吴恩达机器学习笔记
吴恩达机器学习笔记
- 神经网络方面的一个巨大突破是从sigmoid函数转换到一个ReLU函数
- 机器学习
- 无监督学习
- 监督学习
- 分类
- 回归
- 单变量线性回归(Linear Regression with One Variable)
- 房价预测
- 代价函数
- 梯度下降
- 梯度下降的线性回归
- 线性代数回顾
- 矩阵和向量(Matrices and Vectors)
- 加法和标量乘法
- 矩阵向量乘法
- 多变量线性回归(Linear Regression with Multiple Variables)
- 多维特征
- 多变量梯度下降
- 梯度下降法实践1-特征缩放
- 梯度下降法实践2-学习率
- 特征和多项式回归
- 线性回归和多项式回归的区别和适用场景
- 正规方程 Normal Equation
- 矩阵的求导法则:
- 逻辑回归
- 分类问题
- 逻辑回归模型的假设
- 代价函数
- 多类别分类
- 正则化(Regularization)
- 过拟合
- 代价函数
- 正则化线性回归(Regularized Linear Regression)
- 正则化的逻辑回归模型(Regularized Logistic Regression)
- 神经网络:表述(Neural Networks: Representation)
- 非线性假设
- 模型表示I & 前向传播算法(Model Representation I)
- 模型表示2
- 为什么神经网络相比于逻辑回归和线性回归更有优势?
- 特征和直观理解1
- 用单层神经网络表示逻辑运算(与、或)
- 与运算
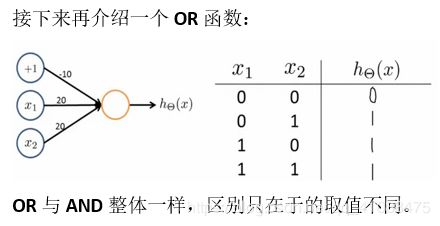
- 或运算
- 更为复杂的逻辑运算符构建(函数构建)&得到更加厉害的特征值
- 多类分类
- 神经网络的学习(Neural Networks: Learning)
- 神经网络是线性回归、逻辑回归的升级,无论是线性回归还是逻辑回归,都是使用原始特征进行计算,但神经网络可以从隐藏层(中间层)中获得更为厉害的特征,而不是单单是使用原始特征
- 神经每迭代一次:1、正向传播,走一遍训练集,得到每个样本的预测结果;2、计算代价和(每个训练样本的代价和);3、通过反向传播计算每一层的代价,并更新每一层的权重;(当然这是对批量梯度下降算法而言,当训练集很大的时候,计算量就太大了,每更新一次参数都需要走完整个训练集。而会采用随机梯度下降的算法,并不是每迭代一次,都要考虑整个训练集,仅仅只需要考虑一个训练样本,每走一个训练样本就更新一次参数(即:每一次迭代只考需要去拟合一个样本),但需要对训练样本进行一次随机打乱的预处理,这会收敛得更快。)
- 反向传播算法(Backpropagation Algorithm)
- == 注意:每一层的输出都需要经过激活函数处理并添加偏置单元,偏置单元可以直接置为1==
- 每一层的加权和再经过激活函数才是神经元的值
- 反向传播算法的直观理解
- 随机初始化
- 小结:如何构建和训练一个神经网络
- 跳看
- 查准率和查全率
- 大规模机器学习
- 随机梯度下降法( Stochastic Gradient Descent)
- 批量梯度下降算法(Batch Gradient Descent)和随机梯度下降算法(Stochastic Gradient Descent)的比较
- 小批量梯度下降(Mini-Batch Gradient Descent)
- 批量梯度下降、随机梯度下降、小批量梯度下降之间的区别
- 随机梯度下降收敛
神经网络方面的一个巨大突破是从sigmoid函数转换到一个ReLU函数
作为一个具体的例子,神经网络方面的一个巨大突破是从sigmoid函数转换到一个ReLU函数,这个函数我们在之前的课程里提到过。

