数据分析实战
爬取网站相关职位信息的数据分析
分析背景:了解相关职位的市场需求量以及职位的发展要求,匹配该职位的地区分布, 学历要求, 经验要求, 薪资水平等,对求职人员和进入该职业的新人提供一些帮助和大致的学习方向
分析流程:
1、数据获取(爬取有关大数据职位的信息)
2、数据清洗
3、数据分析
4、数据可视化
流程图:
数据获取(python爬虫)
利用python+selenium自动化爬取网站职位信息
主要代码
from selenium import webdriver
import requests
import re
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import pymysql
import time
from fake_useragent import UserAgent
import requests.exceptions
def get_url(html):
r = '.*?class="t3">(.*?)<.*?class="t4">(.*?)<.*?class="t5">(.*?)'
list1 = re.findall(re.compile(r, re.S), html)
return list1
proxy=None
proxy_url="http://127.0.0.1:5000/get"
max_count=5
def get_proxy():
global proxy
try:
response=requests.get(proxy_url)
if response.status_code==200:
return response.text
return None
except ConnectionError:
time.sleep(20)
get_proxy()
def get_zhiwei(url):
global proxy
ua = UserAgent(path="F:\pycharm\JOB/fake_useragent_0.1.11.json")
headers = {
"User-Agent": ua.random
}
try:
if proxy:
print("使用代理中")
proxies={
"http":"http://"+proxy
}
html=requests.get(url,headers=headers,proxies=proxies)
html.encoding = html.apparent_encoding
else:
html=requests.get(url,headers=headers)
html.encoding = html.apparent_encoding
if html.status_code == 200:
r = '(.*?)
zhiwei_list = re.findall(re.compile(r, re.S), html.text)
if zhiwei_list:
return zhiwei_list
else:
return ["null"]
else :
proxy=get_proxy()
if proxy:
print("使用代理",proxy)
get_zhiwei(url)
else:
return ['null']
except ConnectionError:
time.sleep(10)
return ['null']
def ord_zhiwei(url):
ua = UserAgent(path="F:\pycharm\JOB/fake_useragent_0.1.11.json")
headers = {
"User-Agent": ua.random
}
try:
html = requests.get(url, headers=headers)
html.encoding = html.apparent_encoding
r = '(.*?)
zhiwei_list = re.findall(re.compile(r, re.S), html.text)
if zhiwei_list:
return zhiwei_list
else:
return ["null"]
except requests.exceptions as e:
print(e.response)
def save_sql(list1):
connect = pymysql.connect("localhost", "root", "123456", "zhiwei", charset='utf8')
cursor = connect.cursor()
sql1 = """CREATE TABLE IF NOT EXISTS job_2(
name varchar(100),
web varchar(100),
city varchar(20),
salary varchar(20),
date varchar(20),
job_description varchar(10000))CHARSET=utf8"""
sql2 = """INSERT INTO job_2(name,web,city,salary,date,job_description) VALUES(%s,%s,%s,%s,%s,%s)"""
try:
cursor.execute(sql1)
cursor.executemany(sql2, list1)
connect.commit()
except:
connect.rollback()
connect.close()
def etl_data(str):
str = str.replace("\r","").replace("\n","").replace("\t","").replace(""
,"") \
.replace("","").replace("","").replace("","").replace("
","") \
.replace("
