第3个Inception模块组包含了3个Inception Module,其中后两个Inception Module的结构非常类似。如图6-13第三幅图所示。
1个Inception Module Mixed_7a,3个分支。
1分支 192 1x1卷积,再接320输出通道的3x3卷积,不过步长为2,padding :VALID,图片尺寸8x8
2分支 4个卷积层,192 1x1 192 1x7 192 7x1 192 3x3 步长 为2,padding:VALID。输出8x8x192
3分支 3x3最大池化层,步长为2,padding:VALID,8x8x768
合并:8x8x(320+192+768)=8x8x1280
输出的图片尺寸被缩小,同时通道数也增加了,tensor的总size在持续下降中。

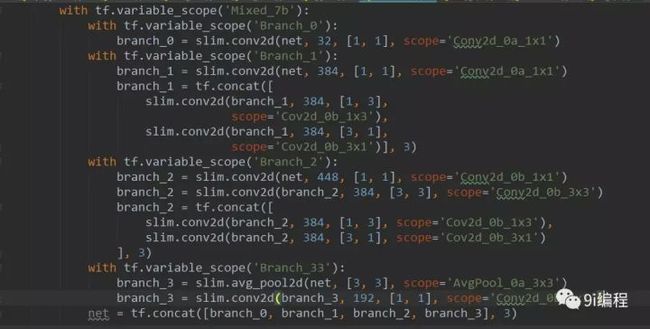
第3个Inception模块组的第2个Inception Module,它有4个分支。
1分支: 320 1x1
2分支: 384 1x1 后 384 1x3 384 3x1 合并:8x8x(384+384)=8x8x768
3分支: 448 1x1,然后384 3x3,分支抓分,384 1x3 384 3x1卷积,合并8x8x768
4分支:3x3的平均池化层后192 1x1。
全部合并:8x8x(320+768+768+192)=8x8x2048
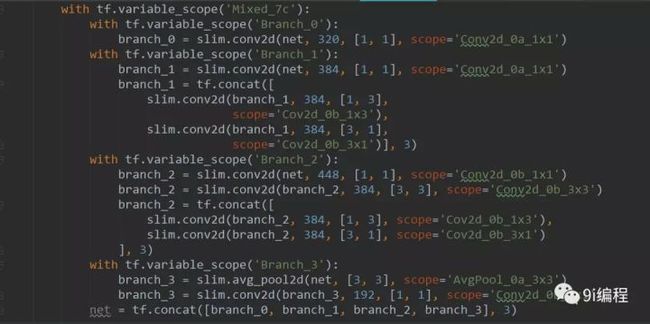
Mixed_7c同最后一个Inception Module,不过它和前面的Mixed_7b完全一致。输出8x8x2048

最终返回net,end_points
至此,Inceptioon V3网络的核心部分,即卷积层部分就完成了。
回忆一下Inception V3的网络结构:首先是5个卷积层和2个池化层交替的普通结构,然后是3个Inception模块组,每个模块组内包含多个结构类似的Inception Module。设计Inception Net的一个重要原则是,图片尺寸是不断缩小的,从299x299通过5个步长为2的卷积层或池化层后,缩小为8x8;同时,输出通道数持续增加,从一开始的3(RGB三色)到2048。从这里可以看出,每一层卷积、池化或Inception模块组的目的都是将空间结构简化,同时将空间信息转化为高阶抽象的特征信息,即将空间的维度转为通道的维度。这一过程同时也使每层输出tensor的总size持续下降,降低了计算量。
一般情况下有4个分支,第1个分支一般是1x1卷积,第2个分支一般是1x1卷积再接分角后(factorized)的1xn和nx1卷积,第3个分支和第2分支类似,但是一般更深一些,第4个分支一般具有最大池化或平均池化。因此,Inception Module是通过组合比较简单的特征抽象(分支1)、比较复杂的特征抽象(分支2和分支3)和一个简化结构的池化层(分支4),一共4种不同程序的特征抽象和变换来有选择地保留不同层次的高阶特征,这样可以最大程序地丰富网络的表达能力。
接下来,我们来实现Inceptio V3网络的最后一部分---全局平均池化,Softmax和Auxiliary Logits。先看函数Inception_v3的输入参数,num_classes即最后需要分类的数量,这里默认的1000是ILSVRC比赛数据集的种类数;is_training标志是否是训练过程,对Batch Normalization和Dropout有影响,只有在训练时Batch Normalization和Dropout才会被启用;dropout_keep_prob即训练时Dropout所需要保留节点的比例,默认为0.8;prediction_fn是最后用来进行分类的函数,这里默认是使用slim.softmax;spatial_squeeze参数标志是否对输出进行squeeze操作(即去除维数为1的维度,比如5x3x1转为5x3);reuse标志是否会对网络和Variable进行重复使用;最后,scope为包含了函数默认参数的环境。首先,使用tf.variable_scope定义网络的name和reuse等参数的默认值,然后使用slim.arg_scope定义Batch Normalization和Dropout的is_training标志的默认值。最后,使用前面定义好的inception_v3_base构筑整个网络的卷积部分,拿到最后一层的输出net和重要节点的字典表end_points。