如果你无法理解刚才我说的某个细节,也不需要担心,可以知道的一个使用sigmoid函数和机器学习问题是,在这个区域,也就是这个sigmoid函数的梯度会接近零,所以学习的速度会变得非常缓慢,因为当你实现梯度下降以及梯度接近零的时候,参数会更新的很慢,所以学习的速率也会变的很慢,而通过改变这个被叫做激活函数的东西,神经网络换用这一个函数,叫做ReLU的函数(修正线性单元),ReLU它的梯度对于所有输入的负值都是零,因此梯度更加不会趋向逐渐减少到零。而这里的梯度,这条线的斜率在这左边是零,仅仅通过将Sigmod函数转换成ReLU函数,便能够使得一个叫做梯度下降(gradient descent)的算法运行的更快,这就是一个或许相对比较简单的算法创新的例子。
机器学习
无监督学习


在无监督学习中,我们已知的数据。看上去有点不一样,不同于监督学习的数据的样子,即无监督学习中没有任何的标签或者是有相同的标签或者就是没标签。所以我们已知数据集,却不知如何处理,也未告知每个数据点是什么。别的都不知道,就是一个数据集。你能从数据中找到某种结构吗?针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。这是一个,那是另一个,二者不同。是的,无监督学习算法可能会把这些数据分成两个不同的簇。所以叫做聚类算法。事实证明,它能被用在很多地方。
监督学习
分类
一种最常见的监督学习方式,叫做分类问题,当我们想要预测离散的输出值,例如,我们正在寻找癌症肿瘤,并想要确定肿瘤是良性的还是恶性的,这就是0/1离散输出的问题。更进一步来说,在监督学习中我们有一个数据集,这个数据集被称训练集。
回归
还有一种监督学习方式是回归问题,回归一词指的是,我们根据之前的数据预测出一个准确的输出值,对于这个例子就是价格
单变量线性回归(Linear Regression with One Variable)
房价预测


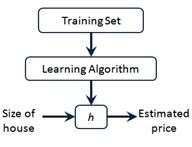
![]()
代价函数

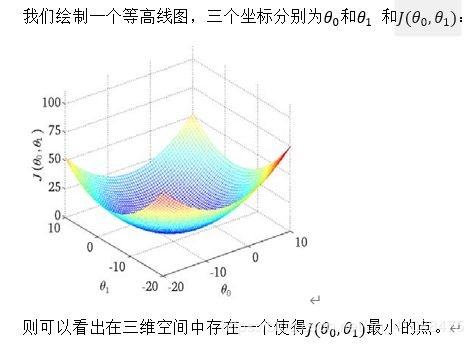
代价函数也被称作平方误差函数,有时也被称为平方误差代价函数。我们之所以要求出误差的平方和,是因为误差平方代价函数,对于大多数问题,特别是回归问题,都是一个合理的选择。还有其他的代价函数也能很好地发挥作用,但是平方误差代价函数可能是解决回归问题最常用的手段了。
在后续课程中,我们还会谈论其他的代价函数,但我们刚刚讲的选择是对于大多数线性回归问题非常合理的。
梯度下降

批量梯度下降(batch gradient descent)算法的公式为:
convergence:收敛
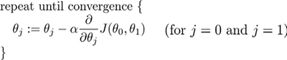
其中a是学习率(learning rate),它决定了我们沿着能让代价函数下降程度最大的方向向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率乘以代价函数的导数。
== 为什么是减号:代价函数的导数>0,代价函数递增,代价函数的导数<0,代价函数递减,所以当导数>0时,代价函数会随着θ的增大而增大,随着θ 的减小而减小,为了使代价函数减小,在导数>0时,θ 应该减小,同理,当导数<0时,代价函数会随着θ 的增大而减小,因此为了使代价函数减小,θ 应该增大 ==

在这个表达式中,如果你要更新这个等式,你需要同时更新θ_0和θ_1
这是正确实现同时更新的方法。我不打算解释为什么你需要同时更新,同时更新是梯度下降中的一种常用方法。我们之后会讲到,同步更新是更自然的实现方法。当人们谈到梯度下降时,他们的意思就是同步更新。
梯度下降的线性回归
梯度下降算法和线性回归算法比较如图:


我们刚刚使用的算法,有时也称为批量梯度下降。实际上,在机器学习中,通常不太会给算法起名字,但这个名字”批量梯度下降”,指的是在梯度下降的每一步中,我们都用到了所有的训练样本,在梯度下降中,在计算微分求导项时,我们需要进行求和运算,所以,在每一个单独的梯度下降中,我们最终都要计算这样一个东西,这个项需要对所有m个训练样本求和。因此,批量梯度下降法这个名字说明了我们需要考虑所有这一"批"训练样本,而事实上,有时也有其他类型的梯度下降法,不是这种"批量"型的,不考虑整个的训练集,而是每次只关注训练集中的一些小的子集。在后面的课程中,我们也将介绍这些方法。
但就目前而言,应用刚刚学到的算法,你应该已经掌握了批量梯度算法,并且能把它应用到线性回归中了,这就是用于线性回归的梯度下降法。
如果你之前学过线性代数,有些同学之前可能已经学过高等线性代数,你应该知道有一种计算代价函数J最小值的数值解法,不需要梯度下降这种迭代算法。在后面的课程中,我们也会谈到这个方法,它可以在不需要多步梯度下降的情况下,也能解出代价函数J的最小值,这是另一种称为正规方程(normal equations)的方法。实际上在数据量较大的情况下,梯度下降法比正规方程要更适用一些。
现在我们已经掌握了梯度下降,我们可以在不同的环境中使用梯度下降法,我们还将在不同的机器学习问题中大量地使用它。所以,祝贺大家成功学会你的第一个机器学习算法。
在下一段视频中,告诉你泛化的梯度下降算法,这将使梯度下降更加强大。
线性代数回顾
矩阵和向量(Matrices and Vectors)


加法和标量乘法

矩阵向量乘法

多变量线性回归(Linear Regression with Multiple Variables)
多维特征


多变量梯度下降

我们开始随机选择一系列的参数值,计算所有的预测结果后,再给所有的参数一个新的值,如此循环直到收敛。
梯度下降法实践1-特征缩放
在我们面对多维特征问题的时候,我们要保证这些特征都具有相近的尺度,这将帮助梯度下降算法更快地收敛。
以房价问题为例,假设我们使用两个特征,房屋的尺寸和房间的数量,尺寸的值为 0-2000平方英尺,而房间数量的值则是0-5,以两个参数分别为横纵坐标,绘制代价函数的等高线图能,看出图像会显得很扁,梯度下降算法需要非常多次的迭代才能收敛。
解决的方法是尝试将所有特征的尺度都尽量缩放到-1到1之间。如图:

![]()

梯度下降法实践2-学习率


特征和多项式回归
线性回归和多项式回归的区别和适用场景


线性回归并不适用于所有数据,有时我们需要曲线来适应我们的数据

== 注:如果我们采用多项式回归模型,在运行梯度下降算法前,特征缩放非常有必要。 ==
正规方程 Normal Equation

注:对于那些不可逆的矩阵(通常是因为特征之间不独立,如同时包含英尺为单位的尺寸和米为单位的尺寸两个特征,也有可能是特征数量大于训练集的数量),正规方程方法是不能用的。

总结一下,只要特征变量的数目并不大,标准方程是一个很好的计算参数θ的替代方法。具体地说,只要特征变量数量小于一万,我通常使用标准方程法,而不使用梯度下降法。
随着我们要讲的学习算法越来越复杂,例如,当我们讲到分类算法,像逻辑回归算法,我们会看到,实际上对于那些算法,并不能使用标准方程法。对于那些更复杂的学习算法,我们将不得不仍然使用梯度下降法。因此,梯度下降法是一个非常有用的算法,可以用在有大量特征变量的线性回归问题。或者我们以后在课程中,会讲到的一些其他的算法,因为标准方程法不适合或者不能用在它们上。但对于这个特定的线性回归模型,标准方程法是一个比梯度下降法更快的替代算法。所以,根据具体的问题,以及你的特征变量的数量,这两种算法都是值得学习的。
矩阵的求导法则:

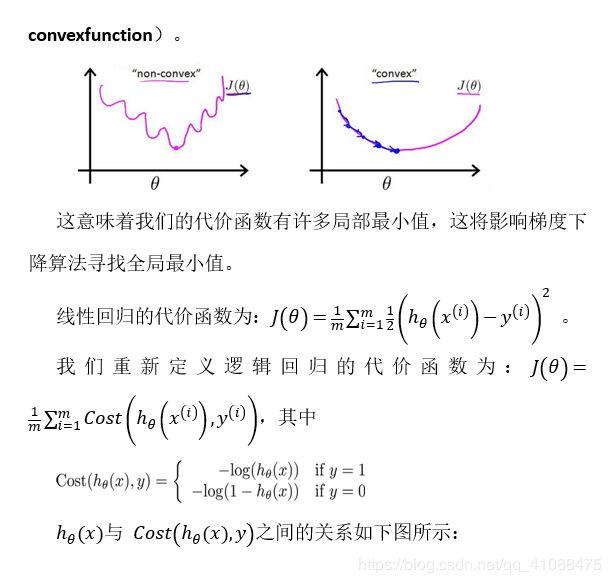
逻辑回归
直观理解:逻辑回归就是在线性回归的输出上加了一个sigmoid 激活函数,使得输出取值[0,1]
分类问题



逻辑回归模型的假设


代价函数




多类别分类



![]()
正则化(Regularization)
过拟合

代价函数




正则化线性回归(Regularized Linear Regression)


正则化的逻辑回归模型(Regularized Logistic Regression)




![]()
神经网络:表述(Neural Networks: Representation)
非线性假设


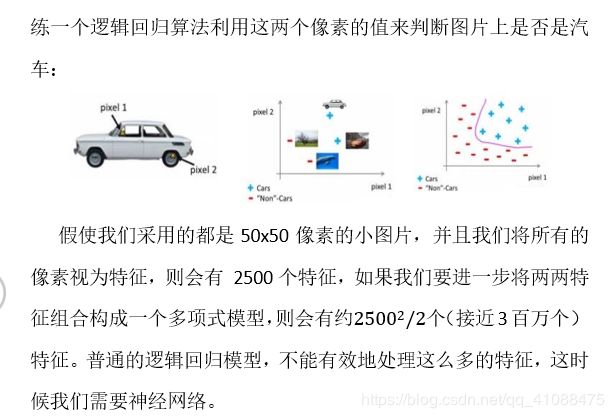
模型表示I & 前向传播算法(Model Representation I)




模型表示2


为什么神经网络相比于逻辑回归和线性回归更有优势?


特征和直观理解1

用单层神经网络表示逻辑运算(与、或)

