EarlyStopping()以及训练技巧
Early Stopping是什么
EarlyStopping是Callbacks的一种,callbacks用于指定在每个epoch开始和结束的时候进行哪种特定操作。Callbacks中有一些设置好的接口,可以直接使用,如’acc’, 'val_acc’, ’loss’ 和 ’val_loss’等等。
EarlyStopping则是用于提前停止训练
原理
- 将数据分为训练集和验证集
- 每个epoch结束后(或每N个epoch后): 在验证集上获取测试结果,随着epoch的增加,如果在验证集上发现测试误差上升,则停止训练;
- 将停止之后的权重作为网络的最终参数。
直观感受,因为精度都不再提高了,在继续训练也是无益的,只会提高训练的时间。并不是说验证集精度一降下来便认为不再提高了,因为可能经过这个Epoch后,精度降低了,但是随后的Epoch又让精度又上去了,所以不能根据一两次的连续降低就判断不再提高。一般的做法是,在训练的过程中,记录到目前为止最好的验证集精度,当连续10次Epoch(或者更多次)没达到最佳精度时,则可以认为精度不再提高了。
直观理解
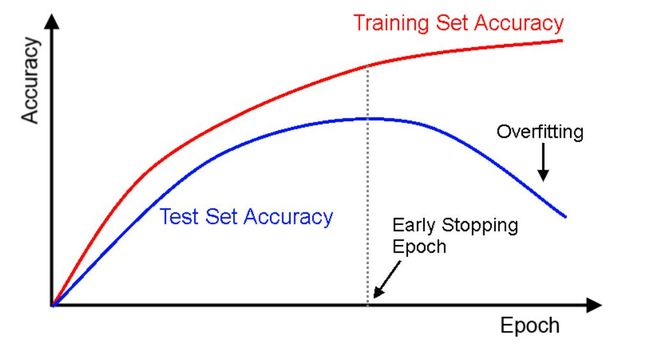
最优模型是在垂直虚线的时间点保存下来的模型,即处理测试集时准确率最高的模型。
Early Stopping的优缺点
- 优点:只运行一次梯度下降,我们就可以找出w的较小值,中间值和较大值。而无需尝试L2正则化超级参数lambda的很多值。
- 缺点:不能独立地处理以上两个问题,使得要考虑的东西变得复杂。举例如下:
EarlyStopping的使用与技巧
一般是在model.fit函数中调用callbacks,fit函数中有一个参数为callbacks。注意这里需要输入的是list类型的数据,所以通常情况只用EarlyStopping的话也要是[EarlyStopping()]
EarlyStopping的参数:
- monitor: 监控的数据接口,有’acc’,’val_acc’,’loss’,’val_loss’等等。正常情况下如果有验证集,就用’val_acc’或者’val_loss’。但是因为笔者用的是5折交叉验证,没有单设验证集,所以只能用’acc’了。
- min_delta:增大或减小的阈值,只有大于这个部分才算作improvement。这个值的大小取决于monitor,也反映了你的容忍程度。如monitor是’acc’,同时其变化范围在70%-90%之间,所以对于小于0.01%的变化不关心。加上观察到训练过程中存在抖动的情况(即先下降后上升),所以适当增大容忍程度,最终设为0.003%。
- patience:能够容忍多少个epoch内都没有improvement。这个设置其实是在抖动和真正的准确率下降之间做tradeoff。如果patience设的大,那么最终得到的准确率要略低于模型可以达到的最高准确率。如果patience设的小,那么模型很可能在前期抖动,还在全图搜索的阶段就停止了,准确率一般很差。patience的大小和learning rate直接相关。在learning rate设定的情况下,前期先训练几次观察抖动的epoch number,比其稍大些设置patience。在learning rate变化的情况下,建议要略小于最大的抖动epoch number。笔者在引入EarlyStopping之前就已经得到可以接受的结果了,EarlyStopping算是锦上添花,所以patience设的比较高,设为抖动epoch number的最大值。
- mode: 就’auto’, ‘min’, ‘,max’三个可能。如果知道是要上升还是下降,建议设置一下。笔者的monitor是’acc’,所以mode=’max’。
min_delta和patience都和“避免模型停止在抖动过程中”有关系,所以调节的时候需要互相协调。通常情况下,min_delta降低,那么patience可以适当减少;min_delta增加,那么patience需要适当延长;反之亦然。
代码例子:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: Jia ShiLin
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.callbacks import EarlyStopping, ModelCheckpoint
from keras.optimizers import SGD, Adadelta, Adam, RMSprop, Adagrad, nadam, Adamax
data = pd.read_csv('winequality-red.csv', sep=';')
y = data['quality']
x = data.drop(['quality'], axis=1)
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=2019)
x_train, x_val, y_train, y_val = train_test_split(x_train, y_train, test_size=0.2, random_state=2019)
# model_function
def create_model(opt):
'''
creat a model
:param opt:
:return:model
'''
model = Sequential()
model.add(Dense(100, input_dim=x_train.shape[1], activation='relu'))
model.add(Dense(50, activation='relu'))
model.add(Dense(25, activation='relu'))
model.add(Dense(1, activation='linear'))
return model
# create_function,用来定义在训练期间将使用的回调函数
def create_callbacks(opt):
'''
回调函数
:return:callbacks,类型list
'''
# 一般是在model.fit函数中调用callbacks,fit函数中有一个参数为callbacks。
# 注意这里需要输入的是list类型的数据,所以通常情况只用EarlyStopping的话也要是[EarlyStopping()]
callbacks = [
EarlyStopping(monitor='val_acc', patience=200, verbose=2),
ModelCheckpoint('best_model_' + opt + '.h5', monitor='val_acc', save_best_only=True, verbose=0)
]
return callbacks
# 创建一个想要尝试的优化器字典
opts = dict({'sgd': SGD(),
'adam': Adam(),
})
# train_and_save
results = []
# 遍历优化器
for opt in opts: # 依次取到每个键
model = create_model(opt)
callbacks = create_callbacks(opt)
model.compile(loss='mse', optimizer=opts[opt], metrics=['accuracy'])
hist = model.fit(x_train, y_train, batch_size=128, epochs=5000,
validation_data=(x_train.values,y_train),
batch_size=128,
callbacks=callbacks,
verbose=0
)
best_epoch = np.argmax(hist.history['val_acc'])#返回最大下标
best_acc = hist.history['val_acc']['best_epoch']
#加载具有最高验证精度的模型
best_model = create_model(opt)
best_model.load_weights('best_model_'+opt+'.h5')
best_model.compile(loss='mse',optimizer=opts[opt],metrics='accuracy')
score = best_model.evaluate(x_train.values,y_test,verbose=0)
test_accuracy = score[1]
results.append([opt,best_epoch,best_acc,test_accuracy])
#比较结果
res = pd.DataFrame(results)
res.columns =['optimizer','epoch','val_accuracy','test_accuracy']
print(res)#或者控制台输入:res
扩充
如果不用early stopping降低过拟合,另一种方法就是L2正则化,但需尝试L2正则化超级参数λ的很多值,个人更倾向于使用L2正则化,尝试许多不同的λ值。