Mapreduce多条数据去重处理
课程原地址:http://hbust.shiyanbar.com/course/91079
上课老师:李歆
实验时间:20180524
地点:云桌面
实验人:郭畅
【实验目的】
1) 理解mapreduce执行原理
2) 理解map,reduce阶段
3) 熟悉map和reduce代码的编写
【实验原理】
需求:
把指定的数据信息以单条记录的方式保存在文本文件source.txt中并存放到指定的位置,该位置可以是本地,也可以是hdfs分布式系统。
原始数据
2012-3-1 a
2012-3-2 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-7 c
2012-3-3 c
2012-3-1 b
2012-3-2 a
2012-3-3 b
2012-3-4 d
2012-3-5 a
2012-3-6 c
2012-3-7 d
2012-3-3 c
数据输出:
2012-3-1 a
2012-3-1 b
2012-3-2 a
2012-3-2 b
2012-3-3 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-6 c
2012-3-7 c
2012-3-7 d
数据去重的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。具体就是reduce的输入应该以数据作为key,而对value-list则没有要求。当reduce接收到一个`
【实验环境】
本次环境是:centos6.5 + jdk1.7.0_79 + hadoop2.4.1 + eclipse
日志文件source.txt存放在桌面名为`分布式计算MapReduce开发基础`目录下的相应章节中对应的实验名下的文件夹中找寻。
jar包在桌面名为`lib`文件夹下。
工具在/simple/soft目录下
【实验步骤】
一、项目准备阶段
1.1 在linux系统的命令终端上切换到/simple目录,执行命令:touch source.txt创建一个文件并把上面的记录数据信息拷贝到/simple/source.txt文件中并查看source.txt文件内容。如图1所示
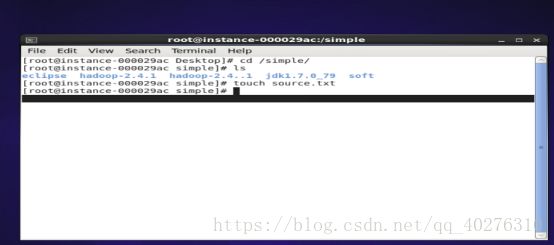
图1
1.2 在simple目录可以通过执行命令:ls查看到/simple/目录下source.txt文件。如图2所示
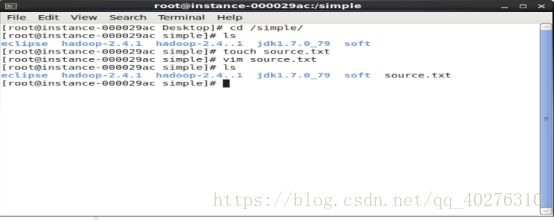
图2
1.3 本案例因为需要用到hadoop的计算,所以在编写程序之前需要先启动yarn服务,可以在命令终端执行命令:start-all.sh 把hdfs和yarn服务启动。(查看服务启动共有6项,如果缺少请执行stop-all.sh关闭,重新启动)。如图3所示
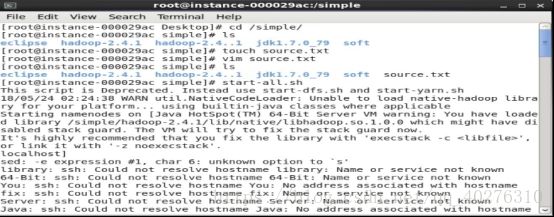
图3
二 程序编写
2.1 在eclipse中的项目列表中,右键点击,选择“new“—>”Java Project…”新建一个项目“DeduplicationInfo” 。 如图4所示

图4
2.2 在项目src目录下,右键点击,选择“新建”创建一个类文件名称为“DeduplicationMapper”并指定包名” com.simple.deduplication” 。如图5所示
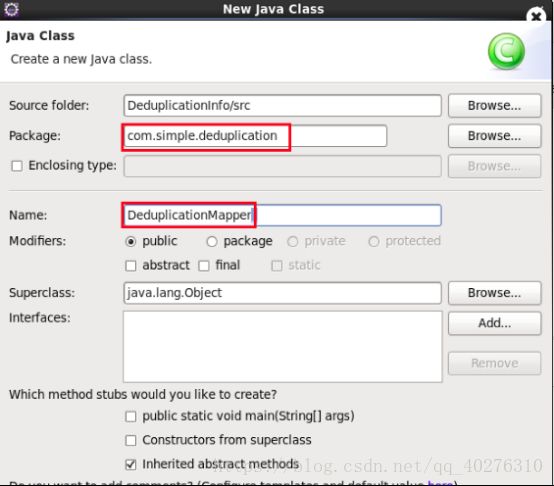
图5
2.3 在编写“DeduplicationMapper”类之前需要把hadoop相关的jar包导入,首先在项目根目录下创建一个文件夹lib并把指定位置中的包放入该文件中 。如图6所示
图6
2.4 把lib下所有的jar包导入到环境变量,首先全选lib文件夹下的jar包文件,右键点击,选择“build path”-->“add to build path”,添加后,发现在项目下多一个列表项“Referenced Libraries”。如图7所示