","").replace(" ","").replace("","").replace("","") \
.replace("","").replace("","").replace(""
,"").replace("","") \
.replace(''
,"").replace("","").replace("","") \
.replace("","").replace("","")
return str
def main():
brown = webdriver.Chrome()
brown.get("https://mkt.51job.com/tg/sem/pz_2018.html?from=baidupz")
input = brown.find_element_by_id("kwdselectid")
input.send_keys("大数据")
input.send_keys(Keys.ENTER)
for i in range(0, 1000):
list1 = get_url(brown.page_source)
n = 0
for i in list1:
list1[n] = list(list1[n])
try:
list1[n].append(etl_data(ord_zhiwei(i[1])[0]))
except:
list1[n].append("null")
n = n + 1
save_sql(list1)
click = brown.find_element_by_xpath('//*[@id="resultList"]/div[55]/div/div/div/ul/li[8]/a')
ActionChains(brown).click(click).perform()
time.sleep(3)
print("爬取完毕")
if __name__ == "__main__":
main()
为了防止被封ip,利用redis和GitHub上的一个开源项目(ProxyPool-master)维护了一个动态的代理池
数据迁徙
Sqoop将数据从mysql迁移到hdfs和hive中
// An highlighted block
sqoop import
--connect jdbc:mysql://210.45.137.29:3306/job
--username root
--password ethink2018
--table job_2
--target-dir /user/job
--delete-target-dir
--fields-terminated-by '%' --m 1;
hive中:
create table if not exists job(
name varchar(100),
web varchar(100),
city varchar(20),
salary varchar(20),
date varchar(20),
job_description varchar(10000)
)row format delimited fields terminated by "%";
load data inpath "/user/job" into table job.job;
到此mysql,hdfs,hive中度都具有原始数据啦
数据清洗
采用了Mapreduce来离线批处理数据
数据清洗目的:剔除冗余数据,脏数据,数据空值处理,规整,对部分数据重构成新的变量
Jobetl.jar
//job.class
import java.io.IOException;
import java.io.PrintStream;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Jobetl
{
public static class TokenizerMapper
extends Mapper<Object, Text, Text, NullWritable>
{
private Text k = new Text();
public void map(Object key, Text value, Mapper<Object, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException
{
String str = value.toString();
String values = etldata.etldata(str);
if (StringUtils.isBlank(values)) {
return;
}
this.k.set(values);
context.write(this.k, NullWritable.get());
}
}
public static void main(String[] args)
throws Exception
{
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2)
{
System.err.println("Usage: wordcount [...] " );
System.exit(2);
}
Job job = Job.getInstance(conf, "Job");
job.setJarByClass(Jobetl.class);
job.setMapperClass(Jobetl.TokenizerMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
for (int i = 0; i < otherArgs.length - 1; i++) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[(otherArgs.length - 1)]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
//etl.class