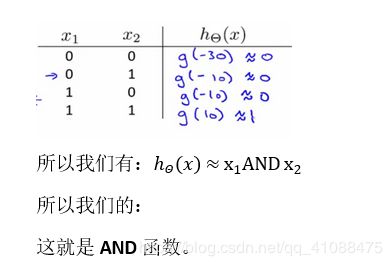
与运算
注意:输出还需要经过激活函数

或运算
更为复杂的逻辑运算符构建(函数构建)&得到更加厉害的特征值


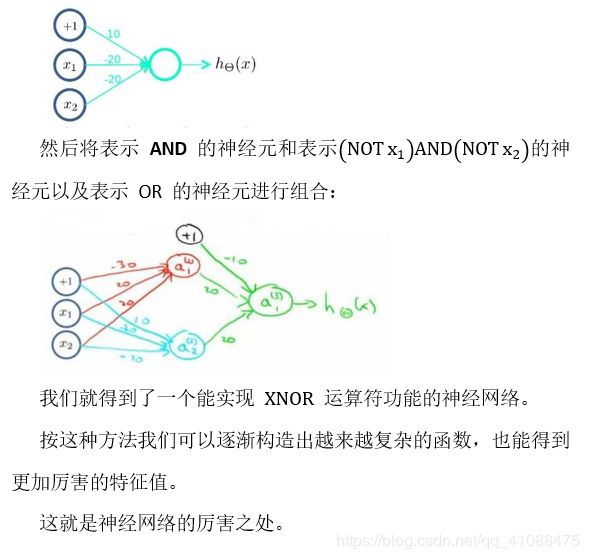
多类分类


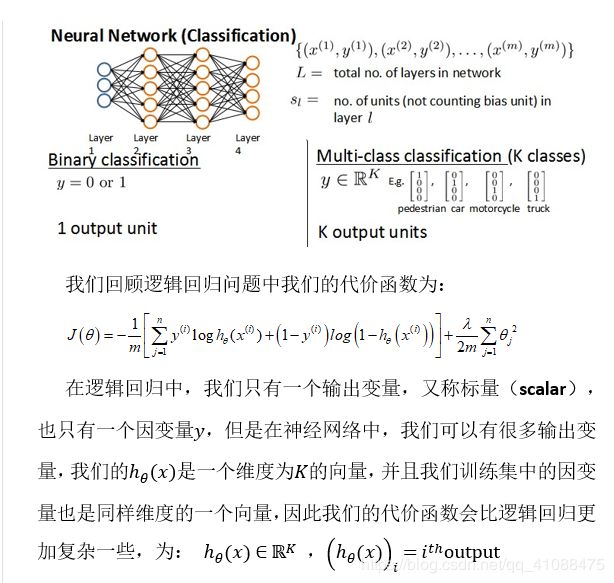
神经网络的学习(Neural Networks: Learning)
有点乱,对于k类的代价函数不是特别懂
神经网络是线性回归、逻辑回归的升级,无论是线性回归还是逻辑回归,都是使用原始特征进行计算,但神经网络可以从隐藏层(中间层)中获得更为厉害的特征,而不是单单是使用原始特征
神经每迭代一次:1、正向传播,走一遍训练集,得到每个样本的预测结果;2、计算代价和(每个训练样本的代价和);3、通过反向传播计算每一层的代价,并更新每一层的权重;(当然这是对批量梯度下降算法而言,当训练集很大的时候,计算量就太大了,每更新一次参数都需要走完整个训练集。而会采用随机梯度下降的算法,并不是每迭代一次,都要考虑整个训练集,仅仅只需要考虑一个训练样本,每走一个训练样本就更新一次参数(即:每一次迭代只考需要去拟合一个样本),但需要对训练样本进行一次随机打乱的预处理,这会收敛得更快。)


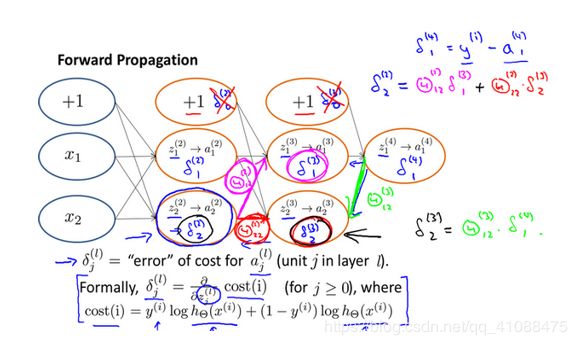
反向传播算法(Backpropagation Algorithm)

== 注意:每一层的输出都需要经过激活函数处理并添加偏置单元,偏置单元可以直接置为1==
每一层的加权和再经过激活函数才是神经元的值

接下来的数学过程,跳过,没看懂
反向传播算法的直观理解
看了一下视频,只知道了代价是如何进行传播的,但是并没有将如何求偏导
随机初始化

小结:如何构建和训练一个神经网络


跳看
查准率和查全率

大规模机器学习

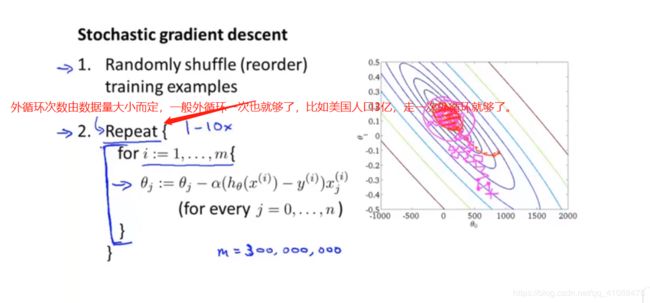
随机梯度下降法( Stochastic Gradient Descent)
视频讲得很清楚
批量梯度下降算法(Batch Gradient Descent)和随机梯度下降算法(Stochastic Gradient Descent)的比较
神经每迭代一次:1、正向传播,走一遍训练集,得到每个样本的预测结果;2、计算代价和(每个训练样本的代价和);3、通过反向传播计算每一层的代价,并更新每一层的权重;(当然这是对批量梯度下降算法而言,当训练集很大的时候,计算量就太大了,每更新一次参数都需要走完整个训练集。而会采用随机梯度下降的算法,并不是每迭代一次,都要考虑整个训练集,仅仅只需要考虑一个训练样本,每走一个训练样本就更新一次参数(即:每一次迭代只考需要去拟合一个样本),但需要对训练样本进行一次随机打乱的预处理,这会收敛得更快。)

