采用FPGA实现实时边缘检测VGA显示
采用FPGA实现图像算法,本质上是为了追求更高的处理速度,通过HDL设计专用电路并在FPGA上运行,可实现CPU或者DSP架构达不到的数据吞吐量。
图像采集。涉及到大量的数据存储、前处理、传输,对带宽要求很高。如果未处理好,一定程度上会限制图像处理功能。除去一些简单算法可以实现实时处理图像数据流外,大部分图像处理算法需要大量的存储带宽作保障。广义的图像采集可能涉及到将捕捉的图像高速编码并发送出去。FPGA主要用于接口的适配,包括两个方面,一是将输出的数据接口转换成标准的或者后端芯片可以接受的格式,二是如果速度太快后端无法接收的还需要FPGA做缓存然后传给后端的芯片或设备。
使用算法对图像进行分析、计算则是FPGA的强项。但用HDL语言实现复杂算法较CPU或DSP平台常用的C语言代价较高。要改变FPGA上的电路结构,需要写新的HDL并对其重新编程。一般用于对实时性要求较高的领域,主要是ASIC不提供但是实际中需要用的的功能。
通过对基本图像算法在FPGA上实现,加深对HDL语言的认识,为设计超大规模集成电路实现图像处理加速打下基础。
制作要求:
(1)图像处理前夕
①通过SCCB通信总线协议对OV7725摄像头进行初始化。
②将RGB888格式的视屏流转换为YUV格式的视屏。
③提取Y分量信号,作为灰度信号源。
(2)图像处理
①用移位寄存器IP核获得3*3像素阵列,通过修改宏定义使每个像素为8bit深
度。
②对三行像素阵列同时处理实现均值滤波,即提取三个最大值中的最小值,三个
最小值中的最大值,以及三个中间值的中间值。
③对上述三个值再取均值获得九个像素点的均值。
④行、场像素时钟相应移动相应时钟保持同步。
⑤利用离散差分算子——Sobel算子来运算图像亮度函数的灰度近似值,产生对
应的灰度矢量。
(3)处理结果
最终得到实时处理显示的黑白边缘图像。
视频图像处理大致分采集、存储、运算、再现四个部分,如图3-1。以下分别从这四个部分简介基本原理。

选用 OmniVision 的 OV7725 Sensor 作为视频图像源。
图3-2为其内部功能模块框架:

OV7725 上电会默认输出 YUV422 格式的视频流,但为使传感器能够按照预期的模式工作,需要对分辨率,内部时钟,亮度、 色差、 3A 等参数进行配置。因此我们需要一个接口,来完成 OV7725 寄存器的配置——这就是 SCCB 接口,即 Serial Camera Control Bus,串行相机控制总线。
OV7725的 SCCB 接口有两个信号,即时钟信号 SCL、数据信号 SDA。OV7725通过这两个信号,完成寄存器的配置,实现预期配置的视频流输出。
SCCB 总线通过串行方式发送 8Bit 数据,先发送 MSB,再发送 LSB,与 SPI总线协议的数据发送很类似(除了不需要 SPI_CS)。 在发送完 8Bit 数据后,通过器件的响应信号,完成一次数据的传输。如图3-3所示。
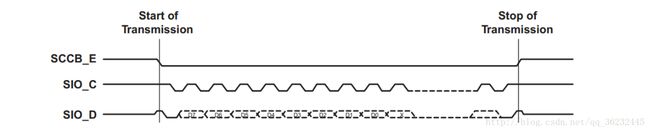
OV7725 总共有 172 个寄存器,作为 CMOS Sensor 的工作模式的配置。而这 172 个寄存器,有些只读,有些则同时支持读写功能。在传感器正常工作工作前,必须进行寄存器的初始化,不然无法得到预期,更得不到较好画质的图像。而这 172 个寄存器,就是我们需要通过 SCCB 总线接口进行配置的目标。在实现 SCCB 总线协议的基础上,实现寄存器的配置,以保证预期模式图像的输出。当然这 172 个寄存器也并非都需要配置,很多寄存器都可以采用默认的值。
SCCB 总线在写寄存器时,先写设备地址,再写寄存器地址,最后写入寄存器的值,完成一个寄存器的配置, 即 ID-Address + SUB-Address + W-Data 的流
程,如图3-4所示:

相对于 SCCB 总线的写入时序而言, SCCB 总线的读取流程稍微复杂一点,步骤上需要写入两次设备 ID,如图3-5所示:

采用SDRAM对采集得到的视频流进行存储。
SDRAM 即 Synchronous Dynamic Random Access Memory,同步动态随机存储器。同步是指其时钟频率与 CPU 前端总线的系统时钟频率相同,并且内部命令的发送与数据的传输都是以它为基准的;动态是由于 SDRAM 为电容阵列,需要不断地充放电, 或者说不断的刷新来保证数据不丢失;随机则是说不是线性一次存储,而是自由指定地址进行数据的读写。 SDRAM 的内部结构如图3-6所示:

SDRAM 的内部是一个存储阵列,可以把它想象成一张表格, 将数据“填”进去
如图3-6所示。和表格的检索原理一样,先指定一个行(Row),再指定一个列 (Column),
比如地址为 2, 列地址为 A 对应的就是黑色的单元格。对于内存,这个单元格可称为
存储单元,每一个单元能存放宽为 8/16/32 的数据。 而对于整个行列组成的块而言,
这个表格(存储阵列)在 SDRAM 中成为逻辑 Bank。
大部分 SDRAM 内部都是以 4 个 L-Bank 设计的,也就是说一共有 4 个这样的“表格”。寻址的流程也就是——先指定 L-Bank 地址,再指定行地址,然后指定列地址确定寻址单元。
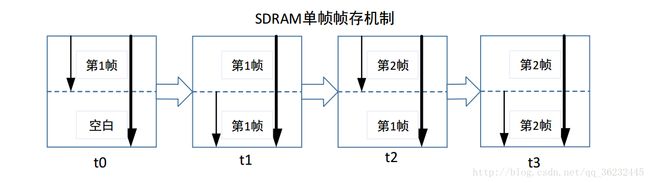
为解决当前读取的图像与上一次存入的图像存在交错如图3-7所示。我们需要实现片内乒乓,来实现一定时间内,SDRAM 存储块读写的乒乓操作,我们将这种方式叫做“不完全 BANK 乒乓读写操作”,简单的给出框图,如图3-8所示:
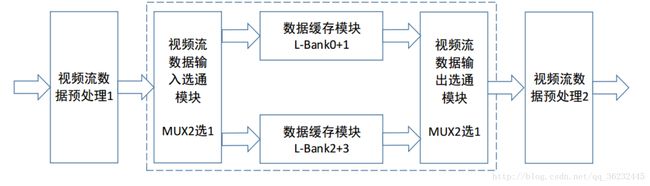
对于用户的操作而言,只需要关心 WRFIFO 写入端口, 与 RDFIFO 读取端口。每个端口的时序均一样, 主要分为连续写入/读取,时序图如图3-9所示。与使能写入/读取,时序图如图3-10所示:


(1)RGB转YUV
RGB 转 YUV,实际上只是色度空间的转换,前者为三原色色度空间,后者为亮度与色差,其中 RGB 转 YUV 的公式如下所示:
由于 Verilog HDL 无法进行浮点运算,因此使用扩大 256 倍,再向右移 8Bit的方式,来转换公式,如下所示:
计算步骤为:
① 分别计算出Y、Cb、Cr中每一个乘法的乘积。
② 计算出Y、Cb、Cr括号内的值。
③ 右移8Bit,这里由于Step2计算结果为16Bit,因此提取高8Bit即可。
实际上从①~③的运算,均直接通过寄存器描述,没有顾虑行场有效时序等。但实际上的操作会有一个数据流上的先后顺序,同时①~③同时对连续数据进行处理,采用这种方式实现的硬件加速,我们称之为流水线设计技巧。在 HDL-VIP(硬件描述语言实现视频图像处理)中是一种非常重要而且常用的算法实现思维,是 FPGA 硬件加速的精髓之一。
(2)获取3*3像素阵列
调用Shift_RAM IP核,在 Shift_RAM 中存 2 行数据,同时与当前输入行的数据,组成3 行的阵列。新建 VIP_Matrix_Generate_3X3_8Bit 文件,在此实现 8Bit 宽度的 3*3 像素阵列功能。具体的实现步骤如下:
① 寄存示意图如图3-11所示

