最近简单地看了下python爬虫的视频。便自己尝试写了下爬虫操作,计划的是把某一个网站上的美女图全给爬下来,不过经过计算,查不多有好几百G的样子,还是算了。就首先下载一点点先看看。
本次爬虫使用的是python2.7的版本,并且本次的目标网站并没有采用js来加载图片,所以没有涉及对js脚本的解析,都是通过来分析html文件通过正则来一步步提取图片网址,然后存起来。
首先这个网站有很多分类,到美女图这个子网页,可以发现有很多页,同时每页有多个相册,每个相册点进去就会有多个页,每页有多张照片
流程大概是这样
找到所有页数
----遍历所有的页数
----遍历当前页的所有相册(给每个相册建立一个目录)
----遍历当前相册的所有图片(遍历此相册的所有页(遍历当前页的所有照片并找到图片的url))
----获得图片url就存起来
不说了,直接上代码
这个版本是windows上的运行版本
import urllib
import re
import os
import time
import socket
def get_html(url):
socket.setdefaulttimeout(10)
papg = urllib.urlopen(url)
html = papg.read()
html = unicode(html, "gbk").encode("utf8")
return html
def get_img(html):
imgre = re.compile(r') 末页')
szresult = re.findall(szurlre, html)
if len(szresult) == 0:
page_num = 0
else:
page_num = int(szresult[0])
print page_num
return page_num
def get_page_num2(html):
szurlre = re.compile(r'共(\d+)页')
szresult = re.findall(szurlre, html)
if len(szresult) == 0:
page_num = 0
else:
page_num = int(szresult[0])
print page_num
return page_num
#获得单页的相册
def get_ablum_list(html):
szurlre = re.compile(r'(http://www.5442.com/meinv/2\d+/\d+.html)" target=')
ablum_list = re.findall(szurlre, html);
return ablum_list
#获得相册的名称
def get_ablum_name(html):
szurlre = re.compile(r'
末页')
szresult = re.findall(szurlre, html)
if len(szresult) == 0:
page_num = 0
else:
page_num = int(szresult[0])
print page_num
return page_num
def get_page_num2(html):
szurlre = re.compile(r'共(\d+)页')
szresult = re.findall(szurlre, html)
if len(szresult) == 0:
page_num = 0
else:
page_num = int(szresult[0])
print page_num
return page_num
#获得单页的相册
def get_ablum_list(html):
szurlre = re.compile(r'(http://www.5442.com/meinv/2\d+/\d+.html)" target=')
ablum_list = re.findall(szurlre, html);
return ablum_list
#获得相册的名称
def get_ablum_name(html):
szurlre = re.compile(r'(\S+) ')
ablum_name = re.findall(szurlre, html)
return ablum_name[0]
#获得单页的图片
def get_photo(html, dir, photo_num):
imgre = re.compile(r'点击图片进入下一页\' >\')
运行效果截图:
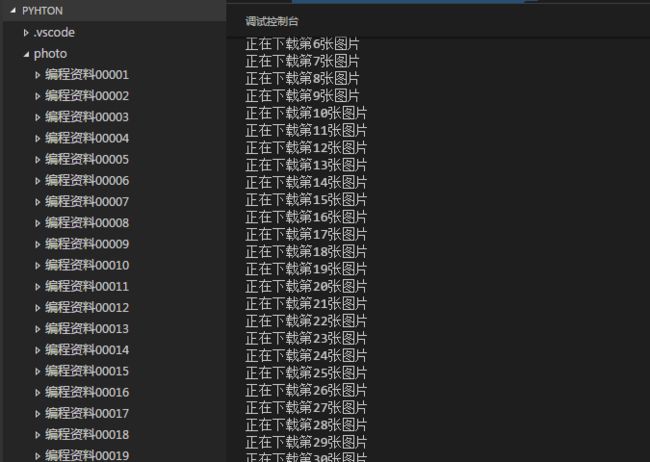
这样就运行成功了。
以下是linux下的运行代码,主要是编码和存储的路径格式不一样
#!/usr/bin/python
# -*- coding:utf8 -*-
import urllib
import re
import os
import time
import socket
def get_html(url):
socket.setdefaulttimeout(2)
papg = urllib.urlopen(url)
html = papg.read()
html = unicode(html, "gbk").encode("utf8")
return html
def get_img(html):
imgre = re.compile(r'末页')
szresult = re.findall(szurlre, html)
if len(szresult) == 0:
page_num = 0
else:
page_num = int(szresult[0])
print page_num
return page_num
def get_page_num2(html):
szurlre = re.compile(r'共(\d+)页')
szresult = re.findall(szurlre, html)
if len(szresult) == 0:
page_num = 0
else:
page_num = int(szresult[0])
print page_num
return page_num
#获得单页的相册
def get_ablum_list(html):
szurlre = re.compile(r'(http://www.5442.com/meinv/2\d+/\d+.html)" target=')
ablum_list = re.findall(szurlre, html);
return ablum_list
#获得相册的名称
def get_ablum_name(html):
szurlre = re.compile(r'(\S+) ')
ablum_name = re.findall(szurlre, html)
return ablum_name[0]
#获得单页的图片
def get_photo(html, dir, photo_num):
imgre = re.compile(r'点击图片进入下一页\' >运行效果:

保存目录
