Hive学习(七)查询
LIKE和RLIKE
-
LIKE:%,_
-
RLIKE:支持Java的正则表达式;例,查找部门号中含有2的部门 :
select * from dept_part where deptno RLIKE '[2]';
大多数情况下,Hive会对JOIN连接对象启动一个MapReduce任务
如:FROM emp e JOIN dept d ON d.deptno = e.deptno JOIN location l ON d.loc = l.loc
首先启动一个任务用于连接e和d,然后再启动一个任务将第一个任务的输出和l进行连接。
即:Hive总是按照从左到右的顺序执行的
排序
1. 全局排序(ORDER BY),一个Reducer
2. 每个MapReduce内部排序(SORT BY)
每个Reducer内部进行排序,即在每个reducer中是有序的,但是对全局结果集来说不是排序的
设置reduce个数:set mapreduce.job.reduces=3; 不写=3即为查看参数值。
select * from student sort by id;
insert overwrite local directory '/opt/module/datas'
row format delimited fields terminated by '\t'
select * from dept_part sort by deptno desc;导出文件为:000000_0、000001_0、000002_0(单个reducer)
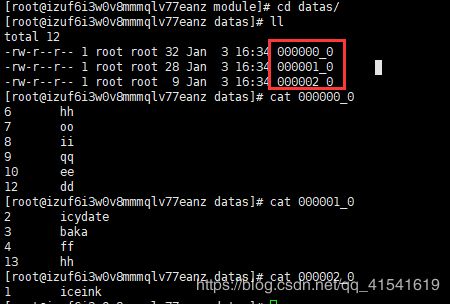
3. 分区排序(DISTRIBUTE BY)
类似MR中的partition,进行分区,结合sort by使用
distribute by语句要写在sort by语句之前,前提:必须分配多reducer
insert overwrite local directory '/opt/module/datas/'
row format delimited fields terminated by '\t'
select * from student_part distribute by dt sort by id;分布在三个文件中,每个文件中相同的dt数据是挨在一起的,即:201909和201912可能分配到一个分区中
4. CLUSTER BY
当distribute by和sort by字段相同时,可以使用cluster by方式。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC
5. 分桶及抽样查询
分区针对的是数据的存储路径;分桶针对的是数据文件
其他常用
在工作中经常遇到,又与其他数据库不同的操作。
1. 取别名``
2. 连接:join(内连接,两表数据都存在,才连接)、left join(左外连接)、right join(右连接),Hive总是按照从左到右的顺序执行的
3. 空字段赋值,nvl(String1, replace_with)
4. 时间类
-
date_format('2019-06-29 00:00:00', 'yyyy-MM-dd HH:mm:ss') -
date_add/date_sub,时间跟天数相加/减
-
date_diff,两个时间相减
-
unix_timestamp(日期, 格式化),日期转时间戳
-
from_unixtime(时间戳,格式化),时间戳转日期
5. concat,字符串拼接
6. count(distinct)优化为先group by再count的方式替换
7. 分区
-
show partitions table_name查看分区 -
分区条件写在where中
-
查询时,尽量加上分区,否则就是全表查询
8. EXPLAIN 查看执行计划
9. 解析json数据:get_json_object(params, '$.source') = 'platform'
案例:json格式数据
{"resIds":"18088389","v":"2","resTypes":"27","source":"platform","moduleCrId":"17654793","_sign":"3475156997D68DDA4C4C47FAE1BE88A2","_timestamp":"1577321309","_nonce":"b4d875ee-7baf-4085-8648-5e6cd8ef18ca"}SELECT * FROM server_request_log
WHERE server = 'bookln' AND dt = '20191226' AND uri = '/moduleService/addResInModule.do'
AND get_json_object(params, '$.source') = 'platform'