接下来处理Auxiliary Logits这部分的逻辑,Auxiliary Logits作为辅助分类的节点,对分类结果预测有很大帮助。先使用slim.arg_scope将卷积、最大池化、平均池化的默认步长设为1,默认padding模式设为SAME。然后通过end_points取到Mixed_6e,并在Mixed_6e之后再接一个5x5的平均池化,步长为3,padding设为VALID,这样输出的尺寸就从17x17x768变为5x5x768。接着连接一个128输出通道的1x1卷积和一个768输出通道的5x5卷积,这里权重初始化方式重设为标准差为0.01的正态分布,padding模式设为VALID,输出尺寸变为1x1x768。然后再连接一个输出通道数为num_classes的1x1卷积,不设激活函数和规范化函数,权重初始化方式重设为标准差为0.001的正态分布,这样输出变为了1x1x1000。接下来,使用tf.squeeze函数消除输出tensor中前两个为1的维度。最后将辅助分类节点的输出aux_logits储存到字典表end_points中。
下面处理正常的分类预测的逻辑。我们直接对Mixed_7e即最后一个卷积层的输出进行一个8x8全局平均池化,padding模式为VALID,这样输出tensor的尺寸为1x1x2048。然后连接一个Dropout层,节点保留率为dropout_keep_prob。接着连接一个输出通道数为1000的1x1卷积,激活函数和规范化函数设为空。下面使用tf.squeeze去除输出tensor中维数为1的维度,再连接一个SoftMax对结果进行分类预测。最后返回输出结果logit和包含辅助节点的end_points。
至此,整个Inception V3网络的构建就完成了。Inception V3是一个非常复杂、精妙的模型,其中用到了非常多之前积累下来的设计大型卷积网络的经验和技巧。不过,虽然Inception V3论文中给出了设计卷积网络的几个原则,但是其中很多超参数的选择,包括层数、卷积核的尺寸、池化的位置、步长的大小,factorization使用的时机,以及分支的设计,都很难一一解释。目前,我们只能认为深度学习,尤其是大型卷积网络的设计,是一门实验学科,其中需要大量的探索和实践。
我们很难证明某种网络结构一定更好,更多的是通过实验积累下来的经验总结出一些结论。深度学习的研究中,理论证明部分依然是短板,便通过实验得到的结论通常也具有不错的推广性,在其他数据集上泛化性良好。
下面对Inception V3进行运算性能测试。这里使用的time_tensorflow_run函数和AlexNet那节一样,因此就不同志重复定义,读者可以在6.1节中找到代码并加载。Inception V3网络结构较大,所以依然令batch_size为32,以免GPU显存不够。图片尺寸设置为299x299,并用tf.random_uniform生成随机图片数据做为input。接着,我们使用slim.arg_scope加载前面定义好的inception_v3_arg_scope(),在这个scope中包含了Batch Normalization的默认参数,以及激活函数和参数初始化方式的默认值。然后在这个arg_scope下,调用inception_v3函数,并传入inputs,获取logits和end_points。下面创建Session并初始化全部模型参数。最后我们设置测试的batch数量为100,并使用time_tensorflow_run测试Inception V3网络的forward性能。
重新将代码重新对了一遍,发现有几个地方有小错误,详细见源码,有点小改动。
计算结果:
为篇幅原因,就不对Inception V3的backward性能进行测试了,这部分的代码比较冗长。感兴趣的,可以将整个网络的所有参数加入参数列表,测试对全部参数求导所需的时间,或者直接下载ImageNet数据集,使用真实样本进行训练并评测所需要时间。
有空再将真实数据进行验证。
Inception V3作为一个极深的卷积神经网络,拥有非常精妙的设计和构造,整个网络的结构和分支非常复杂。我们平时可能不必设计这么复杂的网络,但Inception V3中仍有许多设计CNN的思想和Trick值得借鉴。
1)Factorization into small convolutions很有效,可以降低参数量、减轻过拟合,增加网络非线性的表达能力。
2)卷积网络从输入到输出,应该让图片尺寸逐渐减少,输出通道数逐渐增加,即让空间结构简化,将空间信息转化为高阶抽象的特征信息。
3)Inception Module用多个分支提取不同抽象程序的高阶特征的思路很有效,可以丰富网络的表达能力。