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import org.apache.commons.lang.StringUtils;
public class etldata
{
public static String etldata(String str)
{
String[] newstr = str.split("%");
StringBuffer sb = new StringBuffer();
sb.append(newstr[0]).append("%");
if ((newstr[1].toString().indexOf("销售") != -1) || (newstr[1].toString().indexOf("链家") != -1) || (newstr[1].toString().indexOf("客服") != -1) || (newstr[1].toString().indexOf("麻辣烫") != -1)) {
return null;
}
sb.append(newstr[1]).append("%");
sb.append(newstr[2]).append("%");
String technology = "";
String newcity = "";
float minsalary = 0.0F;
float maxsalary = 0.0F;
if (newstr[3].equals("")) {
return null;
}
Pattern p2 = Pattern.compile("[\\u4e00-\\u9fa5]+");
Matcher m2 = p2.matcher(newstr[3]);
if (m2.find())
{
newcity = m2.group(0);
sb.append(newcity).append("%");
}
if (newstr[4].equals("")) {
return null;
}
Pattern p3 = Pattern.compile("(.*?)-(.*?)([\\u4e00-\\u9fa5])/([\\u4e00-\\u9fa5])");
Matcher m3 = p3.matcher(newstr[4]);
if (m3.matches())
{
if (m3.group(3).equals("万"))
{
if (m3.group(4).equals("月"))
{
minsalary = Float.parseFloat(m3.group(1));
maxsalary = Float.parseFloat(m3.group(2));
}
else if (m3.group(4).equals("年"))
{
minsalary = Float.parseFloat(m3.group(1)) / 12.0F;
maxsalary = Float.parseFloat(m3.group(2)) / 12.0F;
}
}
else if (m3.group(3).equals("千")) {
if (m3.group(4).equals("月"))
{
minsalary = Float.parseFloat(m3.group(1)) / 10.0F;
maxsalary = Float.parseFloat(m3.group(2)) / 10.0F;
}
else if (m3.group(4).equals("天"))
{
minsalary = Float.parseFloat(m3.group(1)) * 10.0F;
maxsalary = Float.parseFloat(m3.group(2)) * 10.0F;
}
}
}
else {
return null;
}
sb.append(newstr[4]).append("%");
sb.append(minsalary).append("%");
sb.append(maxsalary).append("%");
sb.append(newstr[5]).append("%");
if (newstr[6].equals("null")) {
return null;
}
if ((newstr[6].toString().indexOf("链家") != -1) || (newstr[6].toString().indexOf("贝壳") != -1)) {
return null;
}
newstr[6] = newstr[6].replaceAll("" , "").replaceAll("", "").replaceAll("
", "").replaceAll("", "").replaceAll("STRONG", "").replaceAll(""
, "")
.replaceAll(""
, "").replaceAll(".com", "").replaceAll(" ", "").replaceAll("http", "").replace("QQ", "").replaceAll("", "").replaceAll("", "")
.replaceAll("", "").replaceAll("", "").replaceAll("", "").replaceAll("", "").replaceAll("", "").replaceAll("", "")
.replaceAll("", "").replaceAll("", "").replaceAll("", "").replaceAll("", "").replaceAll("", "").replaceAll("", "")
.replaceAll("", "").replaceAll("", "").replaceAll("", "").replaceAll("\t", "").replaceAll("\r", "").replaceAll("\n", "").replaceAll("#", "").replaceAll("", "")
