使用Tensorflow搭建并训练TextCNN模型,对文本进行分类
最近有学习关于文本分类的深度学习模型,最先接触的就是TextCNN模型,该模型看起来非常简单效果也非常好,在此简单记录下整个模型的搭建以及训练过程。通过本博文,你可以自己搭建并训练一个简单的文本分类模型,本文的代码注释非常详细。
使用的开发环境:python3(Anaconda管理)、Tensorflow1.13.1
本文主要分为以下几个部分进行展开讲解:
(1)TextCNN原理
(2)模型的搭建
(3)训练数据的准备
(4)模型的训练
(5)知识点补充
TextCNN原理
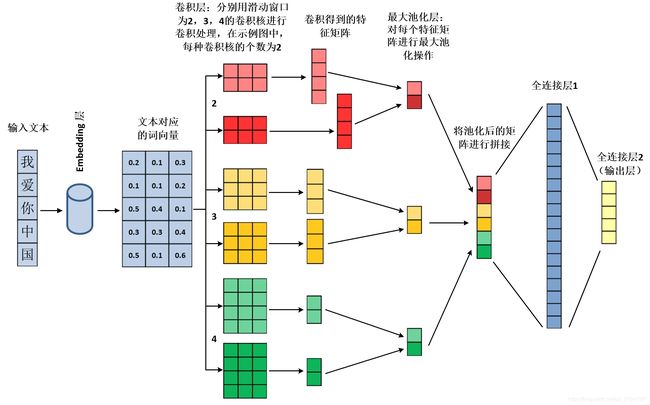
如图所示,展示了整个textcnn的模型结构,主要流程可分为以下几步:
1)将中文文本通过embedding层转换为词向量,图中词向量以三维为例(例如“我”对应的是[0.2, 0.1, 0.3]词向量),在本文代码中采用的是64维。(本图中省略了将中文文本转换为对应词id的过程)
2)通过不同的滑动窗口进行卷积处理,图中以滑动窗口分别为2、3、4为例,并且每种滑动窗口的卷积核个数为2,实际使用过程中每种滑动窗口的卷积核个数可自己设定,本文代码中采用的是64。
3)对卷积操作生成的特征矩阵使用最大池化处理。
4)将池化后的特征矩阵进行拼接。
5)将特征矩阵进行扁平化或压缩维度,图中未绘制。
6)连接全连接层1
7)连接全连接层2,通过activation=softmax输出每个类别的概率
网络模型的搭建
在模型的搭建之前,我们先建立一个python项目,目录结构如图所示:
+testCnnProject
+cnews
-cnews.test.txt
-cnews.train.txt
-cnews.val.txt
-cnews.vocab.txt
+log
-main.py
-model.py
-dataGenerator.py其中的cnews文件夹先不用管在后面的数据准备中会进行讲解,log文件夹是用来存放我们训练过程中生成的tensorboard文件以及模型的权重,model.py是用来存放textcnn模型的文件,dataGenerator.py使用来生成数据的文件,main.py是该项目的入口用于调用训练模型。
下面我们开始在model.py文件中编写textcnn模型文件。
该模型使用的是tensorflow包中自带的keras模块,无需另外安装keras包,代码中有详细的注释,很好理解:
model.py
from tensorflow import keras
def text_cnn(seq_length, vocab_size, embedding_dim, num_cla, kernel_num):
"""
seq_length: 输入的文字序列长度
vocab_size: 词汇库的大小
embedding_dim: 生成词向量的特征维度
num_cla: 分类类别
kernel_num::卷积层的卷积核数
"""
# 定义输入层
inputX = keras.layers.Input(shape=(seq_length,), dtype='int32')
# 嵌入层,将词汇的one-hot编码转为词向量
embOut = keras.layers.Embedding(vocab_size, embedding_dim, input_length=seq_length)(inputX)
# 分别使用长度为3,4,5的词窗口去执行卷积, 接着进行最大池化处理
conv1 = keras.layers.Conv1D(kernel_num, 3, padding='valid', strides=1, activation='relu')(embOut)
maxp1 = keras.layers.MaxPool1D(pool_size=int(conv1.shape[1]))(conv1)
conv2 = keras.layers.Conv1D(kernel_num, 4, padding='valid', strides=1, activation='relu')(embOut)
maxp2 = keras.layers.MaxPool1D(pool_size=int(conv2.shape[1]))(conv2)
conv3 = keras.layers.Conv1D(kernel_num, 5, padding='valid', strides=1, activation='relu')(embOut)
maxp3 = keras.layers.MaxPool1D(pool_size=int(conv3.shape[1]))(conv3)
# 合并三个经过卷积和池化后的输出向量
combineCnn = keras.layers.Concatenate(axis=-1)([maxp1, maxp2, maxp3])
# 扁平化
flatCnn = keras.layers.Flatten()(combineCnn)
# 全连接层1,节点数为128
desen1 = keras.layers.Dense(128)(flatCnn)
# 在全连接层1和2之间添加dropout减少训练过程中的过拟合,随机丢弃25%的结点值
dropout = keras.layers.Dropout(0.25)(desen1)
# 为全连接层添加激活函数
densen1Relu = keras.layers.ReLU()(dropout)
# 全连接层2(输出层)
predictY = keras.layers.Dense(num_cla, activation='sofmax')(densen1Relu)
# 指定模型的输入输出层
model = keras.models.Model(inputs=inputX, ouputs=predictY)
# 指定loss的计算方法,设置优化器,编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
return model
训练文件的准备
简单介绍下数据集,数据集包含十个类别,每个文本对应一个一类。网上找的,具体来源不详。
网盘地址:https://pan.baidu.com/s/1w452Z5eXbQSDQfgEBNUdlg ,提取密码:8cwv
该数据集大概有66M,其中有4个文件:
cnews.train.txt (包含50000个文本,每行代表一个文本,最前面是该文本对应的标签,标签与文本之间用制表符隔开)
cnews.test.txt (包含10000个测试文本,格式与trian相同)
cnews.eval.txt (包含5000个验证文本,格式与train相同)
cnews.vocab.txt (包含一个分词词典,其实就是一个字典,并没有进行分词处理)

下载好后按照之前讲的文件结构放好文件,接着在dataGenerator.py文件中编写用于生成数据的代码:
dataGenerator.py
from tensorflow import keras
from sklearn.preprocessing import LabelEncoder
import random
def content2idList(content, word2id_dict):
"""
该函数的目的是将文本转换为对应的汉字数字id
content:输入的文本
word2id_dict:用于查找转换的字典
