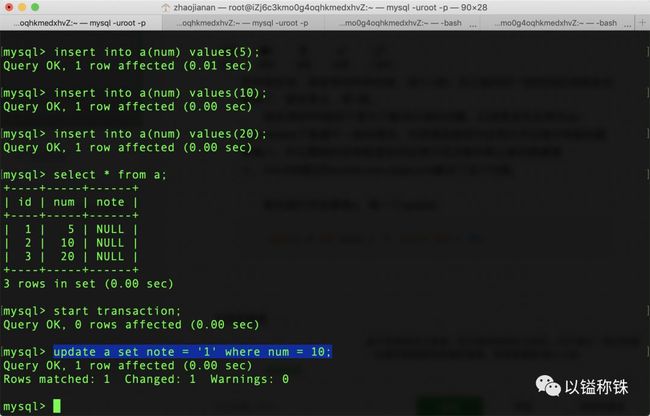
现在请大家想一想,如何禁止num = 10的数据插入呢?很简单,索引已经把数据列成一排了,我们在index_num = 10上面把它给框住,不让其他的num = 10的数据插入就可以了,所以现在的思路是这样的:

现在开启事务2,插入一条数据10:(之后我尽量不贴SQL代码了,节省篇幅)
insert into a(num) values(10);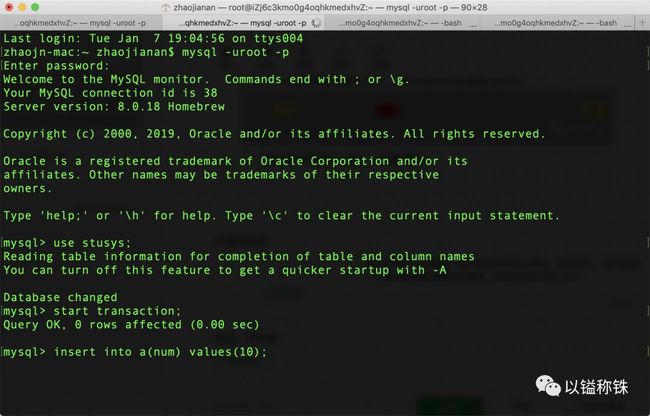
发现插入数据被阻塞了,嗯,没有问题,可以得知10上面被加了行锁,同时为了禁止数据插入又加了间隙锁,那么此时哪些数据可以被插入呢?
(下面如果没有特殊说明,我所说的加锁都是间隙锁)
接着在事务2里插入数据9,发现被阻塞了:
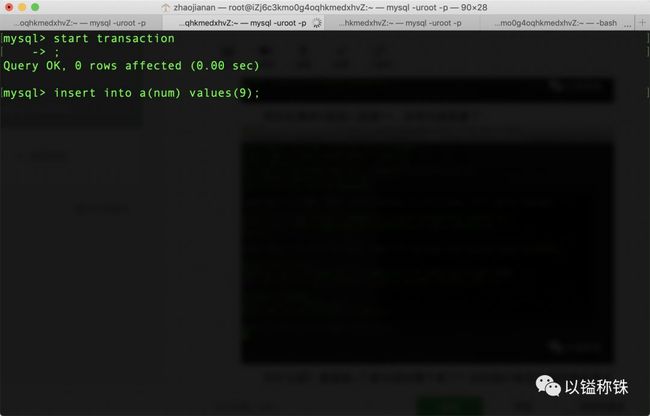
然后在事务3里插入数据11,发现也被阻塞了:
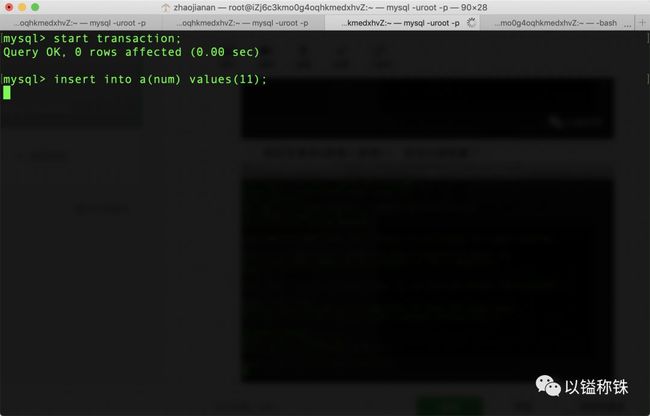
为什么呢?难道我加了索引还被锁住了整张表?这时我们肯定会第一时间想到临界点。(想不到的劝退)
事务2插入数据5,事务3插入数据20:
事务1:
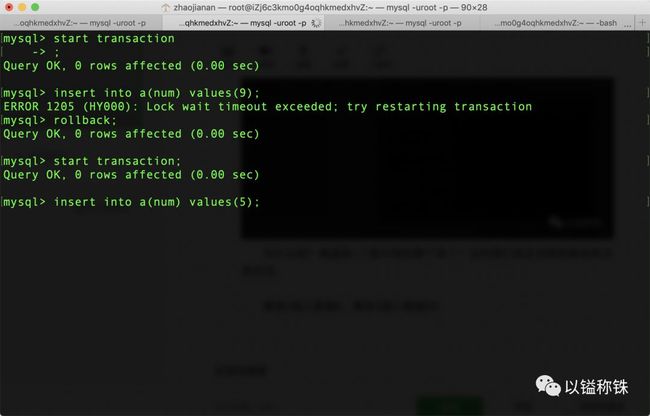
事务2:
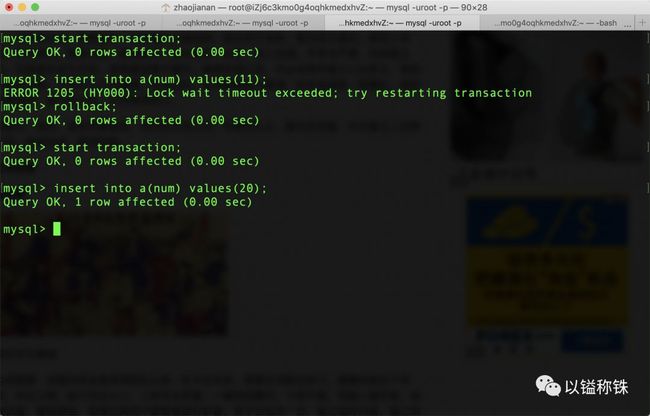
我靠,数据5被禁止插入,但是数据20是可以的!莫非只有前者被锁住?事情开始变得有意思了。
现在我们回过头来想想之前所框住的数据,假设我们编了一个篱笆墙,这个篱笆墙的长度必然是有限的,而长度则是两边木桩之间的距离(别跟我说篱笆是弯的),那么问题就来了,如果之前的数据10被这段篱笆框住了,而篱笆是不会自动延伸的,那么这样能够阻止其他事务插入数据10吗?