.replaceAll("" , "");
Pattern p = Pattern.compile("[a-zA-z]+");
Matcher m = p.matcher(newstr[6]);
List<String> codeList = new ArrayList();
while (m.find()) {
codeList.add(m.group(0));
}
HashSet h = new HashSet(codeList);
codeList.clear();
codeList.addAll(h);
if (codeList.size() < 50) {
technology = StringUtils.join(codeList.toArray(), "#");
} else {
return null;
}
sb.append(technology).append("%");
sb.append(newstr[6]);
return sb.toString();
}
}
数据分析与数据可视化
由于数据量过大,抽取hive中的一部分数据导出成TXT文件来进行分析
分析需求(可以直接编写sql实现该功能,这里采用python进行数据分析):
分析的需求:
1)不同城市的max_salary,avg_salary,min_salary
2)不同城市的岗位需求
3)职位的岗位技能排序
4)随着时间的变化,各个职位的职位数和薪资变化
5)不同岗位的技能需求排行
import pandas as pd
import re
#读取数据
data=pd.read_table(r"E:\job.txt",encoding='utf-8',header=None,error_bad_lines=False)
data.drop(0,axis=1,inplace=True)
#数据预处理
data=data.rename(columns={1:"name",2:"web",3:"city",4:"salary",5:"minsalary",6:"maxsalary",7:"date",8:"technology",9:"job_description"})
//对空缺的工作城市,填补为该网站的所在城市
data['city_pinying']=data['web'].map(lambda x: re.findall("[a-zA-Z]+",x)[4])
dict1=dict(zip(data['city'],data['city_pinying']))
listkey=[]
dict2={}
for i,j in dict1.items():
if i not in listkey:
dict2[i]=j
listkey.append(i)
for i in range(len(data)):
if data.loc[i,"city"]=="异地招聘":
str1=data.loc[i,"city_pinying"]
city_name=[k for k, v in dict2.items() if v == str1]
if len(city_name)>0:
data.loc[i,"city"]=city_name[0]
else:
pass
data.drop("city_pinying",axis=1,inplace=True)
data['avg_salary']=(data['minsalary']+data['maxsalary'])/2.0
import datetime
now_time = datetime.datetime.now()
data['date']=data['date'].map(lambda x : str(now_time.year)+"-"+x)
data["technology"]=data["technology"].map(lambda x: x.upper().replace("[","").replace("]","").replace('"',"").split(","))
data['name']=data['name'].map(lambda x: x.replace("(","(").replace(")",")")).map(lambda x: re.sub("(\([^\)]*\))","",x))
str_city="黑龙江(哈尔滨)、吉林(长春)、辽宁(沈阳)、内蒙古自治区(呼和浩特)、北京(北京)、天津(天津)、河北(石家庄)、山东(济南)、山西(太原)、陕西(西安)、甘肃(兰州)、新疆维吾尔自治区(乌鲁木齐)、青海(西宁)、西藏自治区(拉萨)、四川(成都)、河南(郑州)、江苏(南京)、安徽(合肥)、湖北(武汉)、重庆(重庆)、贵州(贵阳)、湖南(长沙)、江西(南昌)、上海(上海)、浙江(杭州)、福建(福州)、云南(昆明)、广西壮族自治区(南宁)、广东(广州)、海南(海口)、香港特别行政区(香港)、澳门特别行政区(澳门)、台湾(台北)、宁夏(银川"
str_city=str_city.replace("("," ").replace(")"," ").replace("、","").split(" ")
str_city1=[str_city[i]+"省" for i in range(len(str_city)) if i%2==0]
str_city2=[str_city[i] for i in range(len(str_city)) if i%2!=0]
dict_city={str_city1[i]:str_city2[i] for i in range(len(str_city1))}
for i in data[data['city'].str.contains(".*?省")]['city'].index:
data.loc[i,"city"]=[v for k,v in dict_city.items() if k==data.loc[i,"city"]][0]
data['month']=data["date"].map(lambda x : re.findall("-(.*?)-",x)[0])
利用python中的第三方工具包pyecharts进行数据可视化,可以保存为html动态图,方便存储和查看
from pyecharts.charts import Page ,Line,Geo
from pyecharts import options as opts
from example.commons import Faker
from pyecharts.charts import Line
//可视化预处理
first_list=data['city'].value_counts()[data['city'].value_counts()>100].index
newlist2=data.groupby("city").mean().loc[first_list]
city2=newlist2.index
minsalary=data.groupby("city").min().loc[first_list]["minsalary"].values
maxsalary=data.groupby("city").max().loc[first_list]["maxsalary"].values
avg_salary=data.groupby("city").mean().loc[first_list]["avg_salary"].values
newlist=data['city'].value_counts()
city3=newlist.index.tolist()
num=newlist.values.tolist()
#
geo=Geo()
value=[]
for i in [list(z) for z in zip(city3, num)]:
r=geo.get_coordinate(i[0])
if r:
value.append(i)
date=data.groupby("date").mean()["avg_salary"].index
date_avg_salary=data.groupby("date").mean()["avg_salary"].values
date_count=data.groupby("date").count()['name'].values
a=[j for i in range(len(data)) for j in data.loc[i,"technology"] if len(j)>0]
#词频统计
from collections import Counter
v_t=Counter(a).most_common(30)
v_t1=[i[0] for i in v_t]
change=data['name'].value_counts()
t_name=change[change.values>100].index.tolist()
from collections import Counter
k=[]
for name in t_name:
v=Counter([j for i in data[data['name']==name]['technology'].values for j in i]).most_common(60)
v=[list(i) for i in v]
v=[i for i in v if i[0] in v_t1]
for i in v:
i.insert(0,name)
k.append(v)
value_technology=[j for i in k for j in i]
v=Counter([j for i in data[data['name']==name]['technology'].values for j in i]).most_common(30)
def line_markpoint() -> Line:
c = (Line().add_xaxis(list(city2)) \
.add_yaxis("max_salary",maxsalary)
) \
.add_yaxis("avg_salary",avg_salary)\
.add_yaxis("min_salary",minsalary) \
.set_global_opts(title_opts=opts.TitleOpts(title="薪水折线图"),
datazoom_opts=[opts.DataZoomOpts(),opts.DataZoomOpts(type_="inside")]) \
.set_series_opts(is_symbol_show =True,is_smooth=True,
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")]),
label_opts=opts.LabelOpts(is_show=False)
)
return c
def geo_base() -> Geo:
c = (
Geo()
.add_schema(maptype="china")
.add("JOB_NUM",value)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
visualmap_opts=opts.VisualMapOpts(min_=0,max_=6000,range_color=Faker.visual_color),
title_opts=opts.TitleOpts(title="JOB-NUM")))
return c
def pie_scroll_legend() -> Pie:
c = (
Pie()
.add(
"",
v_t,