图7
2.5 让类“DeduplicationMapper”继承类Mapper同时指定需要的参数类型,根据业务逻辑修改map类的内容如下。
package com.simple.deduplication;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class DeduplicationMapper extends
Mapper {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
//按行读取信息并作为mapper的输出键,mapper的输出值置为空文本即可
Text line = value;
context.write(line, new Text(""));
}
}
2.6 在项目src目录下指定的包名” com.simple.deduplication”下右键点击,新建一个类名为“DeduplicationReducer “并继承Reducer类,然后添加该类中的代码内容如下所示。
package com.simple.deduplication;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class DeduplicationReducer extends
Reducer {
public void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
//Reducer阶段直接按键输出即可,键直接可以实现去重
context.write(key, new Text(""));
}
}
2.7 在项目src目录下指定的包名” com.simple.deduplication”下右键点击,新建一个测试主类名为“TestDeduplication “并指定main主方法。如图8所示
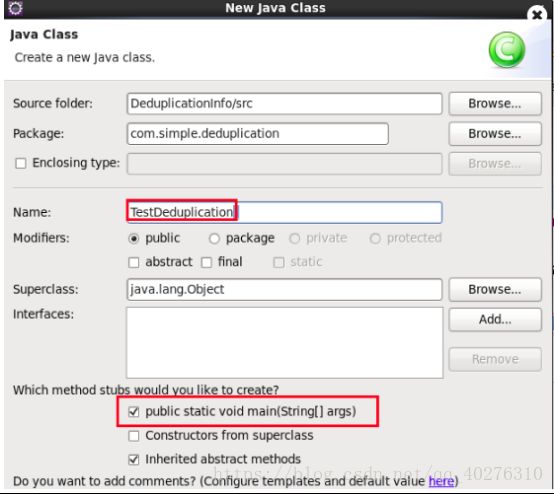
图8
2.8添加代码如下所示。
package com.simple.deduplication;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TestDeduplication {
public static void main(String[] args) throws Exception{
//获取作业对象
Job job = Job.getInstance(new Configuration());
//设置主类
job.setJarByClass(TestDeduplication.class);
//设置job参数
job.setMapperClass(DeduplicationMapper.class);
job.setReducerClass(DeduplicationReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置job输入输出
FileInputFormat.addInputPath(job, new Path("file:///simple/source.txt"));
FileOutputFormat.setOutputPath(job, new Path("file:///simple/output"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2.9 按照以上的步骤,把mapper和reducer阶段以及测试代码编写完毕之后,选中测试类“TestDeduplication “,右键点击选择”Run as”--->”Java Application”,查看控制台显示内容查看是否正确执行。如图9所示
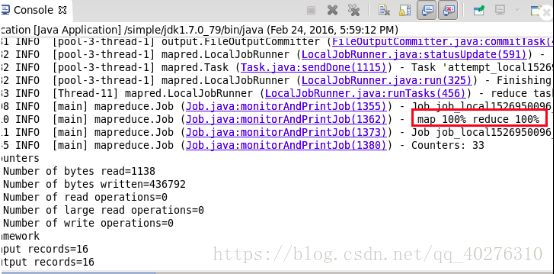
图9
2.10 程序执行完毕之后,可以到输出信息目录下,执行查看命令cat part-r-00000查看对数据处理后产生的结果。如图10所示

图10