答案是不可以,所以为了不让新来的数据10插入,就必须延长篱笆,延长多少就够了呢?那就选取索引上与当前条件最近的两个点吧,所以实际上它是这样加锁的:

但是为什么数据5被锁住了,而数据20却没有呢?别忘了,InnoDB是很聪明的,只锁定必要的范围就可以了,这个必要的范围与索引就有关系了,且看建表语句中有这么一句,我给你们搬下来了:
create index a_num_index on stusys.a (num);InnoDB默认的索引排序规则是asc,也就是说,相同的索引数据是往后排的,是不是上面的两条插入语句如果成功后,就变成这样了呢:
我们改一下表结构,做个试验,下面是SQL语句和当前的数据:
alter table a add num2 int default 0 not null;
drop index a_num_index on a;
create index a_num_num2_index on a (num, num2);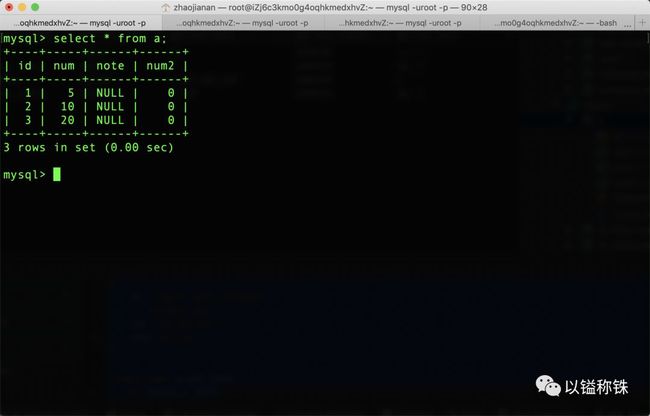
现在让事务1同样更新数据10,事务2这次插入数据(5,-1):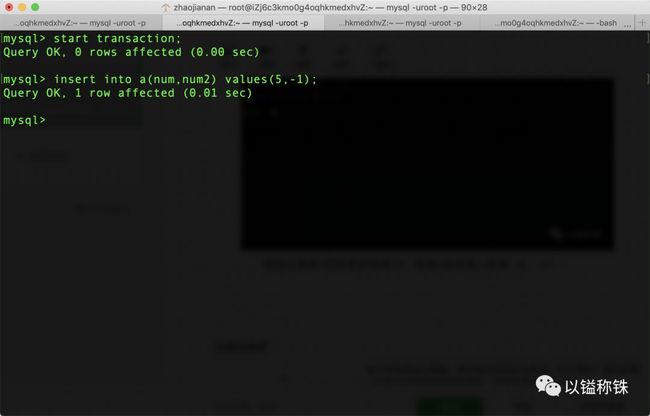
成功插入!与我们所料一致!
每当人们谈起幻读,总是离不开三个锁:RecordLock、GapLock、NextKeyLock,行锁是为了禁止数据修改造成两次写操作不一致,这个很容易理解;而GapLock/NextKeyLock则是实现了数据禁止插入,所以常常将这两个锁放在一起叙述,NextKeyLock较为官方一点的解释是:“索引记录上面的锁 + 索引记录前面间隙上的锁”,比较绕口,我认为大可不必死记硬背,我们只需要知道它究竟锁定了多少条记录即可。
我个人总结了一下,觉得这样比较容易理解,也比较容易分析,只有两步:
1.我所修改/删除的是哪些数据;
1.这些数据的左右两个端点是什么;(就是上面说的木桩)
当然你必须要考虑你是否在条件上有索引以及索引的排序方式,就这么简单。
至于两端点是否可以被修改、以及先insert之后锁范围的变化,有兴趣的同学可以自己做实验,我这里只提示一下insert如果成功则会将当前插入的记录上一个行锁,其他的按照上面两个步骤分析即可。
最后把我们的最终思维抽象图贴一下:
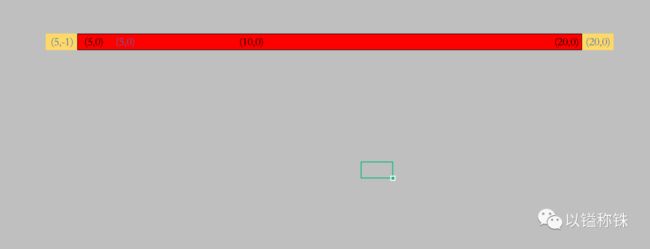
公众号搜索:以镒称铢