center=["40%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="technology"),
legend_opts=opts.LegendOpts(
type_="scroll", pos_left="80%", orient="vertical"
),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
return c
def bar3d_base() -> Bar3D:
c = (
Bar3D()
.add(
"",
value_technology,
xaxis3d_opts=opts.Axis3DOpts(type_="category"),
yaxis3d_opts=opts.Axis3DOpts(type_="category"),
zaxis3d_opts=opts.Axis3DOpts(type_="value"),
)
.set_global_opts(
visualmap_opts=opts.VisualMapOpts(max_=1200),
title_opts=opts.TitleOpts(title="职位技能图"),
)
)
return c
def grid_mutil_yaxis() -> Grid:
bar = (
Bar()
.add_xaxis(list(date))
.add_yaxis(
"职位数",
date_count.tolist(),
yaxis_index=0,
color="#5793f3",
)
.extend_axis(
yaxis=opts.AxisOpts(
name="职位数",
type_="value",
min_=0,
max_=20000,
position="right",
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color="#675bba")
),
axislabel_opts=opts.LabelOpts(formatter="{value} 个"),
)
)
.extend_axis(
yaxis=opts.AxisOpts(
type_="value",
name="平均薪资",
min_=0,
max_=3,
position="left",
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color="#d14a61")
),
axislabel_opts=opts.LabelOpts(formatter="{value}万/月"),
split_number=3
)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="时间变化图"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"),
datazoom_opts=[opts.DataZoomOpts(),opts.DataZoomOpts(type_="inside")]
)
)
line = (
Line()
.add_xaxis(list(date))
.add_yaxis(
"平均薪水",
date_avg_salary.tolist(),
yaxis_index=2,
color="#675bba",
label_opts=opts.LabelOpts(is_show=False),
)
)
bar.overlap(line)
return Grid().add(
bar, opts.GridOpts(pos_left="5%", pos_right="20%"), is_control_axis_index=True
)
page = Page(layout=Page.SimplePageLayout)
page.add(line_markpoint(), geo_base(),pie_scroll_legend(), grid_mutil_yaxis(),bar3d_base())
page.render("可视化.html")
##分析与可视化结果
本次爬取网站将近两个月的数据进行分析
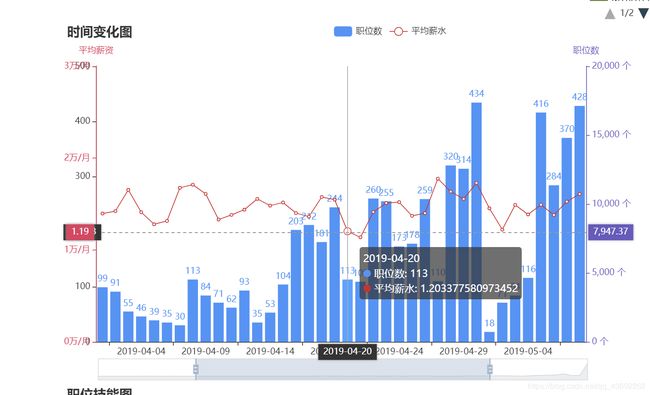
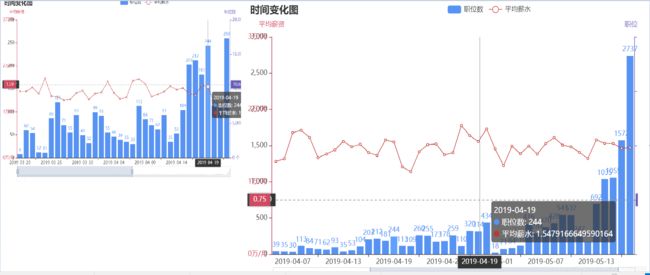
1)职位的数量大致趋势时有所增长的,市场对于大数据人才的需求在逐步增加,这类职业正处于快速发展阶段,工作岗位较多
2)在1-3年经验中该职位的平均薪水处于1万~2万的区间,属于较高薪资的职位
3)3,4月的职位数量每天稳定增长,未有较大变动,4月末到5月的职位数量增加,可能与该季节处于年后一个多月的时间,员工大量离职,造成职位空缺,企业放出大量的职位需求
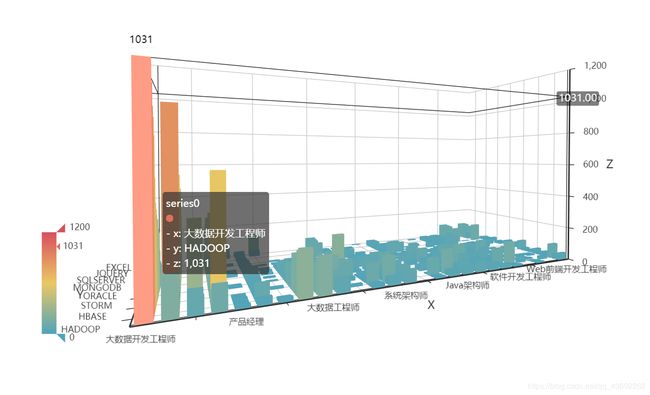
1)在大数据领域,市场中大数据开发工程师这一职位遥遥领先,有一千多的岗位欠缺,其次需求较多的为大数据工程师,产品经理,数据分析师,Java高级开发工程师,大数据架构师,算法工程师等职位(在上图中没有显示),可以看到,复合型交叉人才在人才市场是较为受欢迎的
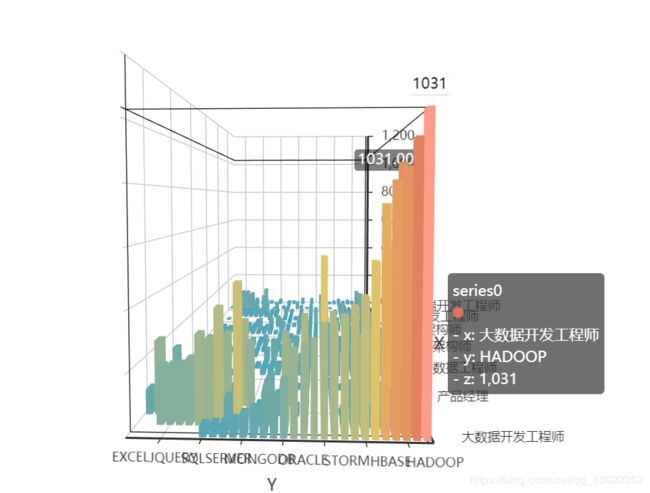
2)其中大数据需求工程师必备技能中hadoop,spark,java,hive需求较多,
其中在岗位中数据库也是求职人员所必须的技能

1)而可以看出上海所提供的职位最多,达到5000多个职位需求
2)主要工作地点遍布在一线城市和新一线城市
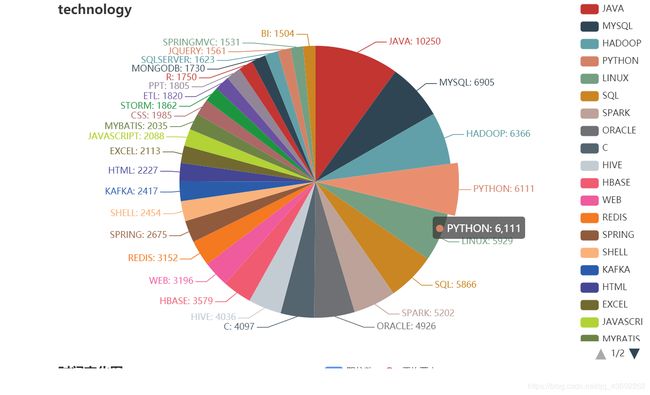
1)java等老牌语言的需求量居高不下,新生语言python等后来居上,
2)数据库基本成为互联网求职人员的必须技能,其中已MySQL,sql,oracle等为主要需求
3)大数据岗位主要技能需求为Hadoop,spark,hive,hbase等
4)其中Linux系统为主要开发环境