用SVC模型完成对手写数字的分类
用SVC模型进行红酒分类
文章目录
- 用SVC模型进行红酒分类
- 实验说明
- 实验代码
- 参数优化
- 支持向量
实验说明
实验要求:使用SVC模型完成对手写数字的分类( load_digits),并使用评测指标 precision_score、 recall_score、f1_score 对分类结果评测。
- 实验环境:Pycharm
- Python版本:3.6
- 需要的第三方库:sklearn
实验代码
这里 SVC 模型采用的是高斯核函数 kernel=‘rbf’,惩罚系数 C=0.8。
我们采用 classification_report 来进行评价,其中就包含了 precision_score、 recall_score、f1_score 。
有关 SVC 模型的参数以及如何选择, 可以参考这篇博客 sklearn.svm.svc 参数说明
from sklearn.datasets import load_digits
from sklearn.svm import SVC
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
#加载数据集
digits=load_digits()
x=digits.data
y=digits.target
#打印数据形状
# print("x.shape:\n", x.shape)
#输出digits数据集中的特征
#print('digits.feature_names: \n',digits.feature_names)
# print('digits.target_names: \n', digits.target_names)
# 拆分数据集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2,random_state=10)
#创建svc实例
svc=SVC(C=0.8,kernel='rbf',class_weight='balanced')
svc=svc.fit(x_train,y_train)
#预测
svc_predict=svc.predict(x_test)
#评价结果
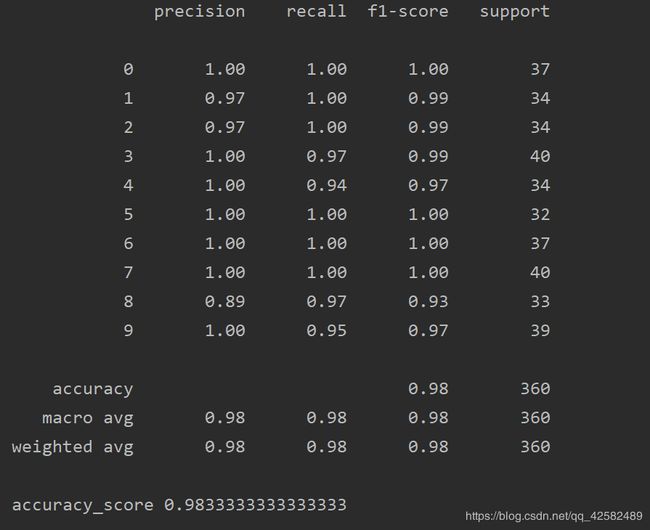
svc_metric=classification_report(y_test,svc_predict,digits.target_names)
print(svc_metric)
print("accuracy_score",accuracy_score(y_test,svc_predict))
从结果中可以看到,预测的准确率是比较高的。
参数优化
我们采用网格参数搜索的方式进行优化,核函数依然选择高斯核函数,我们针对 惩罚系数 C 和核函数系数 gamma 进行调参。
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report, accuracy_score
from sklearn.model_selection import GridSearchCV
# 加载数据集
digits = load_digits()
x = digits.data
y = digits.target
# 打印数据形状
# print("x.shape:\n", x.shape)
# 输出数据集中的特征、分类名
# print("digits.feature_names:\n", digits.feature_names)
# print("digits.target_names:\n", digits.target_names)
# print()
# 拆分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=10)
# 设置超参数
C = [0.1, 0.2, 0.5, 0.8, 0.9, 1]
kernel = 'rbf'
gamma = [0.001, 0.01, 0.1, 0.2, 0.5, 0.8]
# 参数字典
params_dict = {
'C': C,
'gamma': gamma
}
# 创建SVC实例
svc = SVC()
# 网格参数搜索
gsCV = GridSearchCV(
estimator=svc,
param_grid=params_dict,
n_jobs=2,
scoring='r2',
cv=6
)
gsCV.fit(x_train, y_train)
# 输出参数信息
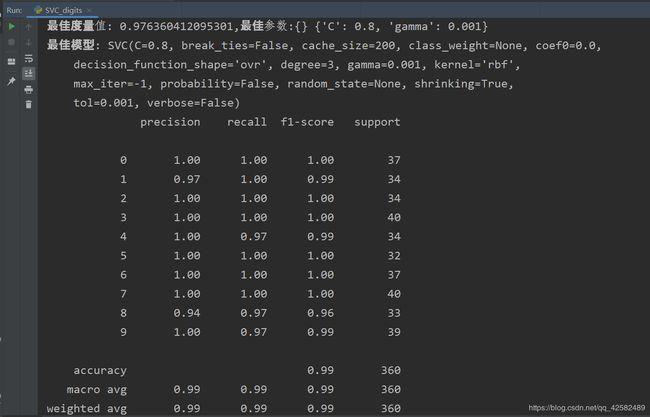
print("最佳度量值:", gsCV.best_score_, end=",")
print("最佳参数:", gsCV.best_params_)
print("最佳模型:", gsCV.best_estimator_)
# 用最佳参数生成模型
svc = SVC(C=gsCV.best_params_['C'], kernel=kernel, gamma=gsCV.best_params_['gamma'])
# 拟合训练集
svc = svc.fit(x_train, y_train)
# 预测
svc_predict = svc.predict(x_test)
# 评价结果
svc_metric = classification_report(y_test, svc_predict)
print(svc_metric)
print("accuracy_score:", accuracy_score(y_test, svc_predict))
网格参数搜索是以穷举的方式进行参数选择的,所以会比较耗时,一般只用于小数据集。
大约等待了几分钟,终于跑出了结果。从预测结果我们看出,参数调优之后准确率明显升高。
支持向量
想要查看该实验的支持向量的个数以及相应的向量,并将分类错误的数据输出。
# 查看支持向量
sum = 0
for i in range(len(svc.n_support_)):
sum += svc.n_support_[i]
print("支持向量的个数:", sum)
print("支持向量:", svc.support_vectors_)
print("分类错误的数据:")
for i in range(len(svc_predict)):
if(svc_predict[i] != y_test[i]):
print("索引:{},数值:{}".format(i, svc_predict[i]))
