【华为云-上云之路】网络AI模型开发(2)数据入湖、数据处理
本篇文章主要分享在华为云NAIE的数据服务中,进行数据入湖、数据处理。
目录
数据入湖
数据处理
数据入湖
简介
我们在华为云NAIE开通“数据资产管理服务”后,把数据上传到数据湖OBS中。其中数据可以从本地文件、租户OBS、数据湖OBS、HIVE、DWS等方式上传。
流程
1)先准备数据,以.csv为后缀的文件;(本文中使用本地文件上传)
2)进入数据资产管理服务,选择“治理工具”下面的“数据加载”,把本地的数据上传数据到湖OBS中。
特点
1)数据输入端:本地文件、租户OBS、数据湖OBS、HIVE、DWS等方式;
2)数据生成端:数据湖OBS。
数据资产管理服务 页面

进入服务;

选择“治理工具”下面的“数据加载”,点击“创建任务”

关于上传数据湖OBS的路径,可以根据实际情况选择,记得就好,后面要用到的哈。
注意:数据输入端:本地文件、租户OBS、数据湖OBS、HIVE、DWS等方式;根据实际情况选择哈。
如果想体验一下,可以到网盘拿数据放到本地来上传,链接:https://pan.baidu.com/s/1KZiGw1_3EFnYBSKzp4VVlQ 提取码:ifcj
点击底下的连接测试,当两端都连通后,可以点击“提交”

查看状态,在运行中,等待一会变成运行成功,就可以啦。

数据处理
简介
上传到数据湖OBS数据,进行处理;比如数据清洗,数据过滤,增删数据等,也可以进行读写OBS的基本方法、参数的添加和使用。
特点
1)使用Python语言进行处理的
2)线上填写代码;
3)支持不同的引擎框架(Horovod、MXNet、PyTorch、Ray、Spark_MLlib、TensorFlow、XGBoost-Sklearn),Python版本来运行;
操作流程
来到“数据处理”,点击“新增作业”

创建作业:填写名称、选择作业位置等

点击“下一步”,

main.py是官方的实例代码,作用:演示读写OBS的基本方法、参数的添加和使用方法
参考链接:https://github.com/huaweicloud/ModelArts-Lab/blob/master/docs/moxing_api_doc/MoXing_API_File.md
"""
Sample Code, you can delete this file. Or clear this file content.
Execution engine suggests choosing TensorFlow/MXNet/PyTorch.
Python version 3.6 or higher.
Functional description
1. Parsing running parameters. See function argument_init
2. Reading csv file from OBS. See function read_from_obs
3. Writing data to OBS. See function read_from_obs
moxing API document [https://github.com/huaweicloud/ModelArts-Lab/blob/master/docs/moxing_api_doc/MoXing_API_File.md]
"""
import argparse
import logging
import os
import pandas as pd
# Adapt to ModelArts runtime environment
try:
import moxing as mox
mox.file.shift('os', 'mox')
except (ModuleNotFoundError, AttributeError):
mox = None
logging.info(
'Not exist moxing module. if running on modelarts engine. please select TensorFlow engine. Python Version is 3.6')
def argument_init():
"""
Parsing running parameters.
:return: Running params
"""
logging.info('Start to init running argument...')
parser = argparse.ArgumentParser(description="pm data process")
parser.add_argument('--data_url', type=str, default='s3://bucket_name/folder/', help='System preset parameters.')
parser.add_argument('--train_url', type=str, default='s3://bucket_name/folder/', help='System preset parameters.')
parser.add_argument('--input_path', type=str, default=None, help='User-defined parameter example.')
parser.add_argument('--output_path', type=str, default=None, help='User-defined parameter example.')
return parser.parse_known_args()
def read_from_obs(input_path):
"""
Reading csv file from OBS
:param input_path: OBS path. such as s3://bucket/folder/
:return: data frame
"""
logging.info('start to read file from OBS. input_path=%s' % input_path)
if input_path is None or input_path.endswith('s3://'):
logging.error('input_path is None or not endswith s3://')
return
if not os.path.exists(input_path):
logging.warning('input_path is not exists.')
return None
data_frame = None
for file_name in os.listdir(input_path):
if not file_name.endswith('.csv'):
logging.info('%s is not csv file.' % file_name)
continue
with open(os.path.join(input_path, file_name), 'rb') as f:
data_frame = pd.read_csv(f, encoding='utf-8')
logging.info('success read file. file_name=%s' % file_name)
break
return data_frame
def data_process(data_frame_before_process):
"""
User-defined data processing function
:param data_frame: pandas data frame
:return: Processed data frame
"""
logging.info('start to process data...')
# Start of your own processing code.
# Write your own processing code here.
# End of your own processing code.
logging.info('end to process data...')
return data_frame_after_process
def write_to_obs(data_frame, output_path):
"""
Writing data to OBS.
:param data_frame: pandas data frame
:param output_path: OBS Path. such as s3://bucket/folder/
:return: None
"""
logging.info('start to writing data to OBS. output_path=%s' % output_path)
if data_frame is None:
logging.warning('data_frame is None.')
return
if output_path is None or output_path.endswith('s3://'):
logging.error('output_path is None or not endswith s3://')
return
if not os.path.exists(output_path):
os.makedirs(output_path)
data_frame.to_csv('out.csv', encoding='utf-8', index=False) # write to local
mox.file.copy('out.csv', os.path.join(output_path, 'out.csv')) # copy to obs
logging.info('success write data to obs. output_file=%s' % os.path.join(output_path, 'out.csv'))
if __name__ == '__main__':
logging.info('start to running......')
# parse running argument
args, un_known = argument_init()
# Read from obs
dataframe = read_from_obs(args.input_path)
if dataframe is None:
dataframe = pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]})
# start call your own process function
# dataframe = data_process(dataframe)
# end call your own process function
# Write to obs
write_to_obs(dataframe, args.output_path)
logging.info('finish.....')
根据实际情况修改main.py代码,在代码中是可以传递参数的哈;然后点击“运行”
来到如下页面:

补充一下:
1)执行引擎有如下几种
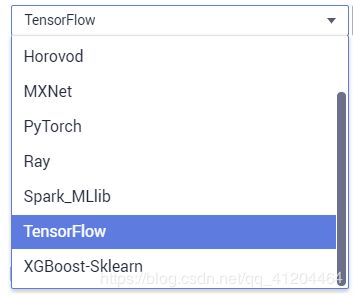
2)如果main.py中不需要外部参数,或者有默认的参数不需要改变,可以不用传递参数。

完成上面的设置后,点击“提交运行”,看到状态是在运行中,等待一会就看到运行成功啦。

好啦,现在完成网络AI模型开发的数据入湖、数据处理。
友情链接: 【华为云-上云之路】网络AI模型开发(1)创建IAM用户、订阅AI服务
福利:华为云--公开课程《网络AI模型开发》
地址:7天玩转网络AI模型开发
华为云官网出品,有视频,有课件,都是免费的。