小批量梯度下降(Mini-Batch Gradient Descent)
看了视频,讲得也很清楚
小批量梯度下降算法是介于批量梯度下降算法和随机梯度下降算法之间的算法,每计算b个训练实例(b一般去2-100,吴老师一般取10),便更新一次参数 θ 。

批量梯度下降、随机梯度下降、小批量梯度下降之间的区别
3亿的美国人口普查数据作为训练集
批量梯度下降:需要走完一遍训练集才会更新一次参数,这算完成一次迭代
随机梯度下降:每走一个训练实例就会更新一次参数,算完成一次迭代。(需要先对训练数据进行随机打乱)
小批量梯度下降:每b(mini-batch size)个训练实例更新一次参数,算完成一次迭代。
随机梯度下降收敛

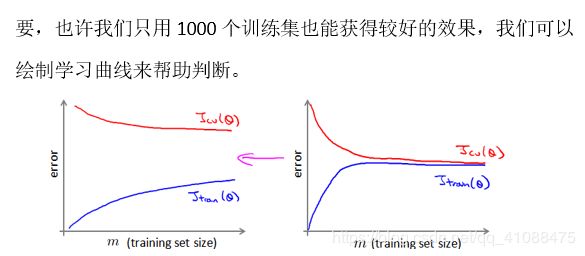
比如下图中,蓝色曲线取的迭代次数x为1000,也就是说采用随机梯度下降,每跑一个样本,在更新权重之前,计算一下cost,当跑完1000个样本时(也就是完成1000次迭代),也就有1000个cost,求这1000个cost的平均值,作为图上的一点。
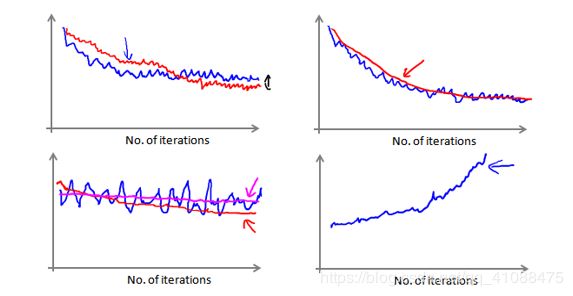
左上:这是比较好的下降曲线,随着迭代次数的增加,平均代价逐渐减少。在箭头所指的地方,可以认为已经收敛,因为cost已经趋于平缓。红色是用了更小的学习率,可能可以收敛到更好的位置。
右上:也是比较好的下降曲线,蓝色是每1000次迭代计算一个平均cost,红色是每5000次迭代计算一个平均cost,可以看出红色的趋势可以更明显。
左下:当我们绘制这样的图表时,可能会得到一个颠簸不平但是不会明显减少的函数图像(如上面左下图中蓝线所示)。我们可以增加α来使得函数更加平缓,也许便能看出下降的趋势了(如上面左下图中红线所示);或者可能函数图表仍然是颠簸不平且不下降的(如紫色线所示),那么我们的模型本身可能存在一些错误,也就是没有收敛。
右下:如果我们得到的曲线如上面右下方所示,不断地上升,那么我们可能会需要选择一个较小的学习率α,学习率选择出错,因为正常情况应该是,loss逐渐下降并趋于平缓(收敛)或始终上下起伏(不收敛)。
总结下,这段视频中,我们介绍了一种方法,近似地监测出随机梯度下降算法在最优化代价函数中的表现,这种方法不需要定时地扫描整个训练集,来算出整个样本集的代价函数,而是只需要每次对最后1000个,或者多少个样本,求一下平均值。应用这种方法,你既可以保证随机梯度下降法正在正常运转和收敛,也可以用它来调整学习速率α的大小。