② 输入的信号用像素使能时钟同步一拍,以保证数据与Shift_RAM 输出的数据
保持同步。
③ 例化并输入三行像素数据,此时可从 Modelsim 中观察到 3 行数据同时存在了。
(3)均值滤波
均值滤波是典型的线性滤波算法,它是指在图像上对目标像素给一个模板,该模板
包括了其周围的临近像素(以目标象素为中心的周围 8 个像素,构成一个滤波模板,
即去掉目标像素本身),再用模板中的全体像素的平均值来代替原来像素值。如图3-12所示:
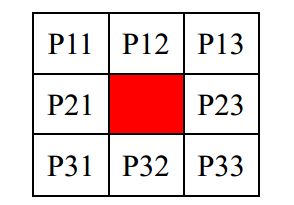
分析上面这个表格。 其实 HDL 完全有这个能力直接计算 8 个值相加的均值,不过为了提升电路的速度,我们需要通过以面积换速度的方式来实现。所以这里需要 3 个步骤:
① 分别计算 3 行中相关像素的和。
② 计算②中三个结果的和。
③ 用右移动 3Bit 来实现除以8的目的。
(4)中值滤波
中值滤波算法与均值滤波非常的相似, 但滤波的效果却有很大的差别, 区别如下:
① 均值滤波相当于低通滤波, 有将图像模糊化的趋势,对椒盐噪声基本无能力。
② 中值滤波的有点事可以很好的过滤椒盐噪声,缺点是容易造成图像的不连续。
中值滤波的算法非常简单,只要求得 3*3 像素阵列的中间值即可,这样就有效的移植了最大值与最小值,图像会变得均匀,对椒盐噪声有很好的滤除效果。中值滤波示意图如图3-13所示:

由上图可得中值滤波计算步骤为
① 分别对每行 3 个像素进行排序, Verilog HDL 的实现,由于并行特性,我们只需要一个时钟
② 对三行像素取得的排序进行处理,即提取三个最大值中的最小值,三个最小值中的最大值,以及三个中间值的中间值。 这里直接例化 Sort3 模块即可
④ 将中得到的三个值,再次取中值,求得最终 9 个像素的中值
(5)边缘检测
所谓边缘是指其周围像素灰度急剧变化的那些像素的集合,它是图像最基本的特征。边缘存在于目标、背景和区域之间,所以,它是图像分割所依赖的最重要的依据。由于边缘是位置的标志,对灰度的变化不敏感,因此,边缘也是图像匹配的重要的特征。
边缘检测和区域划分是图像分割的两种不同的方法,二者具有相互补充的特点。在边缘检测中,是提取图像中不连续部分的特征,根据闭合的边缘确定区域。而在区域划分中,是把图像分割成特征相同的区域,区域之间的边界就是边缘。由于边缘检测方法不需要将图像逐个像素地分割,因此更适合大图像的分割。
边缘大致可以分为两种,一种是阶跃状边缘,边缘两边像素的灰度值明显不同;另一种为屋顶状边缘,边缘处于灰度值由小到大再到小的变化转折点处。边缘检测的主要工具是边缘检测模板。边缘检测的有很多,典型的有索贝尔算子,普里维特算子,罗伯茨交叉边缘检测等边缘检测技术,在 Matlab 中有现成的 IPT 函数,提供边缘检测,
Sobel 卷积示意图如图3-14所示:
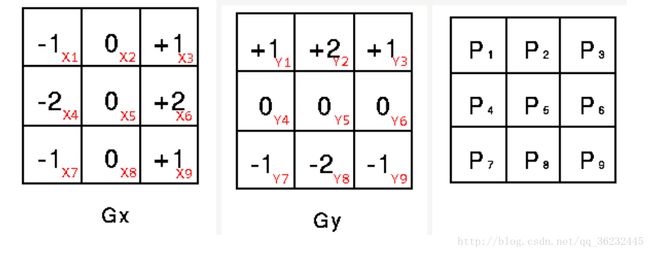
该算子包含两组3x3的矩阵,分别为横向及纵向,将之与图像作平面卷积,即可分别得出横向及纵向的亮度差分近似值。如果以 A 代表原始图像, Gx 及 Gy 分别代表经横向及纵向边缘检测的图像灰度值,其公式如下:
图像的每一个像素的横向及纵向灰度值通过以下公式结合,来计算该点灰度的大小:
通常,为了提高效率 使用不开平方的近似值,但这样做会损失精度,迫不得已的时候可以如下这样子:
如果梯度 G 大于某一阀值 则认为该点(x,y)为边缘点。然后可用以下公式计算梯度方向:
3.3 调试
(1)利用 PLL IP核构造了全局系统时钟,使得即系统首先经过了一段时间的延时,来保证所有电路正常上电,外设工作正常;其次才开始打开 PLL, 准备锁相输出。 后续,将 PLL 输出的锁相信号与同步后的异步复位信号通过与门实现了全局复位时钟。本模块经测试使用,稳定可靠。
(2)优化官方SDRAM管理器,实现不完全 BANK 乒乓读写操作。
(3)将乘除法运算都进行了拆分,然后用移位实现,实现了面积换时间。
总结
至此, 我们完成了基本的 HDL-VIP 算法的范例, FPGA 作为视频图像处理的硬件平台, 以其并行高速的特性,以流水线的处理功能, 完败了处理器的性能, 这便是 HDL-VIP 的灵魂所在。
课程设计的内容到此告一段落,但其实 VIP 的旅程才真正开始。 YCbCr422转 RGB888、 Bayer 阵列的恢复, 均值滤波、 中值滤波、 Sobel 边缘检测这些只是图像处理中最基本的一些算法,只不过我们将算法移植到 FPGA 中后,实现了实时视频图像算法的硬件加速功能。
最初我们得到了 RAW Bayer 阵列,通过 VGA 发送给 PC, 显示了彩色图像,接着我们通过 RGB888 转 YUV 算法,得到了灰度的图像, 但若干 RGB 转 YUV 实现了, YUV转 RGB888 同样得实现,我们通过YCbCr422→YcbCr444→RGB888, 恢复了 OV7725 输出的 YUV 视频,得到了RGB888 的视频图像。再然后得到的均值滤波/中值滤波算法后的图像。
然后我们又进行了 Sobel 边缘检测。即先通过中值滤波,然后才进行 Sobel 边缘检测, 得到的图像可见边缘的改善与优化。
同时,此次课设仍然有不完善的地方为了得到更好的图像,必要的腐蚀运算,关于
“蛀虫”与“大米”的故事。 腐蚀后的世界变得相对比较空荡了,为了加深物体的存在感,膨胀运算,即关于“青蛙”与“害虫”的故事。我们并没有在此时实现。其次,再次优化图像元,通过恢复 OV7725 的 Bayer 阵列, 得到RGB888 的 24Bit 图像,为未来彩色图像算法处理打下基础, 也还有待完善。
其实我们能做的还是很多,包括 3A 技术:即自动对焦(AF)、自动曝光(AE)和自动白平衡(AWB),非局部均匀,直方图均衡,对比度增强、低照度算法, 2D/3D降噪等等。
这样做我们快速方便地得到了 3*3 像素阵列,不过计算第一次与第二次得到的 3*3 行像素不完整,同时在计算中,最后一行的像素没有参与。 同时每行的第一、第二、 最后个像素也是如此。这里给出的只是一个 VIP算法 3X3 像素阵列生成的模板,更完美的方式可以通过镜像方法实现。




与我联系 ,发送邮件到[email protected]