"""
idList = []
for word in content: # 遍历每一个汉字
if word in word2id_dict: # 当刚文字在字典中时才进行转换,否则丢弃
idList.append(word2id_dict[word])
return idList
def generatorInfo(batch_size, seq_length, num_classes, file_name):
"""
batch_size:生成数据的batch size
seq_length:输入文字序列长度
num_classes:文本的类别数
file_name:读取文件的路径
"""
# 读取词库文件
with open('./cnews/cnews.vocab.txt', encoding='utf-8') as file:
vocabulary_list = [k.strip() for k in file.readlines()]
word2id_dict = dict([(b, a) for a, b in enumerate(vocabulary_list)])
# 读取文本文件
with open(file_name, encoding='utf-8') as file:
line_list = [k.strip() for k in file.readlines()]
data_label_list = [] # 创建数据标签文件
data_content_list = [] # 创建数据文本文件
for k in line_list:
t = k.split(maxsplit=1)
data_label_list.append(t[0])
data_content_list.append(t[1])
data_id_list = [content2idList(content, word2id_dict) for content in data_content_list] # 将文本数据转换拿为数字序列
# 将list数据类型转换为ndarray数据类型,并按照seq_length长度去统一化文本序列长度,
# 若长度超过设定值将其截断保留后半部分,若长度不足前面补0
data_X = keras.preprocessing.sequence.pad_sequences(data_id_list, seq_length, truncating='pre')
labelEncoder = LabelEncoder()
data_y = labelEncoder.fit_transform(data_label_list) # 将文字标签转为数字标签
data_Y = keras.utils.to_categorical(data_y, num_classes) # 将数字标签转为one-hot标签
while True:
selected_index = random.sample(list(range(len(data_y))), k=batch_size) # 按照数据集合的长度随机抽取batch_size个数据的index
batch_X = data_X[selected_index] # 随机抽取的文本信息(数字化序列)
batch_Y = data_Y[selected_index] # 随机抽取的标签信息(one-hot编码)
yield (batch_X, batch_Y)
网络模型的训练
现在我们的训练数据已经准备到位,模型也已经搭建完成,接着我们开始训练模型:
main.py
from model import text_cnn
from dataGenerator import generatorInfo
from tensorflow import keras
vocab_size = 5000 # 词汇库大小
seq_length = 600 # 输入文本序列长度
embedding_dim = 64 # embedding层输出词向量维度
num_classes = 10 # 分类类别
kernel_num=64 # 卷积核数
trianBatchSize = 64 # 训练时的batch size
evalBatchSize = 200 # 验证时的batch size
steps_per_epoch = 50000 // trianBatchSize # 一个epoch对应的训练步数
epoch = 2 # 训练的epoch数
logdir = './log' # tensorbard训练信息以及train_weights的保存位置
trainFileName = './cnews/cnews.train.txt' # 训练文件的路径
evalFileName = './cnews/cnews.test.txt' # 验证文件的路径
model = text_cnn(seq_length=seq_length, # 初始化模型
vocab_size=vocab_size,
embedding_dim=embedding_dim,
num_cla=num_classes,
kernel_num=kernel_num)
trainGenerator = generatorInfo(trianBatchSize, seq_length, num_classes, trainFileName)
evalGenerator = generatorInfo(evalBatchSize, seq_length, num_classes, evalFileName)
def lrSchedule(epoch): # 自定义学习率变化
lr = keras.backend.get_value(model.optimizer.lr)
if epoch % 1 == 0 and epoch != 0:
lr = lr * 0.5
return lr
log = keras.callbacks.TensorBoard(log_dir=logdir, update_freq='epoch') # 调用tensorboard
reduceLr = keras.callbacks.LearningRateScheduler(lrSchedule, verbose=1) # 调用自定义学习率函数
model.fit_generator(generator=trainGenerator,
steps_per_epoch=steps_per_epoch,
epochs=epoch,
validation_data=evalGenerator,
validation_steps=10,
callbacks=[log, reduceLr])
model.save_weights(logdir + 'train_weights.h5') 知识点补充
首先说下我个人理解的文本分类整个完整流程:
(1)使用类似jieba的中文分词库对整个训练集进行中文分词
(2)统计词汇的出现评率,删除部分低频词
(3)根据禁用词库滤除禁用词
(4)根据生成的词库对训练集进行分词处理,只保留词库中已有的词汇,词汇之间用空格隔开
(5)分词后使用word2vec训练词向量模型(该步骤是可选项,可以不做)
(6)搭建文本训练模型,例如TextCNN(若进行了第五步操作,使用训练好的词向量weights初始化embdding层参数)
(7)训练模型,调参有更高的需求的可以改进模型